</noscript><div id="__next"><header class="header_headerContainer__cnwRR"><div class="page_container__IibMw header_desktopHeaderWrapper__HEBG_"><a title="Zilliz logo" class="header_logoWrapper__0doBt" href="/"><svg width="97" height="40" viewBox="0 0 97 40" fill="none" xmlns="http://www.w3.org/2000/svg"><g clip-path="url(#clip0_4874_3768)"><rect width="97" height="40" fill="transparent"></rect><path fill-rule="evenodd" clip-rule="evenodd" d="M18.6541 27.0547V39.7949H21.1413V24.5393L27.7546 35.9938C28.503 35.6278 29.2221 35.2111 29.9074 34.7483L22.6675 22.2084L30.641 25.1105C31.0007 24.3705 31.2862 23.5877 31.4879 22.7719L27.007 21.141H39.7949V18.6538H24.5381L35.9936 12.04C35.6276 11.2916 35.2109 10.5725 34.748 9.8872L22.2832 17.0838L25.1605 9.1786C24.4221 8.81536 23.6406 8.52618 22.8259 8.32075L21.1413 12.9492V0H18.6541V15.257L12.04 3.80101C11.2916 4.16702 10.5725 4.58369 9.88716 5.04654L17.0968 17.534L9.17163 14.6495C8.80943 15.3884 8.52133 16.1702 8.31702 16.9852L12.9015 18.6538H1.08717e-07L0 21.141H15.2559L3.80081 27.7546C4.16682 28.503 4.58348 29.2221 5.04633 29.9074L17.6089 22.6545L14.6995 30.6478C15.44 31.0066 16.2231 31.291 17.0392 31.4915L18.6541 27.0547Z" fill="url(#desktop-logo)"></path><rect x="46.0625" y="12.4359" width="11.3415" height="2.48718" fill="#000"></rect><rect x="85.3599" y="12.4359" width="11.3415" height="2.48718" fill="#000"></rect><rect x="67.0542" y="6.66563" width="2.68615" height="20.6933" fill="#000"></rect><rect x="61.085" y="12.4359" width="2.68615" height="14.9231" fill="#000"></rect><rect width="2.68615" height="2.68615" transform="matrix(1 0 0 -1 61.085 9.35179)" fill="#000"></rect><rect x="45.7642" y="24.8718" width="11.9385" height="2.48718" fill="#000"></rect><path d="M45.7642 24.8718L54.2216 14.9231L57.4042 14.9231L48.9467 24.8718L45.7642 24.8718Z" fill="#000"></path><path d="M85.0615 24.8718L93.519 14.9231L96.7015 14.9231L88.2441 24.8718L85.0615 24.8718Z" fill="#000"></path><rect x="73.0234" y="6.66563" width="2.68615" height="20.6933" fill="#000"></rect><rect x="85.0615" y="24.8718" width="11.9385" height="2.48718" fill="#000"></rect><rect x="78.9927" y="12.4359" width="2.68615" height="14.9231" fill="#000"></rect><rect width="2.68615" height="2.68615" transform="matrix(1 0 0 -1 78.9927 9.35179)" fill="#000"></rect></g><defs><linearGradient id="desktop-logo" x1="8.45641" y1="4.2282" x2="29.0503" y2="37.6061" gradientUnits="userSpaceOnUse"><stop stop-color="#9D41FF"></stop><stop offset="0.468794" stop-color="#2858FF"></stop><stop offset="0.770884" stop-color="#29B8FF"></stop><stop offset="1" stop-color="#00F0FF"></stop></linearGradient><clipPath id="clip0_4874_3768"><rect width="97" height="40" fill="white"></rect></clipPath></defs></svg></a><div class="header_rightSection__wt8UV"><ul class="header_navsWrapper__bq2UF"><li class="header_menuItem__mBXHj">Products<svg width="13" height="12" viewBox="0 0 13 12" fill="none" xmlns="http://www.w3.org/2000/svg" class="header_verticalArrow__q0f2B"><path d="M2.5 4L6.5 8L10.5 4" stroke="#475467" stroke-width="2"></path></svg><div class="header_menuTransitionWrapper__eM91e" style="width:0px"><div class="header_subMenuWrapper__wGcsK"><div class="header_partWrapper__wFjH4 header_leftPart__PjZlt"><div class="header_cloudsContainer__inoV3"><div class=""><a class="header_cloudWrapper__MZqZI" href="/cloud"><svg width="40" height="40" viewBox="0 0 40 40" fill="none" xmlns="http://www.w3.org/2000/svg"><g clip-path="url(#clip0_4566_5716)"><path fill-rule="evenodd" clip-rule="evenodd" d="M40 19.8776C40 27.5419 33.7868 33.7551 26.1224 33.7551C26.1224 33.7551 26.1223 33.7551 26.1222 33.7551V33.7552H9.84091C9.82593 33.7553 9.81094 33.7553 9.79593 33.7553C4.38579 33.7553 0 29.3695 0 23.9594C0 18.5492 4.38579 14.1634 9.79593 14.1634C10.9977 14.1634 12.1489 14.3798 13.2127 14.7758C15.2456 9.63583 20.2594 6 26.1224 6C33.7868 6 40 12.2132 40 19.8776Z" fill="url(#paint0_linear_4566_5716)"></path></g><defs><linearGradient id="paint0_linear_4566_5716" x1="43.5833" y1="3.43409" x2="-7.67604" y2="6.91206" gradientUnits="userSpaceOnUse"><stop stop-color="#3542B7"></stop><stop offset="1" stop-color="#00CFDE"></stop></linearGradient><clipPath id="clip0_4566_5716"><rect width="40" height="40" fill="white"></rect></clipPath></defs></svg><p class="header_cloudName__FKCnE">Zilliz Cloud<svg width="16" height="17" viewBox="0 0 16 17" fill="none" xmlns="http://www.w3.org/2000/svg"><path d="M10.7817 8.15636L7.20566 4.58036L8.14833 3.6377L13.3337 8.82303L8.14833 14.0084L7.20566 13.0657L10.7817 9.4897H2.66699V8.15636H10.7817Z" fill="black"></path></svg></p><p class="header_description__PJAok">Fully-managed vector database service designed for speed, scale and high performance.</p></a><a class="header_zillizVsMilvus__xq9eR" href="/zilliz-vs-milvus">Zilliz Cloud vs. Milvus<svg width="16" height="17" viewBox="0 0 16 17" fill="none" xmlns="http://www.w3.org/2000/svg"><path d="M10.7817 8.15636L7.20566 4.58036L8.14833 3.6377L13.3337 8.82303L8.14833 14.0084L7.20566 13.0657L10.7817 9.4897H2.66699V8.15636H10.7817Z" fill="black"></path></svg></a></div><a class="header_cloudWrapper__MZqZI" href="/what-is-milvus"><svg width="40" height="40" viewBox="0 0 40 40" fill="none" xmlns="http://www.w3.org/2000/svg"><path d="M27.4365 11.5932C22.6628 6.80225 14.922 6.80225 10.1483 11.5932L2.34592 19.4238C1.88469 19.8871 1.88469 20.6333 2.34592 21.0967L10.1483 28.9272C14.922 33.7182 22.6628 33.7182 27.4365 28.935C32.2179 24.1519 32.2179 16.3842 27.4365 11.5932ZM25.5916 26.6338C22.0863 30.1524 16.3979 30.1524 12.8926 26.6338L7.15033 20.8768C6.8121 20.539 6.8121 19.9893 7.15033 19.6437L12.8849 13.8945C16.3902 10.3759 22.0786 10.3759 25.5839 13.8945C29.0969 17.4131 29.0969 23.1152 25.5916 26.6338Z" fill="#00B3FF"></path><path d="M37.6599 19.4316L34.2238 15.9208C34.0162 15.7088 33.6703 15.9051 33.7395 16.1957C34.3314 18.8739 34.3314 21.67 33.7395 24.3482C33.678 24.6388 34.0239 24.8273 34.2238 24.6231L37.6599 21.1124C38.1134 20.6411 38.1134 19.895 37.6599 19.4316Z" fill="#00B3FF"></path><path d="M19.2802 26.4217C22.6044 26.4217 25.2992 23.6684 25.2992 20.272C25.2992 16.8756 22.6044 14.1222 19.2802 14.1222C15.956 14.1222 13.2612 16.8756 13.2612 20.272C13.2612 23.6684 15.956 26.4217 19.2802 26.4217Z" fill="#00B3FF"></path></svg><p class="header_cloudName__FKCnE">Milvus<svg width="16" height="17" viewBox="0 0 16 17" fill="none" xmlns="http://www.w3.org/2000/svg"><path d="M10.7817 8.15636L7.20566 4.58036L8.14833 3.6377L13.3337 8.82303L8.14833 14.0084L7.20566 13.0657L10.7817 9.4897H2.66699V8.15636H10.7817Z" fill="black"></path></svg></p><p class="header_description__PJAok">Open-source vector database built for billion-scale vector similarity search.</p></a></div></div><ul class="header_partWrapper__wFjH4 header_midPart__DU60V"><li class=""><a class="header_linkTitle__rhULA" href="/bring-your-own-cloud">BYOC</a></li><li class=""><a class="header_linkTitle__rhULA" href="/zilliz-migration-service">Migration</a></li><li class=""><a rel="noopener noreferrer" target="_blank" class="header_linkTitle__rhULA" href="/vector-database-benchmark-tool">Benchmark</a></li><li class=""><a class="header_linkTitle__rhULA" href="/product/integrations">Integrations</a></li><li class=""><a class="header_linkTitle__rhULA" href="/product/open-source-vector-database">Open Source</a></li><li class=""><a rel="noopener noreferrer" target="_blank" class="header_linkTitle__rhULA" href="https://support.zilliz.com/hc/en-us">Support Portal</a></li></ul><div class="header_partWrapper__wFjH4 header_rightPart__mJ5rk"><div class="header_imgWrapper__acXaO" style="background-image:url(https://assets.zilliz.com/medium_serverless_page_cover_d8d3872318.png)"></div><a class="header_linkTitle__rhULA" href="/serverless">High-Performance Vector Database Made Serverless.</a></div></div></div></li><li class="header_menuItem__mBXHj">Pricing<svg width="13" height="12" viewBox="0 0 13 12" fill="none" xmlns="http://www.w3.org/2000/svg" class="header_verticalArrow__q0f2B"><path d="M2.5 4L6.5 8L10.5 4" stroke="#475467" stroke-width="2"></path></svg><div class="header_menuTransitionWrapper__eM91e" style="width:0px"><div class="header_subMenuWrapper__wGcsK"><ul class="header_partWrapper__wFjH4 header_midPart__DU60V"><li class=""><a class="header_linkTitle__rhULA" href="/pricing">Pricing Plan<span class="header_linkTip__MOCQ1">Flexible pricing options for every team on any budget</span></a></li><li class=""><a class="header_linkTitle__rhULA" href="/pricing#calculator">Calculator<span class="header_linkTip__MOCQ1">Estimate your cost</span></a></li></ul><div class="header_partWrapper__wFjH4 header_rightPart__mJ5rk"><div class="header_imgWrapper__acXaO" style="background-image:url(https://assets.zilliz.com/medium_success_b_6ae4050db7.png)"></div><a class="header_linkTitle__rhULA" href="/zilliz-cloud-free-tier">Free Tier</a></div></div></div></li><li class="header_menuItem__mBXHj">Developers<svg width="13" height="12" viewBox="0 0 13 12" fill="none" xmlns="http://www.w3.org/2000/svg" class="header_verticalArrow__q0f2B"><path d="M2.5 4L6.5 8L10.5 4" stroke="#475467" stroke-width="2"></path></svg><div class="header_menuTransitionWrapper__eM91e" style="width:0px"><div class="header_subMenuWrapper__wGcsK"><div class="header_partWrapper__wFjH4 header_leftPart__PjZlt"><a rel="noopener noreferrer" target="_blank" class="header_documentContainer__BAe5n" href="https://docs.zilliz.com/docs/home"><svg width="50" height="50" viewBox="0 0 50 50" fill="none" xmlns="http://www.w3.org/2000/svg" class="header_docIcon__xGEVK"><path d="M22.6667 38.6667H4C1.79087 38.6667 0 36.8759 0 34.6667V13.3333C0 12.597 0.59696 12 1.33333 12H20C20.7364 12 21.3333 12.597 21.3333 13.3333V29.3333H26.6667V34.6667C26.6667 36.8759 24.8759 38.6667 22.6667 38.6667ZM21.3333 32V34.6667C21.3333 35.4031 21.9303 36 22.6667 36C23.4031 36 24 35.4031 24 34.6667V32H21.3333ZM18.6667 36V14.6667H2.66667V34.6667C2.66667 35.4031 3.26363 36 4 36H18.6667ZM5.33333 18.6667H16V21.3333H5.33333V18.6667ZM5.33333 24H16V26.6667H5.33333V24ZM5.33333 29.3333H12V32H5.33333V29.3333Z" fill="black"></path></svg><p class="header_title__UKGc7">Documentation</p><p class="header_description__PJAok">The Zilliz Cloud Developer Hub where you can find all the information to work with Zilliz Cloud</p><p class="header_linkBtn__MlnDS">Learn More<svg width="16" height="17" viewBox="0 0 16 17" fill="none" xmlns="http://www.w3.org/2000/svg"><path d="M10.7817 8.15636L7.20566 4.58036L8.14833 3.6377L13.3337 8.82303L8.14833 14.0084L7.20566 13.0657L10.7817 9.4897H2.66699V8.15636H10.7817Z" fill="black"></path></svg></p></a></div><ul class="header_partWrapper__wFjH4 header_midPart__DU60V"><li class=""><a class="header_linkTitle__rhULA" href="/learn">Learn</a></li><li class=""><a class="header_linkTitle__rhULA" href="/learn/generative-ai">GenAI Resource Hub</a></li><li class=""><a class="header_linkTitle__rhULA" href="/learn/milvus-notebooks">Notebooks</a></li><li class=""><a class="header_linkTitle__rhULA" href="/ai-models">AI Models</a></li><li class=""><a class="header_linkTitle__rhULA" href="/community">Community</a></li><li class=""><a class="header_linkTitle__rhULA" href="/milvus-downloads">Download Milvus</a></li></ul><div class="header_partWrapper__wFjH4 header_rightPart__mJ5rk"><div class="header_imgWrapper__acXaO" style="background-image:url(https://assets.zilliz.com/medium_office_hours_ed5a5d384c.png)"></div><a rel="noopener noreferrer" target="_blank" class="header_linkTitle__rhULA" href="https://discord.com/invite/8uyFbECzPX">Join the Milvus Discord Community</a></div></div></div></li><li class="header_menuItem__mBXHj">Resources<svg width="13" height="12" viewBox="0 0 13 12" fill="none" xmlns="http://www.w3.org/2000/svg" class="header_verticalArrow__q0f2B"><path d="M2.5 4L6.5 8L10.5 4" stroke="#475467" stroke-width="2"></path></svg><div class="header_menuTransitionWrapper__eM91e" style="width:0px"><div class="header_subMenuWrapper__wGcsK"><ul class="header_partWrapper__wFjH4 header_midPart__DU60V"><li class=""><a class="header_linkTitle__rhULA" href="/blog">Blog</a></li><li class=""><a class="header_linkTitle__rhULA" href="/resources?tag=5">Guides</a></li><li class=""><a class="header_linkTitle__rhULA" href="/resources?tag=1">Research</a></li><li class=""><a class="header_linkTitle__rhULA" href="/resources?tag=4">Analyst Reports</a></li><li class=""><a class="header_linkTitle__rhULA" href="/resources?tag=2">Webinars</a></li><li class=""><a class="header_linkTitle__rhULA" href="/resources?tag=3">Trainings</a></li><li class=""><a class="header_linkTitle__rhULA" href="/resources?tag=6">Podcasts</a></li><li class=""><a class="header_linkTitle__rhULA" href="/event">Events</a></li><li class=""><a class="header_linkTitle__rhULA" href="/trust-center">Trust Center</a></li></ul><div class="header_partWrapper__wFjH4 header_rightPart__mJ5rk"><div class="header_imgWrapper__acXaO" style="background-image:url(https://assets.zilliz.com/thumbnail_5fde5817_93e0_4b5f_a63b_4ba02cb51b99_d3d836e307.png)"></div><a class="header_linkTitle__rhULA" href="/resources/guide/definitive-guide-choosing-vector-database">Definitive Guide to Choosing a Vector Database </a></div></div></div></li><li class="header_menuItem__mBXHj">Customers<svg width="13" height="12" viewBox="0 0 13 12" fill="none" xmlns="http://www.w3.org/2000/svg" class="header_verticalArrow__q0f2B"><path d="M2.5 4L6.5 8L10.5 4" stroke="#475467" stroke-width="2"></path></svg><div class="header_menuTransitionWrapper__eM91e" style="width:0px"><div class="header_subMenuWrapper__wGcsK"><div class="header_partWrapper__wFjH4 header_leftPart__PjZlt"><div class="header_solutionsContainer__iViF3"><span class="header_title__UKGc7">By Use Case</span><a class="header_linkTitle__rhULA" href="/vector-database-use-cases/llm-retrieval-augmented-generation">Retrieval Augmented Generation</a><a class="header_linkBtn__MlnDS" href="/vector-database-use-cases">View all use cases<svg width="16" height="17" viewBox="0 0 16 17" fill="none" xmlns="http://www.w3.org/2000/svg"><path d="M10.7817 8.15636L7.20566 4.58036L8.14833 3.6377L13.3337 8.82303L8.14833 14.0084L7.20566 13.0657L10.7817 9.4897H2.66699V8.15636H10.7817Z" fill="black"></path></svg></a><a class="header_linkBtn__MlnDS" href="/industry">View by industry<svg width="16" height="17" viewBox="0 0 16 17" fill="none" xmlns="http://www.w3.org/2000/svg"><path d="M10.7817 8.15636L7.20566 4.58036L8.14833 3.6377L13.3337 8.82303L8.14833 14.0084L7.20566 13.0657L10.7817 9.4897H2.66699V8.15636H10.7817Z" fill="black"></path></svg></a><a class="header_linkBtn__MlnDS" href="/customers">View all customer stories<svg width="16" height="17" viewBox="0 0 16 17" fill="none" xmlns="http://www.w3.org/2000/svg"><path d="M10.7817 8.15636L7.20566 4.58036L8.14833 3.6377L13.3337 8.82303L8.14833 14.0084L7.20566 13.0657L10.7817 9.4897H2.66699V8.15636H10.7817Z" fill="black"></path></svg></a></div></div><div class="header_partWrapper__wFjH4 header_rightPart__mJ5rk"><div class="header_imgWrapper__acXaO" style="background-image:url(https://assets.zilliz.com/medium_Group_13397_084d85124a.png)"></div><a class="header_linkTitle__rhULA" href="/customers/beni">Beni Revolutionizes Sustainable Fashion with Zilliz Cloud&#x27;s Vector Search</a></div></div></div></li></ul><div class="header_btnsWrapper__r9jQ0"><div class="header_languageSelector__MZ0jb"><button class="header_languageBtn__687U2"><svg width="24" height="24" viewBox="0 0 24 24" fill="none" xmlns="http://www.w3.org/2000/svg"><path d="M12 21C10.7613 21 9.59467 20.7633 8.5 20.29C7.40533 19.8167 6.452 19.1733 5.64 18.36C4.82667 17.5487 4.18333 16.5953 3.71 15.5C3.23667 14.4053 3 13.2387 3 12C3 10.758 3.23667 9.59033 3.71 8.497C4.184 7.40367 4.82733 6.451 5.64 5.639C6.45133 4.827 7.40467 4.18433 8.5 3.711C9.59467 3.237 10.7613 3 12 3C13.242 3 14.4097 3.23667 15.503 3.71C16.5963 4.184 17.549 4.82733 18.361 5.64C19.173 6.452 19.8157 7.40433 20.289 8.497C20.763 9.59033 21 10.758 21 12C21 13.2387 20.7633 14.4053 20.29 15.5C19.8167 16.5947 19.1733 17.548 18.36 18.36C17.548 19.1727 16.5957 19.816 15.503 20.29C14.4097 20.7633 13.242 21 12 21ZM12 20.008C12.5867 19.254 13.0707 18.5137 13.452 17.787C13.8327 17.0603 14.1423 16.247 14.381 15.347H9.619C9.883 16.2977 10.199 17.1363 10.567 17.863C10.935 18.5897 11.4127 19.3047 12 20.008ZM10.727 19.858C10.2603 19.308 9.83433 18.628 9.449 17.818C9.06367 17.0087 8.777 16.1847 8.589 15.346H4.753C5.32633 16.59 6.13867 17.61 7.19 18.406C8.242 19.202 9.42067 19.686 10.726 19.858M13.272 19.858C14.5773 19.686 15.756 19.202 16.808 18.406C17.86 17.61 18.6723 16.59 19.245 15.346H15.411C15.1577 16.1973 14.8387 17.028 14.454 17.838C14.0687 18.6473 13.6747 19.3207 13.272 19.858ZM4.345 14.346H8.38C8.304 13.936 8.25067 13.5363 8.22 13.147C8.188 12.7577 8.172 12.3753 8.172 12C8.172 11.6247 8.18767 11.2423 8.219 10.853C8.25033 10.4637 8.30367 10.0637 8.379 9.653H4.347C4.23833 9.99967 4.15333 10.3773 4.092 10.786C4.03067 11.1947 4 11.5993 4 12C4 12.4013 4.03033 12.806 4.091 13.214C4.15233 13.6227 4.23733 14 4.346 14.346M9.381 14.346H14.619C14.695 13.936 14.7483 13.5427 14.779 13.166C14.811 12.79 14.827 12.4013 14.827 12C14.827 11.5987 14.8113 11.21 14.78 10.834C14.7487 10.4573 14.6953 10.064 14.62 9.654H9.38C9.30467 10.064 9.25133 10.4573 9.22 10.834C9.18867 11.21 9.173 11.5987 9.173 12C9.173 12.4013 9.18867 12.79 9.22 13.166C9.25133 13.5427 9.30567 13.936 9.381 14.346ZM15.62 14.346H19.654C19.7627 13.9993 19.8477 13.622 19.909 13.214C19.9703 12.806 20.0007 12.4013 20 12C20 11.5987 19.9697 11.194 19.909 10.786C19.8477 10.3773 19.7627 10 19.654 9.654H15.619C15.695 10.064 15.7483 10.4637 15.779 10.853C15.811 11.2423 15.827 11.6247 15.827 12C15.827 12.3753 15.8113 12.7577 15.78 13.147C15.7487 13.5363 15.6953 13.9363 15.62 14.347M15.412 8.654H19.246C18.66 7.38467 17.8573 6.36467 16.838 5.594C15.818 4.82333 14.6297 4.33333 13.273 4.124C13.7397 4.73733 14.1593 5.43933 14.532 6.23C14.904 7.02 15.1973 7.828 15.412 8.654ZM9.619 8.654H14.381C14.117 7.71533 13.7913 6.86667 13.404 6.108C13.0173 5.34867 12.5493 4.64333 12 3.992C11.4513 4.64333 10.9833 5.34867 10.596 6.108C10.2093 6.86667 9.88367 7.71533 9.619 8.654ZM4.754 8.654H8.588C8.80267 7.828 9.096 7.02 9.468 6.23C9.84067 5.43933 10.2603 4.737 10.727 4.123C9.35767 4.333 8.16633 4.82633 7.153 5.603C6.13967 6.38033 5.33967 7.397 4.753 8.653" fill="#1D2939"></path></svg></button><div class="header_dropdownWrapper__Y8x_9"><button class="BaseButton_root__SFmw5 BaseButton_contained__2JisA header_langButton__YmBJV">English</button><button class="BaseButton_root__SFmw5 BaseButton_contained__2JisA header_langButton__YmBJV">日本語</button><button class="BaseButton_root__SFmw5 BaseButton_contained__2JisA header_langButton__YmBJV">한국어</button><button class="BaseButton_root__SFmw5 BaseButton_contained__2JisA header_langButton__YmBJV">Español</button><button class="BaseButton_root__SFmw5 BaseButton_contained__2JisA header_langButton__YmBJV">Français</button><button class="BaseButton_root__SFmw5 BaseButton_contained__2JisA header_langButton__YmBJV">Deutsch</button><button class="BaseButton_root__SFmw5 BaseButton_contained__2JisA header_langButton__YmBJV">Italiano</button><button class="BaseButton_root__SFmw5 BaseButton_contained__2JisA header_langButton__YmBJV">Português</button><button class="BaseButton_root__SFmw5 BaseButton_contained__2JisA header_langButton__YmBJV">Русский</button></div></div><a class="header_linkBtn__MlnDS" href="/contact-sales">Contact us</a><a rel="noopener noreferrer" target="_blank" class="header_linkBtn__MlnDS" href="https://cloud.zilliz.com/login">Log in</a><a rel="noreferrer noopener" target="_blank" title="" class="BaseButton_root__SFmw5 BaseButton_contained__2JisA" href="https://cloud.zilliz.com/signup?utm_page=learn/guide-to-chunking-strategies-for-rag&amp;utm_button=nav_right">Get Started Free</a></div></div></div></header><header class="mobileHeader_headerContainer__voi8M"><div class="page_container__IibMw"><div class="mobileHeader_header__Xap_i"><a title="Zilliz logo" href="/"><svg width="97" height="40" viewBox="0 0 97 40" fill="none" xmlns="http://www.w3.org/2000/svg"><g clip-path="url(#clip0_4874_3768)"><rect width="97" height="40" fill="transparent"></rect><path fill-rule="evenodd" clip-rule="evenodd" d="M18.6541 27.0547V39.7949H21.1413V24.5393L27.7546 35.9938C28.503 35.6278 29.2221 35.2111 29.9074 34.7483L22.6675 22.2084L30.641 25.1105C31.0007 24.3705 31.2862 23.5877 31.4879 22.7719L27.007 21.141H39.7949V18.6538H24.5381L35.9936 12.04C35.6276 11.2916 35.2109 10.5725 34.748 9.8872L22.2832 17.0838L25.1605 9.1786C24.4221 8.81536 23.6406 8.52618 22.8259 8.32075L21.1413 12.9492V0H18.6541V15.257L12.04 3.80101C11.2916 4.16702 10.5725 4.58369 9.88716 5.04654L17.0968 17.534L9.17163 14.6495C8.80943 15.3884 8.52133 16.1702 8.31702 16.9852L12.9015 18.6538H1.08717e-07L0 21.141H15.2559L3.80081 27.7546C4.16682 28.503 4.58348 29.2221 5.04633 29.9074L17.6089 22.6545L14.6995 30.6478C15.44 31.0066 16.2231 31.291 17.0392 31.4915L18.6541 27.0547Z" fill="url(#mobile-logo)"></path><rect x="46.0625" y="12.4359" width="11.3415" height="2.48718" fill="#000"></rect><rect x="85.3599" y="12.4359" width="11.3415" height="2.48718" fill="#000"></rect><rect x="67.0542" y="6.66563" width="2.68615" height="20.6933" fill="#000"></rect><rect x="61.085" y="12.4359" width="2.68615" height="14.9231" fill="#000"></rect><rect width="2.68615" height="2.68615" transform="matrix(1 0 0 -1 61.085 9.35179)" fill="#000"></rect><rect x="45.7642" y="24.8718" width="11.9385" height="2.48718" fill="#000"></rect><path d="M45.7642 24.8718L54.2216 14.9231L57.4042 14.9231L48.9467 24.8718L45.7642 24.8718Z" fill="#000"></path><path d="M85.0615 24.8718L93.519 14.9231L96.7015 14.9231L88.2441 24.8718L85.0615 24.8718Z" fill="#000"></path><rect x="73.0234" y="6.66563" width="2.68615" height="20.6933" fill="#000"></rect><rect x="85.0615" y="24.8718" width="11.9385" height="2.48718" fill="#000"></rect><rect x="78.9927" y="12.4359" width="2.68615" height="14.9231" fill="#000"></rect><rect width="2.68615" height="2.68615" transform="matrix(1 0 0 -1 78.9927 9.35179)" fill="#000"></rect></g><defs><linearGradient id="mobile-logo" x1="8.45641" y1="4.2282" x2="29.0503" y2="37.6061" gradientUnits="userSpaceOnUse"><stop stop-color="#9D41FF"></stop><stop offset="0.468794" stop-color="#2858FF"></stop><stop offset="0.770884" stop-color="#29B8FF"></stop><stop offset="1" stop-color="#00F0FF"></stop></linearGradient><clipPath id="clip0_4874_3768"><rect width="97" height="40" fill="white"></rect></clipPath></defs></svg></a><div class="mobileHeader_menu__3CNGu"><div class="mobileHeader_languageSelector__zLvyD"><button class="mobileHeader_languageBtn__q35Ut"><svg width="24" height="24" viewBox="0 0 24 24" fill="none" xmlns="http://www.w3.org/2000/svg"><path d="M12 21C10.7613 21 9.59467 20.7633 8.5 20.29C7.40533 19.8167 6.452 19.1733 5.64 18.36C4.82667 17.5487 4.18333 16.5953 3.71 15.5C3.23667 14.4053 3 13.2387 3 12C3 10.758 3.23667 9.59033 3.71 8.497C4.184 7.40367 4.82733 6.451 5.64 5.639C6.45133 4.827 7.40467 4.18433 8.5 3.711C9.59467 3.237 10.7613 3 12 3C13.242 3 14.4097 3.23667 15.503 3.71C16.5963 4.184 17.549 4.82733 18.361 5.64C19.173 6.452 19.8157 7.40433 20.289 8.497C20.763 9.59033 21 10.758 21 12C21 13.2387 20.7633 14.4053 20.29 15.5C19.8167 16.5947 19.1733 17.548 18.36 18.36C17.548 19.1727 16.5957 19.816 15.503 20.29C14.4097 20.7633 13.242 21 12 21ZM12 20.008C12.5867 19.254 13.0707 18.5137 13.452 17.787C13.8327 17.0603 14.1423 16.247 14.381 15.347H9.619C9.883 16.2977 10.199 17.1363 10.567 17.863C10.935 18.5897 11.4127 19.3047 12 20.008ZM10.727 19.858C10.2603 19.308 9.83433 18.628 9.449 17.818C9.06367 17.0087 8.777 16.1847 8.589 15.346H4.753C5.32633 16.59 6.13867 17.61 7.19 18.406C8.242 19.202 9.42067 19.686 10.726 19.858M13.272 19.858C14.5773 19.686 15.756 19.202 16.808 18.406C17.86 17.61 18.6723 16.59 19.245 15.346H15.411C15.1577 16.1973 14.8387 17.028 14.454 17.838C14.0687 18.6473 13.6747 19.3207 13.272 19.858ZM4.345 14.346H8.38C8.304 13.936 8.25067 13.5363 8.22 13.147C8.188 12.7577 8.172 12.3753 8.172 12C8.172 11.6247 8.18767 11.2423 8.219 10.853C8.25033 10.4637 8.30367 10.0637 8.379 9.653H4.347C4.23833 9.99967 4.15333 10.3773 4.092 10.786C4.03067 11.1947 4 11.5993 4 12C4 12.4013 4.03033 12.806 4.091 13.214C4.15233 13.6227 4.23733 14 4.346 14.346M9.381 14.346H14.619C14.695 13.936 14.7483 13.5427 14.779 13.166C14.811 12.79 14.827 12.4013 14.827 12C14.827 11.5987 14.8113 11.21 14.78 10.834C14.7487 10.4573 14.6953 10.064 14.62 9.654H9.38C9.30467 10.064 9.25133 10.4573 9.22 10.834C9.18867 11.21 9.173 11.5987 9.173 12C9.173 12.4013 9.18867 12.79 9.22 13.166C9.25133 13.5427 9.30567 13.936 9.381 14.346ZM15.62 14.346H19.654C19.7627 13.9993 19.8477 13.622 19.909 13.214C19.9703 12.806 20.0007 12.4013 20 12C20 11.5987 19.9697 11.194 19.909 10.786C19.8477 10.3773 19.7627 10 19.654 9.654H15.619C15.695 10.064 15.7483 10.4637 15.779 10.853C15.811 11.2423 15.827 11.6247 15.827 12C15.827 12.3753 15.8113 12.7577 15.78 13.147C15.7487 13.5363 15.6953 13.9363 15.62 14.347M15.412 8.654H19.246C18.66 7.38467 17.8573 6.36467 16.838 5.594C15.818 4.82333 14.6297 4.33333 13.273 4.124C13.7397 4.73733 14.1593 5.43933 14.532 6.23C14.904 7.02 15.1973 7.828 15.412 8.654ZM9.619 8.654H14.381C14.117 7.71533 13.7913 6.86667 13.404 6.108C13.0173 5.34867 12.5493 4.64333 12 3.992C11.4513 4.64333 10.9833 5.34867 10.596 6.108C10.2093 6.86667 9.88367 7.71533 9.619 8.654ZM4.754 8.654H8.588C8.80267 7.828 9.096 7.02 9.468 6.23C9.84067 5.43933 10.2603 4.737 10.727 4.123C9.35767 4.333 8.16633 4.82633 7.153 5.603C6.13967 6.38033 5.33967 7.397 4.753 8.653" fill="#1D2939"></path></svg></button><div class="mobileHeader_dropdownWrapper__0DLyM"><button class="BaseButton_root__SFmw5 BaseButton_contained__2JisA mobileHeader_langButton__YkCt_">English</button><button class="BaseButton_root__SFmw5 BaseButton_contained__2JisA mobileHeader_langButton__YkCt_">日本語</button><button class="BaseButton_root__SFmw5 BaseButton_contained__2JisA mobileHeader_langButton__YkCt_">한국어</button><button class="BaseButton_root__SFmw5 BaseButton_contained__2JisA mobileHeader_langButton__YkCt_">Español</button><button class="BaseButton_root__SFmw5 BaseButton_contained__2JisA mobileHeader_langButton__YkCt_">Français</button><button class="BaseButton_root__SFmw5 BaseButton_contained__2JisA mobileHeader_langButton__YkCt_">Deutsch</button><button class="BaseButton_root__SFmw5 BaseButton_contained__2JisA mobileHeader_langButton__YkCt_">Italiano</button><button class="BaseButton_root__SFmw5 BaseButton_contained__2JisA mobileHeader_langButton__YkCt_">Português</button><button class="BaseButton_root__SFmw5 BaseButton_contained__2JisA mobileHeader_langButton__YkCt_">Русский</button></div></div><svg width="24" height="24" viewBox="0 0 24 24"><rect x="2" y="5" width="20" height="2" fill="black"></rect><rect x="2" y="11" width="20" height="2" fill="black"></rect><rect x="2" y="17" width="20" height="2" fill="black"></rect></svg></div></div></div></header><main><div class="detailHead_headContainer__aCYlj"><div class="page_container__IibMw"><div class="detailHead_contentContainer__aimWx"><div class="detailHead_leftSection__PKLAW"><div class="globalBreadcrumb_breadcrumbContainer__8VB_S"><ul class="globalBreadcrumb_breadcrumbList___dw0x globalBreadcrumb_horizonAlignLeft__pvF41"><li class="globalBreadcrumb_listItem__4n_9F"><a class="globalBreadcrumb_breadcrumbItem__3Axv8 globalBreadcrumb_homeItem__9PTnF globalBreadcrumb_darkTheme__R4ILy" href="/"><svg width="13" height="12" viewBox="0 0 13 12" fill="none" xmlns="http://www.w3.org/2000/svg" color="#fff"><g clip-path="url(#clip0_19069_588)"><path d="M11.4526 5.66339L6.71842 1.17877C6.42915 0.90476 5.97612 0.90476 5.68685 1.17877L0.952637 5.66339" stroke="#fff" stroke-width="0.9" stroke-linecap="round" stroke-linejoin="round"></path><path d="M2.05817 7.37201V10.5598C2.05817 10.974 2.39395 11.3097 2.80817 11.3097H9.57781C9.99202 11.3097 10.3278 10.974 10.3278 10.5597V7.37201" stroke="#fff" stroke-width="0.9" stroke-linecap="round" stroke-linejoin="round"></path><path d="M7.50721 11.3097V8.12201C7.50721 7.7078 7.17142 7.37201 6.75721 7.37201H5.62885C5.21463 7.37201 4.87885 7.70779 4.87885 8.12201V11.3097" stroke="#fff" stroke-width="0.9" stroke-linecap="round" stroke-linejoin="round"></path></g><defs><clipPath id="clip0_19069_588"><rect width="12" height="12" fill="white" transform="translate(0.202637)"></rect></clipPath></defs></svg></a><svg width="8" height="14" viewBox="0 0 8 14" fill="none" xmlns="http://www.w3.org/2000/svg" color="#fff"><path d="M7.39502 1.20099L0.608318 12.7991" stroke="#fff"></path></svg></li><li class="globalBreadcrumb_listItem__4n_9F"><a class="globalBreadcrumb_breadcrumbItem__3Axv8 globalBreadcrumb_darkTheme__R4ILy" href="/learn">Learn</a><svg width="8" height="14" viewBox="0 0 8 14" fill="none" xmlns="http://www.w3.org/2000/svg" color="#fff"><path d="M7.39502 1.20099L0.608318 12.7991" stroke="#fff"></path></svg></li><li class="globalBreadcrumb_listItem__4n_9F"><p class="globalBreadcrumb_currentItem__2QgJK detailHead_currentNavItem__Hex2q globalBreadcrumb_darkTheme__R4ILy">Retrieval Augmented Generation (RAG) 101</p></li></ul></div><h1 class="detailHead_title__D0Z91">A Guide to Chunking Strategies for Retrieval Augmented Generation (RAG)</h1><div class="detailHead_timeWrapper__NFKKE"><span>May 15, 2024</span><span class="detailHead_spot__pMBk4"></span><span>16 min read</span></div><p class="detailHead_desc__leSOl">We explored various facets of chunking strategies within Retrieval-Augmented Generation (RAG) systems in this guide. </p><p class="detailHead_authorName__w4D3w">By <a href="/authors/Rahul_">Rahul </a></p></div><div class="detailHead_linksWrapper__1_8Vd"><p class="detailHead_seriesTitle__htQqo">Read the entire series</p><div class="detailHead_linksContent__Z_1l1"><ul class="detailHead_listWrapper__jGB5W"><li class="detailHead_listItem___5wTj"><span class="detailHead_iconWrapper__MtztT"><svg width="6" height="10" viewBox="0 0 6 10" fill="none" xmlns="http://www.w3.org/2000/svg"><path opacity="0.6" d="M1.6625e-08 1.03866C9.919e-09 0.619699 0.484383 0.386523 0.811863 0.647842L5.77613 4.60918C6.02698 4.80935 6.02698 5.19065 5.77613 5.39082L0.811864 9.35216C0.484383 9.61348 1.50143e-07 9.3803 1.43437e-07 8.96134L1.6625e-08 1.03866Z" fill="white"></path></svg></span><a href="/learn/Retrieval-Augmented-Generation">Build AI Apps with Retrieval Augmented Generation (RAG)</a></li><li class="detailHead_listItem___5wTj"><span class="detailHead_iconWrapper__MtztT"><svg width="6" height="10" viewBox="0 0 6 10" fill="none" xmlns="http://www.w3.org/2000/svg"><path opacity="0.6" d="M1.6625e-08 1.03866C9.919e-09 0.619699 0.484383 0.386523 0.811863 0.647842L5.77613 4.60918C6.02698 4.80935 6.02698 5.19065 5.77613 5.39082L0.811864 9.35216C0.484383 9.61348 1.50143e-07 9.3803 1.43437e-07 8.96134L1.6625e-08 1.03866Z" fill="white"></path></svg></span><a href="/learn/RAG-handbook">Mastering LLM Challenges: An Exploration of Retrieval Augmented Generation</a></li><li class="detailHead_listItem___5wTj"><span class="detailHead_iconWrapper__MtztT"><svg width="6" height="10" viewBox="0 0 6 10" fill="none" xmlns="http://www.w3.org/2000/svg"><path opacity="0.6" d="M1.6625e-08 1.03866C9.919e-09 0.619699 0.484383 0.386523 0.811863 0.647842L5.77613 4.60918C6.02698 4.80935 6.02698 5.19065 5.77613 5.39082L0.811864 9.35216C0.484383 9.61348 1.50143e-07 9.3803 1.43437e-07 8.96134L1.6625e-08 1.03866Z" fill="white"></path></svg></span><a href="/learn/nlp-technologies-in-deep-learning">Key NLP technologies in Deep Learning</a></li><li class="detailHead_listItem___5wTj"><span class="detailHead_iconWrapper__MtztT"><svg width="6" height="10" viewBox="0 0 6 10" fill="none" xmlns="http://www.w3.org/2000/svg"><path opacity="0.6" d="M1.6625e-08 1.03866C9.919e-09 0.619699 0.484383 0.386523 0.811863 0.647842L5.77613 4.60918C6.02698 4.80935 6.02698 5.19065 5.77613 5.39082L0.811864 9.35216C0.484383 9.61348 1.50143e-07 9.3803 1.43437e-07 8.96134L1.6625e-08 1.03866Z" fill="white"></path></svg></span><a href="/learn/How-To-Evaluate-RAG-Applications">How to Evaluate RAG Applications</a></li><li class="detailHead_listItem___5wTj"><span class="detailHead_iconWrapper__MtztT"><svg width="6" height="10" viewBox="0 0 6 10" fill="none" xmlns="http://www.w3.org/2000/svg"><path opacity="0.6" d="M1.6625e-08 1.03866C9.919e-09 0.619699 0.484383 0.386523 0.811863 0.647842L5.77613 4.60918C6.02698 4.80935 6.02698 5.19065 5.77613 5.39082L0.811864 9.35216C0.484383 9.61348 1.50143e-07 9.3803 1.43437e-07 8.96134L1.6625e-08 1.03866Z" fill="white"></path></svg></span><a href="/learn/optimize-rag-with-rerankers-the-role-and-tradeoffs">Optimizing RAG with Rerankers: The Role and Trade-offs </a></li><li class="detailHead_listItem___5wTj"><span class="detailHead_iconWrapper__MtztT"><svg width="6" height="10" viewBox="0 0 6 10" fill="none" xmlns="http://www.w3.org/2000/svg"><path opacity="0.6" d="M1.6625e-08 1.03866C9.919e-09 0.619699 0.484383 0.386523 0.811863 0.647842L5.77613 4.60918C6.02698 4.80935 6.02698 5.19065 5.77613 5.39082L0.811864 9.35216C0.484383 9.61348 1.50143e-07 9.3803 1.43437e-07 8.96134L1.6625e-08 1.03866Z" fill="white"></path></svg></span><a href="/learn/multimodal-RAG">Exploring the Frontier of Multimodal Retrieval-Augmented Generation (RAG)</a></li><li class="detailHead_listItem___5wTj"><span class="detailHead_iconWrapper__MtztT"><svg width="6" height="10" viewBox="0 0 6 10" fill="none" xmlns="http://www.w3.org/2000/svg"><path opacity="0.6" d="M1.6625e-08 1.03866C9.919e-09 0.619699 0.484383 0.386523 0.811863 0.647842L5.77613 4.60918C6.02698 4.80935 6.02698 5.19065 5.77613 5.39082L0.811864 9.35216C0.484383 9.61348 1.50143e-07 9.3803 1.43437e-07 8.96134L1.6625e-08 1.03866Z" fill="white"></path></svg></span><a href="/learn/enhancing-chatgpt-with-milvus">Enhancing ChatGPT with Milvus: Powering AI with Long-Term Memory</a></li><li class="detailHead_listItem___5wTj"><span class="detailHead_iconWrapper__MtztT"><svg width="6" height="10" viewBox="0 0 6 10" fill="none" xmlns="http://www.w3.org/2000/svg"><path opacity="0.6" d="M1.6625e-08 1.03866C9.919e-09 0.619699 0.484383 0.386523 0.811863 0.647842L5.77613 4.60918C6.02698 4.80935 6.02698 5.19065 5.77613 5.39082L0.811864 9.35216C0.484383 9.61348 1.50143e-07 9.3803 1.43437e-07 8.96134L1.6625e-08 1.03866Z" fill="white"></path></svg></span><a href="/learn/how-to-enhance-the-performance-of-your-rag-pipeline">How to Enhance the Performance of Your RAG Pipeline</a></li><li class="detailHead_listItem___5wTj"><span class="detailHead_iconWrapper__MtztT"><svg width="6" height="10" viewBox="0 0 6 10" fill="none" xmlns="http://www.w3.org/2000/svg"><path opacity="0.6" d="M1.6625e-08 1.03866C9.919e-09 0.619699 0.484383 0.386523 0.811863 0.647842L5.77613 4.60918C6.02698 4.80935 6.02698 5.19065 5.77613 5.39082L0.811864 9.35216C0.484383 9.61348 1.50143e-07 9.3803 1.43437e-07 8.96134L1.6625e-08 1.03866Z" fill="white"></path></svg></span><a href="/learn/enhancing-chatgpt-with-milvus">Enhancing ChatGPT with Milvus: Powering AI with Long-Term Memory</a></li><li class="detailHead_listItem___5wTj"><span class="detailHead_iconWrapper__MtztT"><svg width="6" height="10" viewBox="0 0 6 10" fill="none" xmlns="http://www.w3.org/2000/svg"><path opacity="0.6" d="M1.6625e-08 1.03866C9.919e-09 0.619699 0.484383 0.386523 0.811863 0.647842L5.77613 4.60918C6.02698 4.80935 6.02698 5.19065 5.77613 5.39082L0.811864 9.35216C0.484383 9.61348 1.50143e-07 9.3803 1.43437e-07 8.96134L1.6625e-08 1.03866Z" fill="white"></path></svg></span><a href="/learn/pandas-dataframe-chunking-anf-vectorizing-with-milvus">Pandas DataFrame: Chunking and Vectorizing with Milvus</a></li><li class="detailHead_listItem___5wTj"><span class="detailHead_iconWrapper__MtztT"><svg width="6" height="10" viewBox="0 0 6 10" fill="none" xmlns="http://www.w3.org/2000/svg"><path opacity="0.6" d="M1.6625e-08 1.03866C9.919e-09 0.619699 0.484383 0.386523 0.811863 0.647842L5.77613 4.60918C6.02698 4.80935 6.02698 5.19065 5.77613 5.39082L0.811864 9.35216C0.484383 9.61348 1.50143e-07 9.3803 1.43437e-07 8.96134L1.6625e-08 1.03866Z" fill="white"></path></svg></span><a href="/learn/how-to-build-rag-system-using-llama3-ollama-dspy-milvus">How to build a Retrieval-Augmented Generation (RAG) system using Llama3, Ollama, DSPy, and Milvus</a></li><li class="detailHead_listItem___5wTj detailHead_activeItem__3vbC2"><span class="detailHead_iconWrapper__MtztT"><svg width="6" height="10" viewBox="0 0 6 10" fill="none" xmlns="http://www.w3.org/2000/svg"><path opacity="0.6" d="M1.6625e-08 1.03866C9.919e-09 0.619699 0.484383 0.386523 0.811863 0.647842L5.77613 4.60918C6.02698 4.80935 6.02698 5.19065 5.77613 5.39082L0.811864 9.35216C0.484383 9.61348 1.50143e-07 9.3803 1.43437e-07 8.96134L1.6625e-08 1.03866Z" fill="white"></path></svg></span><a href="/learn/guide-to-chunking-strategies-for-rag">A Guide to Chunking Strategies for Retrieval Augmented Generation (RAG)</a></li><li class="detailHead_listItem___5wTj"><span class="detailHead_iconWrapper__MtztT"><svg width="6" height="10" viewBox="0 0 6 10" fill="none" xmlns="http://www.w3.org/2000/svg"><path opacity="0.6" d="M1.6625e-08 1.03866C9.919e-09 0.619699 0.484383 0.386523 0.811863 0.647842L5.77613 4.60918C6.02698 4.80935 6.02698 5.19065 5.77613 5.39082L0.811864 9.35216C0.484383 9.61348 1.50143e-07 9.3803 1.43437e-07 8.96134L1.6625e-08 1.03866Z" fill="white"></path></svg></span><a href="/learn/improve-rag-and-information-retrieval-with-hyde-hypothetical-document-embeddings">Improving Information Retrieval and RAG with Hypothetical Document Embeddings (HyDE)</a></li><li class="detailHead_listItem___5wTj"><span class="detailHead_iconWrapper__MtztT"><svg width="6" height="10" viewBox="0 0 6 10" fill="none" xmlns="http://www.w3.org/2000/svg"><path opacity="0.6" d="M1.6625e-08 1.03866C9.919e-09 0.619699 0.484383 0.386523 0.811863 0.647842L5.77613 4.60918C6.02698 4.80935 6.02698 5.19065 5.77613 5.39082L0.811864 9.35216C0.484383 9.61348 1.50143e-07 9.3803 1.43437e-07 8.96134L1.6625e-08 1.03866Z" fill="white"></path></svg></span><a href="/learn/build-rag-with-milvus-lite-llama3-and-llamaindex">Building RAG with Milvus Lite, Llama3, and LlamaIndex</a></li><li class="detailHead_listItem___5wTj"><span class="detailHead_iconWrapper__MtztT"><svg width="6" height="10" viewBox="0 0 6 10" fill="none" xmlns="http://www.w3.org/2000/svg"><path opacity="0.6" d="M1.6625e-08 1.03866C9.919e-09 0.619699 0.484383 0.386523 0.811863 0.647842L5.77613 4.60918C6.02698 4.80935 6.02698 5.19065 5.77613 5.39082L0.811864 9.35216C0.484383 9.61348 1.50143e-07 9.3803 1.43437e-07 8.96134L1.6625e-08 1.03866Z" fill="white"></path></svg></span><a href="/learn/enhance-rag-with-radit-fine-tune-approach-to-minimize-llm-hallucinations">Enhancing RAG with RA-DIT: A Fine-Tuning Approach to Minimize LLM Hallucinations</a></li><li class="detailHead_listItem___5wTj"><span class="detailHead_iconWrapper__MtztT"><svg width="6" height="10" viewBox="0 0 6 10" fill="none" xmlns="http://www.w3.org/2000/svg"><path opacity="0.6" d="M1.6625e-08 1.03866C9.919e-09 0.619699 0.484383 0.386523 0.811863 0.647842L5.77613 4.60918C6.02698 4.80935 6.02698 5.19065 5.77613 5.39082L0.811864 9.35216C0.484383 9.61348 1.50143e-07 9.3803 1.43437e-07 8.96134L1.6625e-08 1.03866Z" fill="white"></path></svg></span><a href="/learn/building-rag-with-dify-and-milvus">Building RAG with Dify and Milvus</a></li><li class="detailHead_listItem___5wTj"><span class="detailHead_iconWrapper__MtztT"><svg width="6" height="10" viewBox="0 0 6 10" fill="none" xmlns="http://www.w3.org/2000/svg"><path opacity="0.6" d="M1.6625e-08 1.03866C9.919e-09 0.619699 0.484383 0.386523 0.811863 0.647842L5.77613 4.60918C6.02698 4.80935 6.02698 5.19065 5.77613 5.39082L0.811864 9.35216C0.484383 9.61348 1.50143e-07 9.3803 1.43437e-07 8.96134L1.6625e-08 1.03866Z" fill="white"></path></svg></span><a href="/learn/top-ten-rag-and-llm-evaluation-tools-you-dont-want-to-miss">Top 10 RAG &amp; LLM Evaluation Tools You Don&#x27;t Want To Miss</a></li></ul></div></div></div></div></div><div class="page_container__IibMw"><div class="learnDetail_contentContainer__xRjX3"><div class="learnDetail_docContent__s44U3"><div class="docContainer blogContainer"><p><a href="https://zilliz.com/learn/Retrieval-Augmented-Generation">Retrieval Augmented Generation</a> (RAG) stands out as a significant innovation in <a href="https://zilliz.com/learn/A-Beginner-Guide-to-Natural-Language-Processing">Natural Language Processing</a> (NLP), designed to enhance text generation by integrating the efficient retrieval of relevant information from a vast database. Developed by researchers including Patrick Lewis and his team, RAG combines the power of large pre-trained language models with a retrieval system that pulls data from extensive sources like Wikipedia to inform its responses.</p> <h2 id="What-is-Retrieval-Augmented-Generation-RAG" class="common-anchor-header">What is Retrieval Augmented Generation (RAG)?<button data-href="#What-is-Retrieval-Augmented-Generation-RAG" class="anchor-icon" translate="no"> <svg aria-hidden="true" focusable="false" height="20" version="1.1" viewBox="0 0 16 16" width="16" > <path fill="#0092E4" fill-rule="evenodd" d="M4 9h1v1H4c-1.5 0-3-1.69-3-3.5S2.55 3 4 3h4c1.45 0 3 1.69 3 3.5 0 1.41-.91 2.72-2 3.25V8.59c.58-.45 1-1.27 1-2.09C10 5.22 8.98 4 8 4H4c-.98 0-2 1.22-2 2.5S3 9 4 9zm9-3h-1v1h1c1 0 2 1.22 2 2.5S13.98 12 13 12H9c-.98 0-2-1.22-2-2.5 0-.83.42-1.64 1-2.09V6.25c-1.09.53-2 1.84-2 3.25C6 11.31 7.55 13 9 13h4c1.45 0 3-1.69 3-3.5S14.5 6 13 6z" ></path> </svg> </button></h2><p>RAG is a hybrid language model that merges the capabilities of generative and retrieval-based <a href="https://zilliz.com/learn/7-nlp-models">models in NLP</a>. This approach addresses the limitations of pre-trained language models, which, despite storing vast amounts of factual knowledge, often need help accessing and manipulating this information accurately for complex, knowledge-intensive tasks. RAG tackles this by using a &quot;neural retriever&quot; to fetch relevant information from a &quot;<a href="https://zilliz.com/learn/dense-vector-in-ai-maximize-data-potential-in-machine-learning">dense vector</a> index&quot; of data sources like Wikipedia (or your data), which the model then uses to generate more accurate and contextually appropriate responses.</p> <h2 id="Significance-of-RAG-in-NLP" class="common-anchor-header">Significance of RAG in NLP<button data-href="#Significance-of-RAG-in-NLP" class="anchor-icon" translate="no"> <svg aria-hidden="true" focusable="false" height="20" version="1.1" viewBox="0 0 16 16" width="16" > <path fill="#0092E4" fill-rule="evenodd" d="M4 9h1v1H4c-1.5 0-3-1.69-3-3.5S2.55 3 4 3h4c1.45 0 3 1.69 3 3.5 0 1.41-.91 2.72-2 3.25V8.59c.58-.45 1-1.27 1-2.09C10 5.22 8.98 4 8 4H4c-.98 0-2 1.22-2 2.5S3 9 4 9zm9-3h-1v1h1c1 0 2 1.22 2 2.5S13.98 12 13 12H9c-.98 0-2-1.22-2-2.5 0-.83.42-1.64 1-2.09V6.25c-1.09.53-2 1.84-2 3.25C6 11.31 7.55 13 9 13h4c1.45 0 3-1.69 3-3.5S14.5 6 13 6z" ></path> </svg> </button></h2><p>The development of RAG has marked a substantial improvement over traditional language models, particularly in tasks that require deep knowledge semantic meaning and factual accuracy:</p> <ul> <li><p><strong>Enhanced Text Generation:</strong> By incorporating external data during the generation process, RAG models produce not only diverse and specific text but also more factually accurate compared to traditional seq2seq models that rely only on their internal parameters.</p></li> <li><p><strong>State-of-the-art Performance:</strong> RAG was fine-tuned and evaluated on various NLP tasks in the original RAG paper, particularly excelling in open-domain question answering. It has set new benchmarks, outperforming traditional seq2seq and task-specific models that rely solely on extracting answers from texts.</p></li> <li><p><strong>Flexibility Across Tasks:</strong> Beyond question answering, RAG has shown promise in other complex tasks, like generating content for scenarios modeled after the game &quot;Jeopardy,&quot; where precise and factual language is crucial. This adaptability makes it a powerful tool across various domains of NLP.</p></li> </ul> <p>For further details, the foundational concepts and <a href="https://zilliz.com/blog/how-to-evaluate-retrieval-augmented-generation-rag-applications">applications of RAG</a> are thoroughly discussed in the work by Lewis et al. (2020), available through their NeurIPS paper and other publications ( Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, <a href="https://ar5iv.labs.arxiv.org/html/2005.11401)%E2%80%8B%E2%80%8B">https://ar5iv.labs.arxiv.org/html/2005.11401)</a></p> <h2 id="Chunking" class="common-anchor-header">Chunking<button data-href="#Chunking" class="anchor-icon" translate="no"> <svg aria-hidden="true" focusable="false" height="20" version="1.1" viewBox="0 0 16 16" width="16" > <path fill="#0092E4" fill-rule="evenodd" d="M4 9h1v1H4c-1.5 0-3-1.69-3-3.5S2.55 3 4 3h4c1.45 0 3 1.69 3 3.5 0 1.41-.91 2.72-2 3.25V8.59c.58-.45 1-1.27 1-2.09C10 5.22 8.98 4 8 4H4c-.98 0-2 1.22-2 2.5S3 9 4 9zm9-3h-1v1h1c1 0 2 1.22 2 2.5S13.98 12 13 12H9c-.98 0-2-1.22-2-2.5 0-.83.42-1.64 1-2.09V6.25c-1.09.53-2 1.84-2 3.25C6 11.31 7.55 13 9 13h4c1.45 0 3-1.69 3-3.5S14.5 6 13 6z" ></path> </svg> </button></h2><p>&quot;Chunking&quot; (and sometimes called &quot;llm chunking&quot;)refers to dividing a large text corpus into smaller, manageable pieces or segments. Each recursive chunking part acts as a standalone unit of information that can be individually indexed and retrieved. For instance, in the development of RAG models, as Lewis et al. (2020) described, Wikipedia articles are split into disjoint 100-word chunks to create a total of around 21 million documents that serve as the retrieval database. This chunking technique is crucial for enhancing the efficiency and accuracy of the retrieval process, which in turn impacts the overall performance of RAG models in various aspects, such as:</p> <ul> <li><strong>Improved Retrieval Efficiency:</strong> By organizing the text into smaller chunks, the retrieval component of the RAG model can more quickly and accurately identify relevant information. This is because smaller chunks reduce the computational load on the retrieval system, allowing for faster response times during the retrieval phase.</li> </ul> <ul> <li><strong>Enhanced Accuracy and Relevance:</strong> Chunking enables the RAG model to pinpoint the most relevant information more precisely. Since each chunk is a condensed representation of information, it is easier for the retrieval system to assess the relevance of each chunk to a given query, thus improving the likelihood of retrieving the most pertinent information.</li> </ul> <ul> <li><strong>Scalability and Manageability:</strong> Handling massive datasets becomes more feasible with chunking. It allows the system to manage and update the database efficiently, as each chunk can be individually indexed and maintained. This is particularly important for RAG models, which rely on up-to-date information to generate accurate and relevant outputs.</li> </ul> <ul> <li><strong>Balanced Information Distribution:</strong> Chunking ensures that the information is evenly distributed across the dataset, which helps maintain a balanced retrieval process. This uniform distribution prevents the retrieval model from being biased towards longer documents that might otherwise dominate the retrieval results if the corpus were not chunked.</li> </ul> <h2 id="Detailed-Exploration-of-Chunking-Strategies-in-RAG-Systems" class="common-anchor-header">Detailed Exploration of Chunking Strategies in RAG Systems<button data-href="#Detailed-Exploration-of-Chunking-Strategies-in-RAG-Systems" class="anchor-icon" translate="no"> <svg aria-hidden="true" focusable="false" height="20" version="1.1" viewBox="0 0 16 16" width="16" > <path fill="#0092E4" fill-rule="evenodd" d="M4 9h1v1H4c-1.5 0-3-1.69-3-3.5S2.55 3 4 3h4c1.45 0 3 1.69 3 3.5 0 1.41-.91 2.72-2 3.25V8.59c.58-.45 1-1.27 1-2.09C10 5.22 8.98 4 8 4H4c-.98 0-2 1.22-2 2.5S3 9 4 9zm9-3h-1v1h1c1 0 2 1.22 2 2.5S13.98 12 13 12H9c-.98 0-2-1.22-2-2.5 0-.83.42-1.64 1-2.09V6.25c-1.09.53-2 1.84-2 3.25C6 11.31 7.55 13 9 13h4c1.45 0 3-1.69 3-3.5S14.5 6 13 6z" ></path> </svg> </button></h2><p>Advanced RAG](https://zilliz.com/blog/advanced-rag-apps-with-llamaindex) techniques like the following chunking strategies are crucial for optimizing the efficiency of RAG systems in processing and understanding large texts. Let’s go deeper into three primary chunking strategies—fixed-size chunking, semantic chunking, and hybrid chunking—and how they can be applied effectively in RAG contexts.</p> <ol> <li><p><strong>Fixed-Size Chunking:</strong> Fixed-size chunking involves breaking down text into uniformly sized pieces based on a predefined number of characters, words, or tokens. This method is straightforward, making it a popular choice for initial data processing phases where quick data traversal is needed.</p> <ol> <li><p><strong>Strategy:</strong> This technique involves dividing text into chunks of a predetermined size, such as every 100 words or every 500 characters.</p></li> <li><p><strong>Implementation:</strong> Implementing fixed-size chunking can be straightforward using programming libraries that handle string operations, such as Python's basic string methods or more complex libraries like NLTK or spaCy for more structured data. For example,</p></li> </ol></li> </ol> <pre><code><span class="hljs-keyword">def</span> <span class="hljs-title function_">fixed_size_chunking</span>(<span class="hljs-params">text, chunk_size=<span class="hljs-number">100</span></span>): <span class="hljs-keyword">return</span> [text[i:i+chunk_size] <span class="hljs-keyword">for</span> i <span class="hljs-keyword">in</span> <span class="hljs-built_in">range</span>(<span class="hljs-number">0</span>, <span class="hljs-built_in">len</span>(text), chunk_size)] <button class="copy-code-btn"></button></code></pre> <ol> <li><p><strong>Advantages:</strong></p> <ol> <li><p>Simplicity and predictability in implementation, which makes it easier to manage and index the chunks.</p></li> <li><p>High computational efficiency and ease of implementation.</p></li> </ol></li> <li><p><strong>Disadvantages:</strong></p> <ol> <li><p>It may cut off important semantic boundaries, leading to retrieval of out-of-context information.</p></li> <li><p>Not flexible, as it does not adapt to the natural structure of the text.</p></li> </ol></li> <li><p><strong>When to Use:</strong> This strategy is ideal for scenarios where speed is more crucial than depth of context, such as during the preliminary analysis of large datasets where detailed semantic understanding is less critical.</p></li> </ol> <ol> <li><p><strong>Semantic Chunking:</strong> Chunking segments texts based on meaningful content units, respecting natural language boundaries such as sentences, paragraphs, or thematic breaks.</p> <ol> <li><p><strong>Strategy:</strong> Unlike fixed-size chunking, this method splits text based on natural breaks in content, such as paragraphs, sections, or topics.</p></li> <li><p><strong>Implementation:</strong> Tools like <strong>spaCy</strong> or <strong>NLTK</strong> can identify natural breaks in the text, such as end-of-sentence punctuation, to segment texts semantically.</p></li> <li><p><strong>Advantages:</strong></p> <ol> <li><p>Maintains the integrity of the information within each chunk, ensuring that all content within a chunk is contextually related.</p></li> <li><p>Enhances the relevance and accuracy of the retrieved data, which directly impacts the quality of generated responses.</p></li> </ol></li> <li><p><strong>Disadvantages:</strong></p> <ol> <li>More complex to implement as it requires understanding of the text structure and content.</li> </ol></li> <li><p><strong>When to Use:</strong> Semantic chunking is particularly beneficial in content-sensitive applications like document summarization or legal document analysis, where understanding the full context and nuances of the language is essential.</p></li> </ol></li> </ol> <ol> <li><p><strong>Hybrid Chunking:</strong> Hybrid chunking combines multiple chunking methods to leverage the benefits of both fixed-size and semantic chunking, optimizing both speed and accuracy.</p> <ol> <li><p><strong>Strategy:</strong> Combines multiple chunking methods to leverage the advantages of each. For example, a system might use fixed-length chunking for initial data processing and switch to semantic chunking when more precise retrieval is necessary.</p></li> <li><p><strong>Implementation:</strong> An initial pass might use fixed-size chunking for quick indexing, followed by semantic chunking during the retrieval phase to ensure contextual integrity. Integrating tools like <strong>spaCy</strong> for semantic analysis with custom scripts for fixed-size chunking can create a robust <a href="https://zilliz.com/blog/experimenting-with-different-chunking-strategies-via-langchain">chunking strategy</a> that adapts to various needs.</p></li> <li><p><strong>Advantages:</strong> Balances speed and contextual integrity by adapting the chunking method based on the task requirements.</p></li> <li><p><strong>Disadvantages:</strong> Can be more resource-intensive to implement and maintain.</p></li> <li><p><strong>When to Use:</strong></p> <ol> <li><p><strong>Enterprise Systems:</strong> In customer service chatbots, hybrid chunking can quickly retrieve customer query-related information while ensuring the responses are contextually appropriate and semantically rich.</p></li> <li><p><strong>Academic Research:</strong> Hybrid chunking is used in research to handle diverse data types, from structured scientific articles to informal interviews, ensuring detailed analysis and relevant data retrieval. <span class="img-wrapper"> <img src="https://assets.zilliz.com/Here_s_an_example_of_Chunking_using_Chunk_Viz_473dc44447.png" alt="Here’s an example of Chunking using ChunkViz.png" class="doc-image" id="here’s-an-example-of-chunking-using-chunkviz.png" /> <span>Here’s an example of Chunking using ChunkViz.png</span> </span> </p></li> </ol></li> </ol></li> </ol> <p>Here’s an example of Chunking using ChunkViz (<a href="https://chunkviz.up.railway.app/">https://chunkviz.up.railway.app/</a>)</p> <p>In the example given, <strong>Chunk size</strong> refers to the quantity of text (measured in terms exactly the same size of characters, single sentence, words, or sentences) that makes up a single unit or &quot;chunk&quot; during text processing. The choice of chunk size is crucial because it determines how much information is handled at once during tasks such as text analysis, vectorization, or in systems like RAG.</p> <ul> <li><p><strong>Smaller Chunk Sizes:</strong> These are typically used when focusing on fine-grained analysis or when the text's detailed aspects are crucial. For instance, smaller chunks might be used in sentiment analysis where understanding specific phrases or sentences is essential.</p></li> <li><p><strong>Larger Chunk Sizes:</strong> These are suitable for capturing broader context or when the interplay between different text parts is essential, such as document summarization or topic detection. Larger chunks help preserve the narrative flow or thematic elements of the text, which might need fixing with finer chunking.</p></li> </ul> <p>The selection of chunk size often depends on the balance between computational efficiency of memory and the need for contextual accuracy. Smaller chunks of memory can be processed faster but might lack context, while bigger chunks provide more context but can be computationally heavier to process.</p> <p><strong>Chunk overlap</strong> allows chunks to share some standard text with adjacent chunks. This technique ensures that no critical information is lost at the boundaries between chunks, especially in cases where the cut-off point between two more meaningful chunks might split important semantic or syntactic structures.</p> <ul> <li><strong>Role of Overlap:</strong> Overlap helps smooth the transitions between chunks, ensuring continuity of context, which is particularly useful in tasks like language modeling or when preparing data for training neural networks. For instance, if a sentence is cut off at the end of one chunk, starting the next chunk with the end of that sentence can provide continuity and context.</li> </ul> <p>Using chunk overlap can significantly enhance the quality of the analysis by reducing the risk of context loss and improving the coherence of <a href="https://zilliz.com/glossary/semantic-search">semantic search</a> in the output in <a href="https://zilliz.com/learn/top-5-nlp-applications">NLP applications</a>. However, it also increases the computational and cognitive load, since more text is processed multiple times, and this trade-off needs to be managed based on the specific requirements of the task.</p> <p>In RAG systems, the choice of chunking strategy can significantly impact the effectiveness of the retrieval process and, by extension, the quality of the generated outputs. Whether through fixed-size, semantic, or hybrid chunking, the goal called chunking remains to optimize how information is segmented, indexed, and retrieved to support efficient and accurate natural language generation. The strategic implementation of chunking can be the difference between a performant system and one that struggles with latency and relevance, highlighting its critical role in the architecture of advanced NLP solutions.</p> <h2 id="Chunking-and-Vectorization-in-Text-Retrieval" class="common-anchor-header"><strong>Chunking and Vectorization in Text Retrieval</strong><button data-href="#Chunking-and-Vectorization-in-Text-Retrieval" class="anchor-icon" translate="no"> <svg aria-hidden="true" focusable="false" height="20" version="1.1" viewBox="0 0 16 16" width="16" > <path fill="#0092E4" fill-rule="evenodd" d="M4 9h1v1H4c-1.5 0-3-1.69-3-3.5S2.55 3 4 3h4c1.45 0 3 1.69 3 3.5 0 1.41-.91 2.72-2 3.25V8.59c.58-.45 1-1.27 1-2.09C10 5.22 8.98 4 8 4H4c-.98 0-2 1.22-2 2.5S3 9 4 9zm9-3h-1v1h1c1 0 2 1.22 2 2.5S13.98 12 13 12H9c-.98 0-2-1.22-2-2.5 0-.83.42-1.64 1-2.09V6.25c-1.09.53-2 1.84-2 3.25C6 11.31 7.55 13 9 13h4c1.45 0 3-1.69 3-3.5S14.5 6 13 6z" ></path> </svg> </button></h2><p>Chunking significantly influences the effectiveness of vectorization in text retrieval systems. Proper chunking ensures that text vectors encapsulate the necessary semantic information, which enhances retrieval accuracy and efficiency. For instance, chunking strategies that align with the natural structure of the text, such as those that consider individual sentences or paragraphs, help maintain the integrity of the information when converted into vector form. This structured approach ensures that the vectors generated reflect actual content relevance, facilitating more precise retrieval in systems like RAG.</p> <h3 id="Tools-and-Technologies-for-Effective-Vectorization" class="common-anchor-header"><strong>Tools and Technologies for Effective Vectorization</strong><button data-href="#Tools-and-Technologies-for-Effective-Vectorization" class="anchor-icon" translate="no"> <svg aria-hidden="true" focusable="false" height="20" version="1.1" viewBox="0 0 16 16" width="16" > <path fill="#0092E4" fill-rule="evenodd" d="M4 9h1v1H4c-1.5 0-3-1.69-3-3.5S2.55 3 4 3h4c1.45 0 3 1.69 3 3.5 0 1.41-.91 2.72-2 3.25V8.59c.58-.45 1-1.27 1-2.09C10 5.22 8.98 4 8 4H4c-.98 0-2 1.22-2 2.5S3 9 4 9zm9-3h-1v1h1c1 0 2 1.22 2 2.5S13.98 12 13 12H9c-.98 0-2-1.22-2-2.5 0-.83.42-1.64 1-2.09V6.25c-1.09.53-2 1.84-2 3.25C6 11.31 7.55 13 9 13h4c1.45 0 3-1.69 3-3.5S14.5 6 13 6z" ></path> </svg> </button></h3><p>Effective vectorization of text heavily relies on the tools and <a href="https://zilliz.com/blog/choosing-the-right-embedding-model-for-your-data">embedding models</a> used. Popular models include <strong>Word2Vec</strong> and <strong>GloVe</strong> for word-level embeddings, while <a href="https://zilliz.com/learn/Sentence-Transformers-for-Long-Form-Text"><strong>BERT</strong></a> and <strong>GPT</strong> offer capabilities at sentence or paragraph levels, accommodating bigger chunks of text. These models are adept at capturing the nuanced semantic relationships within the text, making them highly suitable for sophisticated text retrieval systems. The choice of the embedding model should align with the granularity of the chunking strategy to optimize performance. For example, <a href="https://zilliz.com/learn/transforming-text-the-rise-of-sentence-transformers-in-nlp">sentence transformers</a> are particularly effective when used with the semantic context of chunking, as they are designed to handle and process sentence-level information efficiently.</p> <h3 id="Aligning-Chunking-Strategy-with-Vectorization-for-Optimal-Performance" class="common-anchor-header"><strong>Aligning Chunking Strategy with Vectorization for Optimal Performance</strong><button data-href="#Aligning-Chunking-Strategy-with-Vectorization-for-Optimal-Performance" class="anchor-icon" translate="no"> <svg aria-hidden="true" focusable="false" height="20" version="1.1" viewBox="0 0 16 16" width="16" > <path fill="#0092E4" fill-rule="evenodd" d="M4 9h1v1H4c-1.5 0-3-1.69-3-3.5S2.55 3 4 3h4c1.45 0 3 1.69 3 3.5 0 1.41-.91 2.72-2 3.25V8.59c.58-.45 1-1.27 1-2.09C10 5.22 8.98 4 8 4H4c-.98 0-2 1.22-2 2.5S3 9 4 9zm9-3h-1v1h1c1 0 2 1.22 2 2.5S13.98 12 13 12H9c-.98 0-2-1.22-2-2.5 0-.83.42-1.64 1-2.09V6.25c-1.09.53-2 1.84-2 3.25C6 11.31 7.55 13 9 13h4c1.45 0 3-1.69 3-3.5S14.5 6 13 6z" ></path> </svg> </button></h3><p>Aligning your chunking strategy with vectorization involves several key considerations:</p> <ul> <li><p><strong>Chunk Size and Model Capacity:</strong> It's crucial to match the chunk size with the capacity of the <a href="https://zilliz.com/glossary/vector-embeddings">vectorization</a> model. Optimized for shorter texts, models like BERT may require smaller, more concise chunks to operate effectively.</p></li> <li><p><strong>Consistency and Overlap:</strong> Ensuring consistency in chunk content and utilizing overlapping chunks can help maintain context between chunks, reducing the risk of losing critical information at the boundaries.</p></li> <li><p><strong>Iterative Refinement:</strong> Continuously refining the chunking and vectorization approaches based on system performance feedback is essential. This might involve adjusting chunk sizes or the vectorization model based on the system's retrieval accuracy and response time.</p></li> </ul> <h2 id="Implementing-Chunking-in-RAG-Pipelines" class="common-anchor-header"><strong>Implementing Chunking in RAG Pipelines</strong><button data-href="#Implementing-Chunking-in-RAG-Pipelines" class="anchor-icon" translate="no"> <svg aria-hidden="true" focusable="false" height="20" version="1.1" viewBox="0 0 16 16" width="16" > <path fill="#0092E4" fill-rule="evenodd" d="M4 9h1v1H4c-1.5 0-3-1.69-3-3.5S2.55 3 4 3h4c1.45 0 3 1.69 3 3.5 0 1.41-.91 2.72-2 3.25V8.59c.58-.45 1-1.27 1-2.09C10 5.22 8.98 4 8 4H4c-.98 0-2 1.22-2 2.5S3 9 4 9zm9-3h-1v1h1c1 0 2 1.22 2 2.5S13.98 12 13 12H9c-.98 0-2-1.22-2-2.5 0-.83.42-1.64 1-2.09V6.25c-1.09.53-2 1.84-2 3.25C6 11.31 7.55 13 9 13h4c1.45 0 3-1.69 3-3.5S14.5 6 13 6z" ></path> </svg> </button></h2><p>Implementing effective <a href="https://zilliz.com/learn/guide-to-chunking-strategies-for-rag">chunking in RAG</a> systems involves a nuanced understanding of how chunking interacts with other components, such as the retriever and generator. This interaction is pivotal for enhancing the efficiency and accuracy of chunking works the RAG system.</p> <ul> <li><p><strong>Chunking and the Retriever:</strong> The retriever's function is to identify and fetch the most relevant chunks of text based on the user query. Effective chunking strategies break down enormous datasets into manageable, coherent pieces that can be easily indexed and retrieved. For instance, chunking by document elements like titles or sections rather than mere token size can significantly improve the retriever's ability to pull contextually relevant information. This method ensures that each chunk encapsulates complete and standalone information, facilitating more accurate retrieval and reducing the retrieval of irrelevant information.</p></li> <li><p><strong>Chunking and the Generator:</strong> The generator uses this information to construct responses once the relevant chunks are retrieved. The quality and granularity of chunking directly influence the generator's output. Well-defined chunks ensure the generator has all the necessary context, which helps produce coherent and contextually rich responses. If chunks are too granular or poorly defined, it may lead to responses that are out of context or lack continuity.</p></li> </ul> <h3 id="Tools-and-Technologies-for-Building-and-Testing-Chunking-Strategies" class="common-anchor-header"><strong>Tools and Technologies for Building and Testing Chunking Strategies</strong><button data-href="#Tools-and-Technologies-for-Building-and-Testing-Chunking-Strategies" class="anchor-icon" translate="no"> <svg aria-hidden="true" focusable="false" height="20" version="1.1" viewBox="0 0 16 16" width="16" > <path fill="#0092E4" fill-rule="evenodd" d="M4 9h1v1H4c-1.5 0-3-1.69-3-3.5S2.55 3 4 3h4c1.45 0 3 1.69 3 3.5 0 1.41-.91 2.72-2 3.25V8.59c.58-.45 1-1.27 1-2.09C10 5.22 8.98 4 8 4H4c-.98 0-2 1.22-2 2.5S3 9 4 9zm9-3h-1v1h1c1 0 2 1.22 2 2.5S13.98 12 13 12H9c-.98 0-2-1.22-2-2.5 0-.83.42-1.64 1-2.09V6.25c-1.09.53-2 1.84-2 3.25C6 11.31 7.55 13 9 13h4c1.45 0 3-1.69 3-3.5S14.5 6 13 6z" ></path> </svg> </button></h3><p>Several tools and platforms facilitate the development and testing of chunking strategies within RAG systems:</p> <ul> <li><p><strong>LangChain and <a href="https://zilliz.com/partners/llamaindex">LlamaIndex</a>:</strong> These tools provide various chunking strategies, including dynamic chunk sizing and overlapping, which are crucial for maintaining contextual continuity between chunks. They allow for the customization of chunk sizes and overlap based on the application's specific needs, which can be tailored to optimize both retrieval and generation processes in RAG systems.</p></li> <li><p><strong>Preprocessing pipeline APIs by Unstructured:</strong> These pipelines enhance RAG performance by employing sophisticated document understanding techniques, such as chunking by document element. This method is particularly effective for complex document types with varied structures, as it ensures that only relevant data is considered for retrieval and generation, enhancing both the accuracy and efficiency of the RAG system.</p></li> <li><p><strong>Zilliz Cloud</strong>: Zilliz Cloud includes a capability called Pipelines that streamlines the conversion of <a href="https://zilliz.com/glossary/unstructured-data">unstructured data</a> into vector embeddings, which are then stored in the Zilliz Cloud vector database for efficient indexing and retrieval. There are features that allow you to choose or customize the <a href="https://docs.zilliz.com/docs/pipelines-ingest-search-delete-data">splitter</a> that is included. By default, Zilliz Cloud Pipelines uses &quot;\n\n&quot;, &quot;\n&quot;, &quot; &quot;, &quot;&quot; as separators. You can also choose to split the document by sentences (use &quot;.&quot;, &quot;&quot; as separators ), paragraphs (use &quot;\n\n&quot;, &quot;&quot; as separators), lines (use &quot;\n&quot;, &quot;&quot; as separators), or a list of customized strings.</p></li> </ul> <p>Incorporating these tools into the <a href="https://zilliz.com/learn/how-to-enhance-the-performance-of-your-rag-pipeline">RAG pipeline</a> allows developers to experiment with different chunking strategies and directly observe their impact on system performance. This experimentation can significantly improve how information is retrieved and processed, ultimately enhancing the overall effectiveness of the RAG system.</p> <h2 id="Performance-Optimization-in-RAG-Systems-Through-Chunking-Strategies" class="common-anchor-header"><strong>Performance Optimization in RAG Systems Through Chunking Strategies</strong><button data-href="#Performance-Optimization-in-RAG-Systems-Through-Chunking-Strategies" class="anchor-icon" translate="no"> <svg aria-hidden="true" focusable="false" height="20" version="1.1" viewBox="0 0 16 16" width="16" > <path fill="#0092E4" fill-rule="evenodd" d="M4 9h1v1H4c-1.5 0-3-1.69-3-3.5S2.55 3 4 3h4c1.45 0 3 1.69 3 3.5 0 1.41-.91 2.72-2 3.25V8.59c.58-.45 1-1.27 1-2.09C10 5.22 8.98 4 8 4H4c-.98 0-2 1.22-2 2.5S3 9 4 9zm9-3h-1v1h1c1 0 2 1.22 2 2.5S13.98 12 13 12H9c-.98 0-2-1.22-2-2.5 0-.83.42-1.64 1-2.09V6.25c-1.09.53-2 1.84-2 3.25C6 11.31 7.55 13 9 13h4c1.45 0 3-1.69 3-3.5S14.5 6 13 6z" ></path> </svg> </button></h2><p>Optimizing RAG systems involves carefully monitoring and evaluating how different chunking strategies impact performance. This optimization ensures that the system not only retrieves relevant information quickly but also generates coherent and contextually appropriate responses when processing information.</p> <h3 id="Monitoring-and-Evaluating-the-Impact-of-Different-Chunking-Strategies" class="common-anchor-header"><strong>Monitoring and Evaluating the Impact of Different Chunking Strategies</strong><button data-href="#Monitoring-and-Evaluating-the-Impact-of-Different-Chunking-Strategies" class="anchor-icon" translate="no"> <svg aria-hidden="true" focusable="false" height="20" version="1.1" viewBox="0 0 16 16" width="16" > <path fill="#0092E4" fill-rule="evenodd" d="M4 9h1v1H4c-1.5 0-3-1.69-3-3.5S2.55 3 4 3h4c1.45 0 3 1.69 3 3.5 0 1.41-.91 2.72-2 3.25V8.59c.58-.45 1-1.27 1-2.09C10 5.22 8.98 4 8 4H4c-.98 0-2 1.22-2 2.5S3 9 4 9zm9-3h-1v1h1c1 0 2 1.22 2 2.5S13.98 12 13 12H9c-.98 0-2-1.22-2-2.5 0-.83.42-1.64 1-2.09V6.25c-1.09.53-2 1.84-2 3.25C6 11.31 7.55 13 9 13h4c1.45 0 3-1.69 3-3.5S14.5 6 13 6z" ></path> </svg> </button></h3><ol> <li><strong>Setting Performance Benchmarks:</strong> Before modifying chunking strategies, it's crucial to establish baseline performance metrics. This might include metrics like response time, <a href="https://zilliz.com/learn/what-is-information-retrieval">information retrieval</a> accuracy, and the generated text's coherence.</li> </ol> <ol> <li><strong>Experimentation:</strong> Implement different chunking strategies—such as fixed-size, semantic, and dynamic chunking—and measure how each impacts performance. This experimental phase should be controlled and systematic to isolate the effects of chunking from other variables.</li> </ol> <ol> <li><strong>Continuous Monitoring:</strong> Use logging and monitoring tools to track performance over time. This ongoing data collection is vital for understanding long-term trends and the stability of improvements under different operational conditions.</li> </ol> <h3 id="Metrics-and-Tools-for-Assessing-Chunking-Effectiveness" class="common-anchor-header"><strong>Metrics and Tools for Assessing Chunking Effectiveness</strong><button data-href="#Metrics-and-Tools-for-Assessing-Chunking-Effectiveness" class="anchor-icon" translate="no"> <svg aria-hidden="true" focusable="false" height="20" version="1.1" viewBox="0 0 16 16" width="16" > <path fill="#0092E4" fill-rule="evenodd" d="M4 9h1v1H4c-1.5 0-3-1.69-3-3.5S2.55 3 4 3h4c1.45 0 3 1.69 3 3.5 0 1.41-.91 2.72-2 3.25V8.59c.58-.45 1-1.27 1-2.09C10 5.22 8.98 4 8 4H4c-.98 0-2 1.22-2 2.5S3 9 4 9zm9-3h-1v1h1c1 0 2 1.22 2 2.5S13.98 12 13 12H9c-.98 0-2-1.22-2-2.5 0-.83.42-1.64 1-2.09V6.25c-1.09.53-2 1.84-2 3.25C6 11.31 7.55 13 9 13h4c1.45 0 3-1.69 3-3.5S14.5 6 13 6z" ></path> </svg> </button></h3><p><strong>Metrics:</strong></p> <ul> <li><p><strong>Precision and Recall:</strong> These metrics are critical for evaluating the accuracy and completeness of the information retrieved by the RAG system.</p></li> <li><p><strong>Response Time:</strong> Measures the time taken from receiving a query to providing an answer, indicating the efficiency of the retrieval process.</p></li> <li><p><strong>Consistency and Coherence:</strong> The logical flow and relevance of text generated based on the chunked inputs are crucial for assessing chunking effectiveness in generative tasks.</p></li> </ul> <p><strong>Tools:</strong></p> <ul> <li><p><strong>Analytics Dashboards:</strong> Tools like <strong>Grafana</strong> or <strong>Kibana</strong> can be integrated to visualize performance metrics in real-time.</p></li> <li><p><strong>Profiling Software:</strong> Profiling tools specific to machine learning workflows, such as <strong>Profiler</strong> or <strong>TensorBoard</strong>, can help identify bottlenecks at the chunking stage.</p></li> </ul> <h3 id="Strategies-for-Tuning-and-Refining-Chunking-Parameters-Based-on-Performance-Data" class="common-anchor-header"><strong>Strategies for Tuning and Refining Chunking Parameters Based on Performance Data</strong><button data-href="#Strategies-for-Tuning-and-Refining-Chunking-Parameters-Based-on-Performance-Data" class="anchor-icon" translate="no"> <svg aria-hidden="true" focusable="false" height="20" version="1.1" viewBox="0 0 16 16" width="16" > <path fill="#0092E4" fill-rule="evenodd" d="M4 9h1v1H4c-1.5 0-3-1.69-3-3.5S2.55 3 4 3h4c1.45 0 3 1.69 3 3.5 0 1.41-.91 2.72-2 3.25V8.59c.58-.45 1-1.27 1-2.09C10 5.22 8.98 4 8 4H4c-.98 0-2 1.22-2 2.5S3 9 4 9zm9-3h-1v1h1c1 0 2 1.22 2 2.5S13.98 12 13 12H9c-.98 0-2-1.22-2-2.5 0-.83.42-1.64 1-2.09V6.25c-1.09.53-2 1.84-2 3.25C6 11.31 7.55 13 9 13h4c1.45 0 3-1.69 3-3.5S14.5 6 13 6z" ></path> </svg> </button></h3><ol> <li><strong>Data-Driven Adjustments:</strong> Use the collected performance data to decide which chunking parameters (e.g., size, overlap) to adjust. For example, if larger chunks are slowing down the system but increasing accuracy, a balance needs to be found that optimizes both aspects.</li> </ol> <ol> <li><strong>A/B Testing:</strong> Conduct A/B testing using different chunking strategies to directly compare their impact on system performance. This approach allows for side-by-side comparisons and more confident decision-making.</li> </ol> <ol> <li><strong>Feedback Loops:</strong> Implement a feedback system where the outputs of the RAG are evaluated either by users or through automated systems to provide continuous feedback on the quality of the generated content. This feedback can be used to fine-tune chunking parameters dynamically.</li> </ol> <ol> <li><strong>Machine Learning Optimization Algorithms:</strong> Utilize machine learning techniques such as reinforcement learning or genetic algorithms to find optimal chunking configurations based on performance metrics automatically.</li> </ol> <p>By carefully monitoring, evaluating, and continuously refining the chunking strategies in RAG systems, developers can significantly enhance their systems' efficiency and effectiveness.</p> <h2 id="Case-Studies-on-Successful-RAG-Implementations-with-Innovative-Chunking-Strategies" class="common-anchor-header"><strong>Case Studies on Successful RAG Implementations with Innovative Chunking Strategies</strong><button data-href="#Case-Studies-on-Successful-RAG-Implementations-with-Innovative-Chunking-Strategies" class="anchor-icon" translate="no"> <svg aria-hidden="true" focusable="false" height="20" version="1.1" viewBox="0 0 16 16" width="16" > <path fill="#0092E4" fill-rule="evenodd" d="M4 9h1v1H4c-1.5 0-3-1.69-3-3.5S2.55 3 4 3h4c1.45 0 3 1.69 3 3.5 0 1.41-.91 2.72-2 3.25V8.59c.58-.45 1-1.27 1-2.09C10 5.22 8.98 4 8 4H4c-.98 0-2 1.22-2 2.5S3 9 4 9zm9-3h-1v1h1c1 0 2 1.22 2 2.5S13.98 12 13 12H9c-.98 0-2-1.22-2-2.5 0-.83.42-1.64 1-2.09V6.25c-1.09.53-2 1.84-2 3.25C6 11.31 7.55 13 9 13h4c1.45 0 3-1.69 3-3.5S14.5 6 13 6z" ></path> </svg> </button></h2><ul> <li><p><strong>Case Study 1 - Dynamic Windowed Summarization:</strong> One example of a successful RAG implementation involved an additive preprocessing technique called windowed summarization. This approach enriched text chunks with summaries of adjacent chunks to provide a broader context. This method allowed the system to adjust the &quot;window size&quot; dynamically, exploring different scopes of context, which enhanced the understanding of each chunk. The enriched context improved the quality of responses by making them more relevant and contextually nuanced. This case highlighted the benefits of context-enriched chunking in a RAG setup, where the retrieval component could leverage broader contextual cues to enhance answer quality and relevance (Optimizing Retrieval-Augmented Generation with Advanced Chunking Techniques: <a href="https://antematter.io/blogs/optimizing-rag-advanced-chunking-techniques-study">A Comparative Study</a>).</p></li> <li><p><strong>Case Study 2 - Advanced Semantic Chunking:</strong> Advanced Semantic Chunking: Another successful implementation of a successful RAG implementation involves advanced semantic chunking techniques to enhance retrieval performance. By dividing documents into semantically coherent chunks rather than merely based on size or token count, the system significantly improved its ability to retrieve relevant information. This strategy ensured each chunk maintained its contextual integrity, leading to more accurate and coherent generation outputs. Implementing such chunking techniques required a deep understanding of both the content structure and the specific demands of the retrieval and generation processes involved in the RAG system (<a href="https://www.rungalileo.io/blog/mastering-rag-advanced-chunking-techniques-for-llm-applications">Mastering RAG: Advanced Chunking Techniques for LLM Applications</a>).</p></li> </ul> <h2 id="Conclusion-The-Strategic-Significance-of-Chunking-in-RAG-Systems" class="common-anchor-header"><strong>Conclusion: The Strategic Significance of Chunking in RAG Systems</strong><button data-href="#Conclusion-The-Strategic-Significance-of-Chunking-in-RAG-Systems" class="anchor-icon" translate="no"> <svg aria-hidden="true" focusable="false" height="20" version="1.1" viewBox="0 0 16 16" width="16" > <path fill="#0092E4" fill-rule="evenodd" d="M4 9h1v1H4c-1.5 0-3-1.69-3-3.5S2.55 3 4 3h4c1.45 0 3 1.69 3 3.5 0 1.41-.91 2.72-2 3.25V8.59c.58-.45 1-1.27 1-2.09C10 5.22 8.98 4 8 4H4c-.98 0-2 1.22-2 2.5S3 9 4 9zm9-3h-1v1h1c1 0 2 1.22 2 2.5S13.98 12 13 12H9c-.98 0-2-1.22-2-2.5 0-.83.42-1.64 1-2.09V6.25c-1.09.53-2 1.84-2 3.25C6 11.31 7.55 13 9 13h4c1.45 0 3-1.69 3-3.5S14.5 6 13 6z" ></path> </svg> </button></h2><p>We've explored various facets of chunking strategies within Retrieval-Augmented Generation (RAG) systems. From understanding the basics of the chunking process to diving into advanced techniques and real-world applications, with emphasis the role chunking plays in the performance of RAG systems.</p> <h2 id="Recap-of-Key-Points" class="common-anchor-header"><strong>Recap of Key Points</strong><button data-href="#Recap-of-Key-Points" class="anchor-icon" translate="no"> <svg aria-hidden="true" focusable="false" height="20" version="1.1" viewBox="0 0 16 16" width="16" > <path fill="#0092E4" fill-rule="evenodd" d="M4 9h1v1H4c-1.5 0-3-1.69-3-3.5S2.55 3 4 3h4c1.45 0 3 1.69 3 3.5 0 1.41-.91 2.72-2 3.25V8.59c.58-.45 1-1.27 1-2.09C10 5.22 8.98 4 8 4H4c-.98 0-2 1.22-2 2.5S3 9 4 9zm9-3h-1v1h1c1 0 2 1.22 2 2.5S13.98 12 13 12H9c-.98 0-2-1.22-2-2.5 0-.83.42-1.64 1-2.09V6.25c-1.09.53-2 1.84-2 3.25C6 11.31 7.55 13 9 13h4c1.45 0 3-1.69 3-3.5S14.5 6 13 6z" ></path> </svg> </button></h2><ul> <li><p><strong>Basic Principles:</strong> Chunking refers to breaking down large text datasets into manageable pieces that improve the efficiency of information retrieval and text generation processes.</p></li> <li><p><strong>Chunking Strategies:</strong> Various chunking strategies like fixed-size, semantic, and dynamic chunking can be implemented, based on the use case, its advantages, scenarios of best use and disadvantages.</p></li> </ul> <ul> <li><p><strong>Impact on RAG Systems:</strong> The interaction between chunking and other RAG components such as the retriever and generator should be assessed, as different chunking approaches can influence the overall system performance.</p></li> <li><p><strong>Tools and Metrics:</strong> The tools and metrics that can be used to monitor and evaluate the effectiveness of chunking strategies are critical for ongoing optimization efforts.</p></li> <li><p><strong>Real-World Case Studies:</strong> Examples from successful implementations illustrated how innovative chunking strategies can lead to significant improvements in RAG systems.</p></li> </ul> <h2 id="Final-Thoughts-on-Choosing-the-Right-Chunking-Strategy" class="common-anchor-header"><strong>Final Thoughts on Choosing the Right Chunking Strategy</strong><button data-href="#Final-Thoughts-on-Choosing-the-Right-Chunking-Strategy" class="anchor-icon" translate="no"> <svg aria-hidden="true" focusable="false" height="20" version="1.1" viewBox="0 0 16 16" width="16" > <path fill="#0092E4" fill-rule="evenodd" d="M4 9h1v1H4c-1.5 0-3-1.69-3-3.5S2.55 3 4 3h4c1.45 0 3 1.69 3 3.5 0 1.41-.91 2.72-2 3.25V8.59c.58-.45 1-1.27 1-2.09C10 5.22 8.98 4 8 4H4c-.98 0-2 1.22-2 2.5S3 9 4 9zm9-3h-1v1h1c1 0 2 1.22 2 2.5S13.98 12 13 12H9c-.98 0-2-1.22-2-2.5 0-.83.42-1.64 1-2.09V6.25c-1.09.53-2 1.84-2 3.25C6 11.31 7.55 13 9 13h4c1.45 0 3-1.69 3-3.5S14.5 6 13 6z" ></path> </svg> </button></h2><p>Choosing the appropriate advanced RAG techniques is paramount in enhancing the functionality and efficiency of RAG systems. The right strategy utilize chunking ensures that the system not only retrieves the most relevant information but also generates coherent and contextually rich responses to relevant documents. The impact of well-implemented chunking strategies on RAG performance can influence the precision of information retrieval and the quality of content generation.</p> <h2 id="Further-Reading-and-Resources-on-RAG-and-Chunking" class="common-anchor-header"><strong>Further Reading and Resources on RAG and Chunking</strong><button data-href="#Further-Reading-and-Resources-on-RAG-and-Chunking" class="anchor-icon" translate="no"> <svg aria-hidden="true" focusable="false" height="20" version="1.1" viewBox="0 0 16 16" width="16" > <path fill="#0092E4" fill-rule="evenodd" d="M4 9h1v1H4c-1.5 0-3-1.69-3-3.5S2.55 3 4 3h4c1.45 0 3 1.69 3 3.5 0 1.41-.91 2.72-2 3.25V8.59c.58-.45 1-1.27 1-2.09C10 5.22 8.98 4 8 4H4c-.98 0-2 1.22-2 2.5S3 9 4 9zm9-3h-1v1h1c1 0 2 1.22 2 2.5S13.98 12 13 12H9c-.98 0-2-1.22-2-2.5 0-.83.42-1.64 1-2.09V6.25c-1.09.53-2 1.84-2 3.25C6 11.31 7.55 13 9 13h4c1.45 0 3-1.69 3-3.5S14.5 6 13 6z" ></path> </svg> </button></h2><ul> <li><p>For a foundational understanding, the original paper by Lewis et al. on RAG is essential. It offers in-depth explanations of the mechanisms and applications of RAG in knowledge-intensive NLP tasks.</p></li> <li><p>&quot;Mastering RAG: Advanced Chunking Techniques for LLM Applications&quot; on Galileo provides a deeper dive into various chunking strategies and their impact on RAG system performance, emphasizing the integration of <a href="https://zilliz.com/glossary/large-language-models-(llms)">LLMs</a> for enhanced retrieval and generation processes.</p></li> <li><p>Joining AI and NLP communities such as those found on Stack Overflow, Reddit (r/MachineLearning), or Towards AI can provide ongoing support and discussion forums. These platforms allow practitioners to share insights, ask questions, and find solutions related to RAG and chunking methods</p></li> </ul> </div><div class="learnDetail_updateAt__h06TJ">Updated on Mar 12, 2025</div><ul class="learnDetail_authorsList__1H6GG"><li><span class="learnDetail_avatarWrapper__M_vVs"><img src="https://assets.zilliz.com/Male_Author_526de0f08d.jpeg" alt="Rahul "/></span><div><a class="learnDetail_name__YcFY9" href="/authors/Rahul_">Rahul </a><p class="learnDetail_introduction__LE63i"></p></div></li></ul><div class="learnDetail_footerNavWrapper__jif_z"><div><a class="learnDetail_linkBtn__rGWom learnDetail_previousBtn__OORHy" href="/learn/how-to-build-rag-system-using-llama3-ollama-dspy-milvus"><svg width="16" height="17" viewBox="0 0 16 17" fill="none" xmlns="http://www.w3.org/2000/svg"><path d="M10.7817 8.15636L7.20566 4.58036L8.14833 3.6377L13.3337 8.82303L8.14833 14.0084L7.20566 13.0657L10.7817 9.4897H2.66699V8.15636H10.7817Z" fill="black"></path></svg>previous</a></div><div><a class="learnDetail_linkBtn__rGWom" href="/learn/improve-rag-and-information-retrieval-with-hyde-hypothetical-document-embeddings">Next: Improving Information Retrieval and RAG with Hypothetical Document Embeddings (HyDE)<svg width="16" height="17" viewBox="0 0 16 17" fill="none" xmlns="http://www.w3.org/2000/svg"><path d="M10.7817 8.15636L7.20566 4.58036L8.14833 3.6377L13.3337 8.82303L8.14833 14.0084L7.20566 13.0657L10.7817 9.4897H2.66699V8.15636H10.7817Z" fill="black"></path></svg></a></div></div></div><div class="globalArticleCTASection_sectionContainer__z7vw5 learnDetail_rightSideBar__N0jto"><ul class="globalArticleCTASection_listWrapper__l52HF"><h3 class="globalArticleCTASection_anchorTitle__iGSh_">Content</h3><li><a class="globalArticleCTASection_anchorLink__JXvsH" href="/learn/guide-to-chunking-strategies-for-rag#What-is-Retrieval-Augmented-Generation-RAG">What is Retrieval Augmented Generation (RAG)?</a></li><li><a class="globalArticleCTASection_anchorLink__JXvsH" href="/learn/guide-to-chunking-strategies-for-rag#Significance-of-RAG-in-NLP">Significance of RAG in NLP</a></li><li><a class="globalArticleCTASection_anchorLink__JXvsH" href="/learn/guide-to-chunking-strategies-for-rag#Chunking">Chunking</a></li><li><a class="globalArticleCTASection_anchorLink__JXvsH" href="/learn/guide-to-chunking-strategies-for-rag#Detailed-Exploration-of-Chunking-Strategies-in-RAG-Systems">Detailed Exploration of Chunking Strategies in RAG Systems</a></li><li><a class="globalArticleCTASection_anchorLink__JXvsH" href="/learn/guide-to-chunking-strategies-for-rag#Chunking-and-Vectorization-in-Text-Retrieval">**Chunking and Vectorization in Text Retrieval**</a></li><li><a class="globalArticleCTASection_anchorLink__JXvsH" href="/learn/guide-to-chunking-strategies-for-rag#Implementing-Chunking-in-RAG-Pipelines">**Implementing Chunking in RAG Pipelines**</a></li><li><a class="globalArticleCTASection_anchorLink__JXvsH" href="/learn/guide-to-chunking-strategies-for-rag#Performance-Optimization-in-RAG-Systems-Through-Chunking-Strategies">**Performance Optimization in RAG Systems Through Chunking Strategies**</a></li><li><a class="globalArticleCTASection_anchorLink__JXvsH" href="/learn/guide-to-chunking-strategies-for-rag#Case-Studies-on-Successful-RAG-Implementations-with-Innovative-Chunking-Strategies">**Case Studies on Successful RAG Implementations with Innovative Chunking Strategies**</a></li><li><a class="globalArticleCTASection_anchorLink__JXvsH" href="/learn/guide-to-chunking-strategies-for-rag#Conclusion-The-Strategic-Significance-of-Chunking-in-RAG-Systems">**Conclusion: The Strategic Significance of Chunking in RAG Systems**</a></li><li><a class="globalArticleCTASection_anchorLink__JXvsH" href="/learn/guide-to-chunking-strategies-for-rag#Recap-of-Key-Points">**Recap of Key Points**</a></li><li><a class="globalArticleCTASection_anchorLink__JXvsH" href="/learn/guide-to-chunking-strategies-for-rag#Final-Thoughts-on-Choosing-the-Right-Chunking-Strategy">**Final Thoughts on Choosing the Right Chunking Strategy**</a></li><li><a class="globalArticleCTASection_anchorLink__JXvsH" href="/learn/guide-to-chunking-strategies-for-rag#Further-Reading-and-Resources-on-RAG-and-Chunking">**Further Reading and Resources on RAG and Chunking**</a></li></ul><div class="globalArticleCTASection_trialContainer___GL1h"><h4 class="globalArticleCTASection_trialTitle__5LCX9">Start Free, Scale Easily</h4><p class="globalArticleCTASection_trialContent__VfHaQ">Try the fully-managed vector database built for your GenAI applications.</p><a rel="noreferrer noopener" target="_blank" title="" class="BaseButton_root__SFmw5 BaseButton_contained__2JisA globalArticleCTASection_trialButton__o7PQn" href="https://cloud.zilliz.com/signup?utm_page=guide-to-chunking-strategies-for-rag&amp;utm_button=right_CTA">Try Zilliz Cloud for Free</a></div><div class="share_shareSection__JdOu2"><h4 class="share_shareTitle__cRU4n">Share this article</h4><div class="share_mediasWrapper__IYc0b"><button aria-label="twitter" class="react-share__ShareButton share_btn__pkIal share_liteIcon__zji87" style="background-color:transparent;border:none;padding:0;font:inherit;color:inherit;cursor:pointer"><svg height="30" width="30" viewBox="0 0 30 30" fill="none" xmlns="http://www.w3.org/2000/svg"><circle cx="15" cy="15" r="15" fill="white"></circle><path d="M18.244 2.25h3.308l-7.227 8.26 8.502 11.24H16.17l-5.214-6.817L4.99 21.75H1.68l7.73-8.835L1.254 2.25H8.08l4.713 6.231zm-1.161 17.52h1.833L7.084 4.126H5.117z" fill="black" transform="translate(7, 7) scale(0.75)"></path></svg></button><button aria-label="facebook" class="react-share__ShareButton share_btn__pkIal share_liteIcon__zji87" style="background-color:transparent;border:none;padding:0;font:inherit;color:inherit;cursor:pointer"><svg width="30" height="30" viewBox="0 0 30 30" fill="none" xmlns="http://www.w3.org/2000/svg"><circle cx="15" cy="15" r="15" fill="white"></circle><path d="M13 12.3333H11V15H13V23H16.3333V15H18.7333L19 12.3333H16.3333V11.2C16.3333 10.6 16.4667 10.3333 17.0667 10.3333H19V7H16.4667C14.0667 7 13 8.06667 13 10.0667V12.3333Z" fill="black"></path></svg></button><button class="share_btn__pkIal share_liteIcon__zji87"><a target="_new"><svg width="30" height="31" viewBox="0 0 30 31" fill="none" xmlns="http://www.w3.org/2000/svg"><circle cx="15" cy="15.6" r="15" fill="white"></circle><path fill-rule="evenodd" clip-rule="evenodd" d="M10.5 8.34998C10.5 9.31647 9.7165 10.1 8.75 10.1C7.7835 10.1 7 9.31647 7 8.34998C7 7.38348 7.7835 6.59998 8.75 6.59998C9.7165 6.59998 10.5 7.38348 10.5 8.34998ZM7 11.6H10.578V22.6H7V11.6ZM20.2998 11.7212C20.2954 11.7197 20.2909 11.7182 20.2864 11.7168C20.2616 11.7085 20.2367 11.7003 20.21 11.693C20.162 11.682 20.114 11.673 20.065 11.665C19.875 11.627 19.667 11.6 19.423 11.6C17.337 11.6 16.014 13.117 15.578 13.703V11.6H12V22.6H15.578V16.6C15.578 16.6 18.282 12.834 19.423 15.6V22.6H23V15.177C23 13.515 21.861 12.13 20.324 11.729C20.3159 11.7264 20.3078 11.7238 20.2998 11.7212Z" fill="black"></path></svg></a></button><button class="share_btn__pkIal share_shareBtn__uoSKk share_liteIcon__zji87" aria-label="Share Link"><svg width="30" height="30" viewBox="0 0 30 30" fill="none" xmlns="http://www.w3.org/2000/svg"><circle cx="15" cy="15" r="15" fill="white"></circle><path d="M19.1221 8.9396C19.1221 8.42067 19.5358 8 20.0462 8C20.6346 8 21.2128 8.12022 21.7755 8.34908C22.388 8.59816 22.8593 8.96779 23.2871 9.40272C23.7148 9.83765 24.0784 10.3169 24.3233 10.9396C24.5484 11.5118 24.6667 12.0997 24.6667 12.698C24.6667 13.2963 24.5484 13.8842 24.3233 14.4563C24.0814 15.0712 23.7239 15.5463 23.3032 15.9769L22.3933 16.9945C22.3835 17.0055 22.3734 17.0163 22.363 17.0268L19.4059 20.0335C18.9782 20.4685 18.5068 20.8381 17.8944 21.0872C17.3316 21.316 16.7534 21.4362 16.165 21.4362C15.5766 21.4362 14.9984 21.316 14.4357 21.0872C13.8233 20.8381 13.3519 20.4685 12.9241 20.0335C12.4964 19.5986 12.1328 19.1193 11.8879 18.4966C11.6585 17.9134 11.5446 17.325 11.5446 16.6443C11.5446 16.046 11.6628 15.4581 11.8879 14.8859C12.1328 14.2633 12.4964 13.784 12.9241 13.349L13.9406 12.3155C14.3015 11.9485 14.8866 11.9485 15.2475 12.3155C15.6084 12.6824 15.6084 13.2773 15.2475 13.6443L14.231 14.6778C13.9195 14.9946 13.7285 15.2669 13.6039 15.5839C13.4593 15.9513 13.3927 16.303 13.3927 16.6443C13.3927 17.0911 13.4637 17.4423 13.6039 17.7987C13.7285 18.1156 13.9195 18.388 14.231 18.7047C14.5425 19.0215 14.8104 19.2156 15.1221 19.3424C15.4834 19.4893 15.8293 19.557 16.165 19.557C16.5007 19.557 16.8466 19.4893 17.208 19.3424C17.5196 19.2156 17.7875 19.0215 18.099 18.7047L21.0406 15.7138L21.9499 14.6968C21.9597 14.6858 21.9699 14.675 21.9802 14.6645C22.2918 14.3477 22.4827 14.0753 22.6073 13.7584C22.7519 13.391 22.8185 13.0393 22.8185 12.698C22.8185 12.3567 22.7519 12.005 22.6073 11.6375C22.4827 11.3206 22.2918 11.0483 21.9802 10.7315C21.6687 10.4148 21.4008 10.2206 21.0891 10.0939C20.7278 9.9469 20.3819 9.87919 20.0462 9.87919C19.5358 9.87919 19.1221 9.45852 19.1221 8.9396ZM14.5941 10.349C14.2584 10.349 13.9125 10.4167 13.5511 10.5637C13.2394 10.6904 12.9716 10.8846 12.66 11.2013L9.62608 14.2862L8.71678 15.3032C8.70692 15.3142 8.6968 15.325 8.68644 15.3355C8.37491 15.6523 8.18399 15.9247 8.05932 16.2416C7.91477 16.609 7.84818 16.9607 7.84818 17.302C7.84818 17.6433 7.91477 17.995 8.05932 18.3625C8.18399 18.6794 8.37491 18.9517 8.68644 19.2685C8.99796 19.5852 9.26584 19.7794 9.57752 19.9061C9.93889 20.0531 10.2848 20.1208 10.6205 20.1208C11.1308 20.1208 11.5446 20.5415 11.5446 21.0604C11.5446 21.5793 11.1308 22 10.6205 22C10.0321 22 9.45385 21.8798 8.89112 21.6509C8.27871 21.4018 7.80732 21.0322 7.37957 20.5973C6.95182 20.1624 6.58829 19.6831 6.34332 19.0604C6.11823 18.4882 6 17.9003 6 17.302C6 16.7037 6.11823 16.1158 6.34332 15.5437C6.58521 14.9288 6.94272 14.4537 7.36351 14.0231L8.27332 13.0055C8.28318 12.9945 8.2933 12.9837 8.30366 12.9732L11.3532 9.87252C11.7809 9.43759 12.2523 9.06795 12.8647 8.81888C13.4274 8.59001 14.0057 8.4698 14.5941 8.4698C15.1825 8.4698 15.7607 8.59001 16.3234 8.81888C16.9358 9.06795 17.4072 9.43759 17.8349 9.87252C18.2627 10.3074 18.6262 10.7867 18.8712 11.4094C19.0963 11.9816 19.2145 12.5695 19.2145 13.1678C19.2145 13.7661 19.0963 14.354 18.8712 14.9261C18.629 15.5417 18.271 16.0171 17.8496 16.4481L16.8462 17.5611C16.5013 17.9436 15.9168 17.9695 15.5406 17.6188C15.1644 17.2682 15.139 16.6738 15.4838 16.2913L16.5003 15.1637C16.5094 15.1537 16.5186 15.1439 16.5281 15.1343C16.8396 14.8175 17.0305 14.5451 17.1552 14.2282C17.2997 13.8608 17.3663 13.5091 17.3663 13.1678C17.3663 12.8265 17.2997 12.4748 17.1552 12.1073C17.0305 11.7904 16.8396 11.5181 16.5281 11.2013C16.2166 10.8846 15.9487 10.6904 15.637 10.5637C15.2756 10.4167 14.9297 10.349 14.5941 10.349Z" fill="black"></path></svg><span class="share_copied__4rKDS">Copied</span></button></div></div></div></div><section class="learnDetail_recommendSection__NBE0x"><h2 class="learnDetail_recommendTitle__WzsJ1">Keep Reading</h2><ul class="learnDetail_recommendArticles__0Csna"><a class="learnDetail_pickerItem__Qkcwx" href="/learn/optimize-rag-with-rerankers-the-role-and-tradeoffs"><img src="https://assets.zilliz.com/Optimizing_RAG_with_Rerankers_The_Role_and_Trade_offs_2a9a90f6af.png" alt="Optimizing RAG with Rerankers: The Role and Trade-offs "/><div class="learnDetail_contentPart__zQTkO"><div><h3 class="learnDetail_articleTitle__pYwnn">Optimizing RAG with Rerankers: The Role and Trade-offs </h3><p class="learnDetail_articleDesc__iZ5v7">Rerankers can enhance the accuracy and relevance of answers in RAG systems, but these benefits come with increased latency and computational costs.</p></div><button class="CommonTransitionButton_transitionButton__4vdrN"><span class="CommonTransitionButton_label__4YgGh">Read Now</span><svg width="16" height="17" viewBox="0 0 16 17" fill="none" xmlns="http://www.w3.org/2000/svg"><path d="M10.7817 8.15636L7.20566 4.58036L8.14833 3.6377L13.3337 8.82303L8.14833 14.0084L7.20566 13.0657L10.7817 9.4897H2.66699V8.15636H10.7817Z" fill="black"></path></svg></button></div></a><a class="learnDetail_pickerItem__Qkcwx" href="/learn/enhancing-chatgpt-with-milvus"><img src="https://assets.zilliz.com/Enhancing_Chat_GPT_with_Milvus_099d0488f7.png" alt="Enhancing ChatGPT with Milvus: Powering AI with Long-Term Memory"/><div class="learnDetail_contentPart__zQTkO"><div><h3 class="learnDetail_articleTitle__pYwnn">Enhancing ChatGPT with Milvus: Powering AI with Long-Term Memory</h3><p class="learnDetail_articleDesc__iZ5v7">By integrating GPTCache and Milvus with ChatGPT, businesses can create a more robust and efficient AI-powered support system. This approach leverages the advanced capabilities of generative AI and introduces a form of long-term memory, allowing the AI to recall and reuse information effectively.</p></div><button class="CommonTransitionButton_transitionButton__4vdrN"><span class="CommonTransitionButton_label__4YgGh">Read Now</span><svg width="16" height="17" viewBox="0 0 16 17" fill="none" xmlns="http://www.w3.org/2000/svg"><path d="M10.7817 8.15636L7.20566 4.58036L8.14833 3.6377L13.3337 8.82303L8.14833 14.0084L7.20566 13.0657L10.7817 9.4897H2.66699V8.15636H10.7817Z" fill="black"></path></svg></button></div></a><a class="learnDetail_pickerItem__Qkcwx" href="/learn/top-ten-rag-and-llm-evaluation-tools-you-dont-want-to-miss"><img src="https://assets.zilliz.com/Top_10_RAG_and_LLM_Evaluation_Tools_You_Don_t_Want_to_Miss_cb3936dbfe.png" alt="Top 10 RAG &amp; LLM Evaluation Tools You Don&#x27;t Want To Miss"/><div class="learnDetail_contentPart__zQTkO"><div><h3 class="learnDetail_articleTitle__pYwnn">Top 10 RAG &amp; LLM Evaluation Tools You Don&#x27;t Want To Miss</h3><p class="learnDetail_articleDesc__iZ5v7">Discover the best RAG evaluation tools to improve AI app reliability, prevent hallucinations, and boost performance across different frameworks. </p></div><button class="CommonTransitionButton_transitionButton__4vdrN"><span class="CommonTransitionButton_label__4YgGh">Read Now</span><svg width="16" height="17" viewBox="0 0 16 17" fill="none" xmlns="http://www.w3.org/2000/svg"><path d="M10.7817 8.15636L7.20566 4.58036L8.14833 3.6377L13.3337 8.82303L8.14833 14.0084L7.20566 13.0657L10.7817 9.4897H2.66699V8.15636H10.7817Z" fill="black"></path></svg></button></div></a></ul></section></div></main><footer class="footer_footerContainer__nClkK"><div class="page_container__IibMw"><section class="footer_navsWrapper__d8Hxa"><div class="footer_subscribePart__bj0xX"><div class="footer_socialMediaWrapper__v0YIi"><img src="/images/home/homepage-footer-logo.svg" alt="Zilliz Logo"/><div class="footer_socialMediaIcons__xqbMo"><a rel="noopener noreferrer" target="_blank" title="Youtube" class="footer_linkButton__e7vEY" href="https://www.youtube.com/c/MilvusVectorDatabase"><svg width="24" height="24" viewBox="0 0 24 24" fill="none"><path fill-rule="evenodd" clip-rule="evenodd" d="M20.184 4.13849C21.6225 4.21949 22.329 4.43249 22.98 5.59049C23.658 6.74699 24 8.73899 24 12.2475V12.252V12.2595C24 15.7515 23.658 17.7585 22.9815 18.903C22.3305 20.061 21.624 20.271 20.1855 20.3685C18.747 20.451 15.1335 20.5005 12.003 20.5005C8.8665 20.5005 5.2515 20.451 3.8145 20.367C2.379 20.2695 1.6725 20.0595 1.0155 18.9015C0.345 17.757 0 15.75 0 12.258V12.255V12.2505V12.246C0 8.73899 0.345 6.74699 1.0155 5.59049C1.6725 4.43099 2.3805 4.21949 3.816 4.13699C5.2515 4.04099 8.8665 4.00049 12.003 4.00049C15.1335 4.00049 18.747 4.04099 20.184 4.13849ZM16.5 12.2505L9 7.75049V16.7505L16.5 12.2505Z" fill="black"></path></svg></a><a rel="noopener noreferrer" target="_blank" title="LinkedIn" class="footer_linkButton__e7vEY" href="https://www.linkedin.com/company/zilliz"><svg width="24" height="24" viewBox="0 0 24 24" fill="none"><path fill-rule="evenodd" clip-rule="evenodd" d="M5.8125 2.40625C5.8125 3.73519 4.73519 4.8125 3.40625 4.8125C2.07731 4.8125 1 3.73519 1 2.40625C1 1.07731 2.07731 0 3.40625 0C4.73519 0 5.8125 1.07731 5.8125 2.40625ZM1 6.875H5.91975V22H1V6.875ZM19.3205 7.05237C19.3031 7.04688 19.286 7.04122 19.2689 7.03557L19.2688 7.03556C19.2346 7.02426 19.2004 7.01296 19.1637 7.00287C19.0977 6.98775 19.0317 6.97538 18.9644 6.96438C18.7031 6.91213 18.4171 6.875 18.0816 6.875C15.2134 6.875 13.3942 8.96088 12.7948 9.76663V6.875H7.875V22H12.7948V13.75C12.7948 13.75 16.5127 8.57175 18.0816 12.375V22H23V11.7934C23 9.50813 21.4339 7.60375 19.3205 7.05237Z" fill="black"></path></svg></a><a rel="noopener noreferrer" target="_blank" title="Twitter" class="footer_linkButton__e7vEY" href="https://twitter.com/zilliz_universe"><svg height="24" width="24" viewBox="0 0 24 24" fill="none" xmlns="http://www.w3.org/2000/svg"><path d="M18.244 2.25h3.308l-7.227 8.26 8.502 11.24H16.17l-5.214-6.817L4.99 21.75H1.68l7.73-8.835L1.254 2.25H8.08l4.713 6.231zm-1.161 17.52h1.833L7.084 4.126H5.117z" fill="black"></path></svg></a><a rel="noopener noreferrer" target="_blank" title="GitHub" class="footer_linkButton__e7vEY" href="https://github.com/zilliztech"><svg width="24" height="24" viewBox="0 0 24 24" fill="none"><path fill-rule="evenodd" clip-rule="evenodd" d="M12.3036 1C6.0724 1 1.02539 6.04701 1.02539 12.2782C1.02539 17.2688 4.25378 21.4841 8.73688 22.9785C9.30079 23.0771 9.51226 22.7388 9.51226 22.4427C9.51226 22.1749 9.49816 21.2867 9.49816 20.3422C6.66451 20.8638 5.93142 19.6514 5.70586 19.017C5.57898 18.6927 5.02916 17.6918 4.54984 17.4239C4.1551 17.2125 3.59119 16.6908 4.53574 16.6767C5.4239 16.6626 6.0583 17.4944 6.26977 17.8328C7.28481 19.5386 8.90606 19.0593 9.55455 18.7632C9.65324 18.0301 9.94929 17.5367 10.2735 17.2548C7.76413 16.9728 5.14195 16 5.14195 11.6861C5.14195 10.4596 5.57898 9.44458 6.29796 8.6551C6.18518 8.37314 5.79044 7.21713 6.41075 5.66637C6.41075 5.66637 7.3553 5.37031 9.51226 6.82239C10.4145 6.56863 11.3732 6.44175 12.3318 6.44175C13.2905 6.44175 14.2491 6.56863 15.1514 6.82239C17.3083 5.35622 18.2529 5.66637 18.2529 5.66637C18.8732 7.21713 18.4785 8.37314 18.3657 8.6551C19.0847 9.44458 19.5217 10.4455 19.5217 11.6861C19.5217 16.0141 16.8854 16.9728 14.376 17.2548C14.7848 17.6072 15.1373 18.2839 15.1373 19.3412C15.1373 20.8497 15.1232 22.0621 15.1232 22.4427C15.1232 22.7388 15.3346 23.0912 15.8986 22.9785C20.3535 21.4841 23.5819 17.2548 23.5819 12.2782C23.5819 6.04701 18.5348 1 12.3036 1V1Z" fill="black"></path></svg></a><a rel="noopener noreferrer" target="_blank" title="Discord" class="footer_linkButton__e7vEY" href="https://discord.com/invite/8uyFbECzPX"><svg width="24" height="24" viewBox="0 0 24 24" fill="none" xmlns="http://www.w3.org/2000/svg"><path d="M20.3303 4.19247C18.7767 3.45861 17.1156 2.92527 15.3789 2.62158C15.1656 3.0109 14.9164 3.53454 14.7446 3.9511C12.8985 3.67079 11.0693 3.67079 9.25714 3.9511C9.08537 3.53454 8.83053 3.0109 8.61534 2.62158C6.87679 2.92527 5.21374 3.46057 3.66017 4.19636C0.526624 8.9771 -0.32283 13.6391 0.101898 18.2349C2.18023 19.8019 4.19439 20.7537 6.17456 21.3766C6.66347 20.6973 7.09951 19.9751 7.47516 19.214C6.75973 18.9395 6.07451 18.6008 5.42705 18.2076C5.59882 18.0792 5.76684 17.9448 5.92916 17.8066C9.87818 19.6714 14.1689 19.6714 18.0707 17.8066C18.2349 17.9448 18.4029 18.0792 18.5728 18.2076C17.9235 18.6028 17.2364 18.9415 16.5209 19.216C16.8966 19.9751 17.3307 20.6992 17.8215 21.3786C19.8036 20.7557 21.8196 19.8038 23.898 18.2349C24.3963 12.9072 23.0466 8.28801 20.3303 4.19247ZM8.01316 15.4085C6.8277 15.4085 5.85553 14.2912 5.85553 12.9305C5.85553 11.5699 6.80694 10.4506 8.01316 10.4506C9.2194 10.4506 10.1915 11.5679 10.1708 12.9305C10.1727 14.2912 9.2194 15.4085 8.01316 15.4085ZM15.9867 15.4085C14.8013 15.4085 13.8291 14.2912 13.8291 12.9305C13.8291 11.5699 14.7805 10.4506 15.9867 10.4506C17.1929 10.4506 18.1651 11.5679 18.1443 12.9305C18.1443 14.2912 17.1929 15.4085 15.9867 15.4085Z" fill="black"></path></svg></a><a rel="noopener noreferrer" target="_blank" title="G2" class="footer_linkButton__e7vEY" href="https://www.g2.com/products/zilliz/reviews"><svg width="24" height="25" viewBox="0 0 24 25" fill="none" xmlns="http://www.w3.org/2000/svg"><g id="Icon/Social/Instagram Copy 6"><g id="Layer 1"><path id="Vector" d="M15.708 16.8491C16.4437 18.1257 17.1712 19.3879 17.8981 20.6487C14.6791 23.1131 9.67095 23.4109 5.96349 20.5729C1.69701 17.3044 0.995778 11.7274 3.27998 7.71278C5.90715 3.09514 10.8234 2.07392 13.9888 2.82274C13.9032 3.00872 12.0074 6.9418 12.0074 6.9418C12.0074 6.9418 11.8575 6.95165 11.7727 6.95329C10.8371 6.99295 10.1403 7.21065 9.39335 7.59682C8.57389 8.02442 7.87164 8.64623 7.34797 9.40789C6.8243 10.1696 6.49516 11.0479 6.38932 11.9661C6.27888 12.8973 6.40764 13.8414 6.76345 14.709C7.06429 15.4425 7.48985 16.0939 8.06035 16.6439C8.93553 17.4885 9.97698 18.0114 11.1842 18.1845C12.3274 18.3486 13.4268 18.1862 14.4571 17.6684C14.8435 17.4745 15.1722 17.2604 15.5565 16.9667C15.6055 16.9349 15.6489 16.8947 15.708 16.8491Z" fill="black"></path><path id="Vector_2" d="M15.715 5.65256C15.5282 5.46878 15.3551 5.29921 15.1828 5.12855C15.0799 5.02681 14.9809 4.92097 14.8756 4.82169C14.8379 4.78587 14.7936 4.73691 14.7936 4.73691C14.7936 4.73691 14.8294 4.66088 14.8447 4.6297C15.0463 4.22521 15.3622 3.92956 15.7369 3.69436C16.1512 3.4323 16.6339 3.29896 17.124 3.3112C17.7511 3.32351 18.3342 3.47967 18.8262 3.9003C19.1894 4.21071 19.3757 4.60454 19.4085 5.07468C19.4632 5.8678 19.135 6.47523 18.4833 6.89914C18.1004 7.14857 17.6874 7.34138 17.2733 7.56974C17.045 7.69582 16.8497 7.80659 16.6265 8.03468C16.4302 8.26359 16.4206 8.47938 16.4206 8.47938L19.3872 8.47555V9.79679H14.8081C14.8081 9.79679 14.8081 9.70654 14.8081 9.66907C14.7906 9.0198 14.8663 8.40882 15.1636 7.81917C15.4371 7.2782 15.8621 6.88218 16.3727 6.57724C16.766 6.34231 17.1801 6.14239 17.5742 5.90855C17.8173 5.76442 17.9891 5.55301 17.9877 5.24643C17.9877 4.98333 17.7962 4.74949 17.5228 4.67647C16.8779 4.50253 16.2215 4.78012 15.8802 5.37032C15.8304 5.45647 15.7795 5.54207 15.715 5.65256Z" fill="black"></path><path id="Vector_3" d="M21.4533 15.4447L18.9533 11.1273H14.0061L11.49 15.4892H16.4736L18.9328 19.7861L21.4533 15.4447Z" fill="black"></path></g></g></svg></a><a rel="noopener noreferrer" target="_blank" title="Bluesky" class="footer_linkButton__e7vEY" href="https://bsky.app/profile/zilliz-universe.bsky.social"><svg width="24" height="24" viewBox="0 0 24 24" fill="none" xmlns="http://www.w3.org/2000/svg"><g id="Icon/Social/Instagram Copy 7"><path id="Vector" d="M5.76879 3.30387C8.29104 5.19742 11.004 9.03674 12.0001 11.0971C12.9962 9.03689 15.709 5.19738 18.2313 3.30387C20.0513 1.93757 23 0.8804 23 4.24437C23 4.9162 22.6148 9.8881 22.3889 10.6953C21.6036 13.5015 18.7421 14.2173 16.1967 13.7841C20.646 14.5413 21.7778 17.0496 19.3335 19.5579C14.6911 24.3216 12.661 18.3627 12.1406 16.8358C12.0453 16.5559 12.0007 16.4249 12 16.5363C11.9993 16.4249 11.9547 16.5559 11.8594 16.8358C11.3392 18.3627 9.30916 24.3218 4.66654 19.5579C2.22213 17.0496 3.35395 14.5412 7.80331 13.7841C5.25785 14.2173 2.39627 13.5015 1.6111 10.6953C1.38518 9.88802 1 4.91612 1 4.24437C1 0.8804 3.94882 1.93757 5.76866 3.30387H5.76879Z" fill="black"></path></g></svg></a></div></div><div class="subscribeFooter_container__V07MM footer_subscribeRoot__ni93s"><strong class="subscribeFooter_title__LHQsP">Sign up for the Zilliz newsletter</strong><div class="subscribeFooter_inputContainer__tnxFu"><input class="subscribeFooter_inputEle__oP0t0" placeholder="Email address" value=""/><button class="BaseButton_root__SFmw5 BaseButton_contained__2JisA subscribeFooter_btn__Hk7zt" style="cursor:pointer">Subscribe</button></div><p class="subscribeFooter_address__cI4er">201 Redwood Shores Pkwy, Suite 330 Redwood City, California 94065</p></div></div><ul class="footer_navs__0biPd"><li class="footer_navColumn__kADYe"><h5 class="footer_cat___oPg7">Products</h5><ul><li class="footer_titleGroup__v56YT"><a title="Zilliz Cloud" target="_self" class="footer_linkButton__e7vEY" href="/cloud">Zilliz Cloud</a></li><li class="footer_titleGroup__v56YT"><a title="Zilliz Cloud BYOC" target="_self" class="footer_linkButton__e7vEY" href="/bring-your-own-cloud">Zilliz Cloud BYOC</a></li><li class="footer_titleGroup__v56YT"><a title="Zilliz Cloud Free Tier" target="_self" class="footer_linkButton__e7vEY" href="/zilliz-cloud-free-tier">Zilliz Cloud Free Tier</a></li><li class="footer_titleGroup__v56YT"><a title="ZIlliz Migration Service" target="_self" class="footer_linkButton__e7vEY" href="/zilliz-migration-service">ZIlliz Migration Service</a></li><li class="footer_titleGroup__v56YT"><a title="Milvus" target="_self" class="footer_linkButton__e7vEY" href="/what-is-milvus">Milvus</a></li><li class="footer_titleGroup__v56YT"><a rel="noopener noreferrer" target="_blank" title="DeepSearcher" class="footer_linkButton__e7vEY" href="https://github.com/zilliztech/deep-searcher">DeepSearcher<svg width="12" height="12" viewBox="0 0 12 12" fill="none" xmlns="http://www.w3.org/2000/svg"><path d="M7.86391 4L2.70712 4L2.70712 3L9.57108 3V9.86396L8.57108 9.86396L8.57108 4.70704L2.70712 10.571L2.00002 9.86389L7.86391 4Z" fill="black"></path></svg></a></li><li class="footer_titleGroup__v56YT"><a title="GPTCache" target="_self" class="footer_linkButton__e7vEY" href="/what-is-gptcache">GPTCache</a></li><li class="footer_titleGroup__v56YT"><a title="Attu" target="_self" class="footer_linkButton__e7vEY" href="/attu">Attu</a></li><li class="footer_titleGroup__v56YT"><a rel="noopener noreferrer" target="_blank" title="Milvus CLI" class="footer_linkButton__e7vEY" href="https://github.com/zilliztech/milvus_cli">Milvus CLI<svg width="12" height="12" viewBox="0 0 12 12" fill="none" xmlns="http://www.w3.org/2000/svg"><path d="M7.86391 4L2.70712 4L2.70712 3L9.57108 3V9.86396L8.57108 9.86396L8.57108 4.70704L2.70712 10.571L2.00002 9.86389L7.86391 4Z" fill="black"></path></svg></a></li><li class="footer_titleGroup__v56YT"><a title="Vector Transport Service" target="_self" class="footer_linkButton__e7vEY" href="/vector-transport-service">Vector Transport Service</a></li></ul></li><li class="footer_navColumn__kADYe"><h5 class="footer_cat___oPg7">Developers</h5><ul><li class="footer_titleGroup__v56YT"><a rel="noopener noreferrer" target="_blank" title="Documentation" class="footer_linkButton__e7vEY" href="https://docs.zilliz.com/docs/home">Documentation<svg width="12" height="12" viewBox="0 0 12 12" fill="none" xmlns="http://www.w3.org/2000/svg"><path d="M7.86391 4L2.70712 4L2.70712 3L9.57108 3V9.86396L8.57108 9.86396L8.57108 4.70704L2.70712 10.571L2.00002 9.86389L7.86391 4Z" fill="black"></path></svg></a></li><li class="footer_titleGroup__v56YT"><a title="Open-Source Projects" target="_self" class="footer_linkButton__e7vEY" href="/product/open-source-vector-database">Open-Source Projects</a></li><li class="footer_titleGroup__v56YT"><a rel="noopener noreferrer" target="_self" title="VectorDB Benchmark" class="footer_linkButton__e7vEY" href="/vector-database-benchmark-tool">VectorDB Benchmark</a></li><li class="footer_titleGroup__v56YT"><a title="Free RAG Cost Calculator" target="_self" class="footer_linkButton__e7vEY" href="/rag-cost-calculator">Free RAG Cost Calculator</a></li><li class="footer_titleGroup__v56YT"><a title="RAG Tutorials" target="_self" class="footer_linkButton__e7vEY" href="/tutorials/rag">RAG Tutorials</a></li><li class="footer_titleGroup__v56YT"><a title="Milvus Notebooks" target="_self" class="footer_linkButton__e7vEY" href="/learn/milvus-notebooks">Milvus Notebooks</a></li></ul></li><li class="footer_navColumn__kADYe"><h5 class="footer_cat___oPg7">Resources</h5><ul><li class="footer_titleGroup__v56YT"><a title="Blog" target="_self" class="footer_linkButton__e7vEY" href="/blog">Blog</a></li><li class="footer_titleGroup__v56YT"><a title="Learning Center" target="_self" class="footer_linkButton__e7vEY" href="/learn">Learning Center</a></li><li class="footer_titleGroup__v56YT"><a title="GenAI Resource Hub" target="_self" class="footer_linkButton__e7vEY" href="/learn/generative-ai">GenAI Resource Hub</a></li><li class="footer_titleGroup__v56YT"><a title="VectorDB Comparison" target="_self" class="footer_linkButton__e7vEY" href="/comparison">VectorDB Comparison</a></li><li class="footer_titleGroup__v56YT"><a title="Guides &amp; Whitepapers" target="_self" class="footer_linkButton__e7vEY" href="/resources">Guides &amp; Whitepapers</a></li><li class="footer_titleGroup__v56YT"><a title="Popular Embedding Models" target="_self" class="footer_linkButton__e7vEY" href="/ai-models">Popular Embedding Models</a></li><li class="footer_titleGroup__v56YT"><a title="Data Connectors" target="_self" class="footer_linkButton__e7vEY" href="/data-connectors">Data Connectors</a></li><li class="footer_titleGroup__v56YT"><a title="Glossary" target="_self" class="footer_linkButton__e7vEY" href="/glossary">Glossary</a></li><li class="footer_titleGroup__v56YT"><a title="What is RAG?" target="_self" class="footer_linkButton__e7vEY" href="/learn/Retrieval-Augmented-Generation">What is RAG?</a></li><li class="footer_titleGroup__v56YT"><a title="What is a Vector Database?" target="_self" class="footer_linkButton__e7vEY" href="/learn/what-is-vector-database">What is a Vector Database?</a></li><li class="footer_titleGroup__v56YT"><a title="Trust Center" target="_self" class="footer_linkButton__e7vEY" href="/trust-center">Trust Center</a></li><li class="footer_titleGroup__v56YT"><a title="AI Reference Guide" target="_self" class="footer_linkButton__e7vEY footer_faqEntry__udaD3" href="/ai-faq">AI Reference Guide</a></li></ul></li><li class="footer_navColumn__kADYe"><h5 class="footer_cat___oPg7">Company</h5><ul><li class="footer_titleGroup__v56YT"><a title="About" target="_self" class="footer_linkButton__e7vEY" href="/about">About</a></li><li class="footer_titleGroup__v56YT"><a title="Careers" target="_self" class="footer_linkButton__e7vEY" href="/careers">Careers</a><span class="footer_highlightItem__lwUcw"></span></li><li class="footer_titleGroup__v56YT"><a title="News" target="_self" class="footer_linkButton__e7vEY" href="/news">News</a></li><li class="footer_titleGroup__v56YT"><a title="Partners" target="_self" class="footer_linkButton__e7vEY" href="/partners">Partners</a></li><li class="footer_titleGroup__v56YT"><a title="Events" target="_self" class="footer_linkButton__e7vEY" href="/event">Events</a></li><li class="footer_titleGroup__v56YT"><a title="Contact Sales" target="_self" class="footer_linkButton__e7vEY" href="/contact-sales">Contact Sales</a></li><li class="footer_titleGroup__v56YT"><a title="Brand Assets" target="_self" class="footer_linkButton__e7vEY" href="/brand-assets">Brand Assets</a></li></ul></li></ul></section><div class="footer_bottom__0Qj7r"><div class="footer_leftPart__k5npK"><div><a href="/terms-and-conditions">Terms of Service</a><a href="/privacy-policy">Privacy Policy</a><a href="/security">Security</a><a rel="noopener noreferrer" target="_blank" href="https://status.zilliz.com/">System Status</a><button class="footer_cookieBtn__KJDjM">Cookie Settings</button><div class="footer_mark__p3pFH">LF AI, LF AI &amp; data, Milvus, and associated open-source project names are trademarks of the Linux Foundation.</div><div class="footer_copyright__AUuel">© Zilliz 2025 All rights reserved.</div></div></div><div class="footer_logoSection__gXPke"><img src="/images/layout/soc-logo.png" alt="aicpa"/><img src="/images/layout/iso-logo.png" alt="ISO"/></div></div></div></footer><div class="inkeep_inkeepChatButtonContainer__sEQtK"><div class="inkeep_inkeepButtonBgWrapper__Mqwne"><button class="inkeep_inkeepChatButton__q9V8P"><svg width="15" height="16" viewBox="0 0 15 16" fill="none" xmlns="http://www.w3.org/2000/svg"><path d="M4.06875 3.7094C4.37476 3.7094 4.64788 3.90089 4.7525 4.18846L7.66377 12.1945L7.68581 12.2655C7.77631 12.6232 7.58293 12.9981 7.22879 13.127C6.87469 13.2557 6.4852 13.093 6.3247 12.7609L6.29627 12.692L5.74259 11.1695H2.39491L1.84123 12.692C1.70382 13.0697 1.28644 13.2643 0.908711 13.127C0.531024 12.9896 0.336372 12.5722 0.473726 12.1945L3.385 4.18846L3.43191 4.0854C3.55849 3.8561 3.80098 3.7094 4.06875 3.7094ZM2.93296 9.68974L2.92443 9.7139H5.21307L5.20454 9.68974L4.06875 6.56595L2.93296 9.68974Z" fill="url(#paint0_linear_11477_442303)"></path><path d="M10.6191 12.4432V10.2598C10.6191 9.8578 10.945 9.53195 11.3469 9.53195C11.7489 9.53195 12.0747 9.8578 12.0747 10.2598V12.4432C12.0747 12.8452 11.7489 13.171 11.3469 13.171C10.945 13.171 10.6191 12.8452 10.6191 12.4432Z" fill="url(#paint1_linear_11477_442303)"></path><path d="M11.0201 2.37198C11.1338 2.11266 11.5601 2.11266 11.6738 2.37198C11.8986 2.88469 12.2258 3.5124 12.6127 3.89927C12.9996 4.28613 13.6273 4.61338 14.14 4.83817C14.3993 4.95185 14.3993 5.37821 14.14 5.4919C13.6273 5.71669 12.9996 6.04395 12.6127 6.43081C12.2258 6.81768 11.8986 7.44539 11.6738 7.95811C11.5601 8.21743 11.1338 8.21743 11.0201 7.95811C10.7953 7.4454 10.468 6.81768 10.0812 6.43081C9.69429 6.04395 9.06658 5.71669 8.55386 5.4919C8.29454 5.37821 8.29454 4.95186 8.55386 4.83817C9.06658 4.61338 9.69429 4.28613 10.0812 3.89927C10.468 3.5124 10.7953 2.88469 11.0201 2.37198Z" fill="url(#paint2_linear_11477_442303)"></path><defs><linearGradient id="paint0_linear_11477_442303" x1="0.429688" y1="2.33714" x2="10.9766" y2="9.53844" gradientUnits="userSpaceOnUse"><stop stop-color="#00EF8B"></stop><stop offset="0.505" stop-color="#0044E4"></stop><stop offset="1" stop-color="#CD3FFF"></stop></linearGradient><linearGradient id="paint1_linear_11477_442303" x1="0.429688" y1="2.33714" x2="10.9766" y2="9.53844" gradientUnits="userSpaceOnUse"><stop stop-color="#00EF8B"></stop><stop offset="0.505" stop-color="#0044E4"></stop><stop offset="1" stop-color="#CD3FFF"></stop></linearGradient><linearGradient id="paint2_linear_11477_442303" x1="0.429688" y1="2.33714" x2="10.9766" y2="9.53844" gradientUnits="userSpaceOnUse"><stop stop-color="#00EF8B"></stop><stop offset="0.505" stop-color="#0044E4"></stop><stop offset="1" stop-color="#CD3FFF"></stop></linearGradient></defs></svg>Ask AI</button></div></div><div class="inkeep_inkeepChatModalContainer__dB5kW inkeep_hiddenEle__sZZ1h"><div class="inkeep_inkeepChatModalContent___AcLJ"><div class="inkeep_inkeepChatModalHeader__Z5g4t"><h3 class="inkeep_inkeepChatModalTitle__RNvS2">AI Assistant</h3><button class="inkeep_inkeepChatModalCloseButton__DKIqe"><svg width="24" height="24" viewBox="0 0 24 24"><path d="M5 5L19 19" stroke="#1D2939" stroke-width="2"></path><path d="M19 5L5 19" stroke="#1D2939" stroke-width="2"></path></svg></button></div><div class="inkeep_chatModal__EZkCw"></div></div><div class="inkeep_closeButtonWrapper__Cw9No"><button class="inkeep_closeButton__tJl6d"><svg width="37" height="36" viewBox="0 0 37 36" fill="none" xmlns="http://www.w3.org/2000/svg"><circle cx="18.3965" cy="18" r="17.5" fill="white" stroke="#5D6D85"></circle><path d="M18.3975 0C28.3384 0.000263882 36.3975 8.05904 36.3975 18C36.3975 27.941 28.3384 35.9997 18.3975 36C8.45634 36 0.397461 27.9411 0.397461 18C0.397461 8.05887 8.45634 0 18.3975 0ZM18.3975 1.5C9.28476 1.5 1.89746 8.8873 1.89746 18C1.89746 27.1127 9.28476 34.5 18.3975 34.5C27.5099 34.4997 34.8975 27.1125 34.8975 18C34.8975 8.88746 27.5099 1.50026 18.3975 1.5ZM24.0732 15.248L24.9482 16.3174L25.1699 16.5879L24.8994 16.8096C24.4326 17.1915 22.8576 18.4233 21.4053 19.5547C20.678 20.1212 19.9794 20.6641 19.4629 21.0654C19.2046 21.2661 18.991 21.4318 18.8428 21.5469C18.7691 21.6041 18.7112 21.6491 18.6719 21.6797C18.6522 21.6949 18.6361 21.707 18.626 21.7148C18.6213 21.7185 18.6177 21.7217 18.6152 21.7236C18.6142 21.7244 18.6129 21.7251 18.6123 21.7256L18.6113 21.7266L18.3955 21.8936L18.1807 21.7256L11.8994 16.8145L11.6182 16.5938L11.8447 16.3174L12.7188 15.248L12.9404 14.9775L13.2119 15.1992L18.3965 19.4404L23.5811 15.1992L23.8516 14.9775L24.0732 15.248Z" fill="url(#paint0_linear_11620_448113)"></path><defs><linearGradient id="paint0_linear_11620_448113" x1="0.397461" y1="0.522786" x2="31.3993" y2="17.2587" gradientUnits="userSpaceOnUse"><stop stop-color="#00EF8B"></stop><stop offset="0.505" stop-color="#0044E4"></stop><stop offset="1" stop-color="#CD3FFF"></stop></linearGradient></defs></svg></button></div></div></div><script id="__NEXT_DATA__" type="application/json">{"props":{"pageProps":{"data":{"backgroundImage":"https://assets.zilliz.com/large_May_19_A_Guide_to_Chunking_Strategies_for_Retrieval_Augmented_Generation_RAG_1079ea179b.png","authorNames":["Rahul "],"authors":[{"id":132,"name":"Rahul ","author_tags":"Freelance Technical Writer","published_at":"2024-03-30T21:57:22.495Z","created_by":18,"updated_by":18,"created_at":"2024-03-30T21:57:19.140Z","updated_at":"2024-07-03T07:53:30.991Z","home_page":null,"home_page_link":null,"self_intro":null,"repost_to_medium":null,"repost_state":null,"meta_description":"Rahul, Freelance Technical Writer","locale":"en","avatar":{"id":3006,"name":"Male-Author.jpeg","alternativeText":"","caption":"","width":1024,"height":1024,"formats":{"large":{"ext":".jpeg","url":"https://assets.zilliz.com/large_Male_Author_526de0f08d.jpeg","hash":"large_Male_Author_526de0f08d","mime":"image/jpeg","name":"large_Male-Author.jpeg","path":null,"size":92.42,"width":1000,"height":1000},"small":{"ext":".jpeg","url":"https://assets.zilliz.com/small_Male_Author_526de0f08d.jpeg","hash":"small_Male_Author_526de0f08d","mime":"image/jpeg","name":"small_Male-Author.jpeg","path":null,"size":35.2,"width":500,"height":500},"medium":{"ext":".jpeg","url":"https://assets.zilliz.com/medium_Male_Author_526de0f08d.jpeg","hash":"medium_Male_Author_526de0f08d","mime":"image/jpeg","name":"medium_Male-Author.jpeg","path":null,"size":61.68,"width":750,"height":750},"thumbnail":{"ext":".jpeg","url":"https://assets.zilliz.com/thumbnail_Male_Author_526de0f08d.jpeg","hash":"thumbnail_Male_Author_526de0f08d","mime":"image/jpeg","name":"thumbnail_Male-Author.jpeg","path":null,"size":6.72,"width":156,"height":156}},"hash":"Male_Author_526de0f08d","ext":".jpeg","mime":"image/jpeg","size":94.23,"url":"https://assets.zilliz.com/Male_Author_526de0f08d.jpeg","previewUrl":null,"provider":"s3","provider_metadata":null,"created_by":55,"updated_by":55,"created_at":"2024-04-01T18:17:10.227Z","updated_at":"2024-04-01T18:17:21.142Z"}}],"display_time":"May 15, 2024","title":"A Guide to Chunking Strategies for Retrieval Augmented Generation (RAG)","sub_title":null,"tags":[{"id":5,"name":"Engineering","published_at":"2021-01-21T02:28:39.896Z","created_by":18,"updated_by":18,"created_at":"2021-01-21T02:28:37.242Z","updated_at":"2022-11-15T19:16:38.988Z","locale":"en"}],"articleContent":"\u003cp\u003e\u003ca href=\"https://zilliz.com/learn/Retrieval-Augmented-Generation\"\u003eRetrieval Augmented Generation\u003c/a\u003e (RAG) stands out as a significant innovation in \u003ca href=\"https://zilliz.com/learn/A-Beginner-Guide-to-Natural-Language-Processing\"\u003eNatural Language Processing\u003c/a\u003e (NLP), designed to enhance text generation by integrating the efficient retrieval of relevant information from a vast database. Developed by researchers including Patrick Lewis and his team, RAG combines the power of large pre-trained language models with a retrieval system that pulls data from extensive sources like Wikipedia to inform its responses.\u003c/p\u003e\n\u003ch2 id=\"What-is-Retrieval-Augmented-Generation-RAG\" class=\"common-anchor-header\"\u003eWhat is Retrieval Augmented Generation (RAG)?\u003cbutton data-href=\"#What-is-Retrieval-Augmented-Generation-RAG\" class=\"anchor-icon\" translate=\"no\"\u003e\n \u003csvg\n aria-hidden=\"true\"\n focusable=\"false\"\n height=\"20\"\n version=\"1.1\"\n viewBox=\"0 0 16 16\"\n width=\"16\"\n \u003e\n \u003cpath\n fill=\"#0092E4\"\n fill-rule=\"evenodd\"\n d=\"M4 9h1v1H4c-1.5 0-3-1.69-3-3.5S2.55 3 4 3h4c1.45 0 3 1.69 3 3.5 0 1.41-.91 2.72-2 3.25V8.59c.58-.45 1-1.27 1-2.09C10 5.22 8.98 4 8 4H4c-.98 0-2 1.22-2 2.5S3 9 4 9zm9-3h-1v1h1c1 0 2 1.22 2 2.5S13.98 12 13 12H9c-.98 0-2-1.22-2-2.5 0-.83.42-1.64 1-2.09V6.25c-1.09.53-2 1.84-2 3.25C6 11.31 7.55 13 9 13h4c1.45 0 3-1.69 3-3.5S14.5 6 13 6z\"\n \u003e\u003c/path\u003e\n \u003c/svg\u003e\n \u003c/button\u003e\u003c/h2\u003e\u003cp\u003eRAG is a hybrid language model that merges the capabilities of generative and retrieval-based \u003ca href=\"https://zilliz.com/learn/7-nlp-models\"\u003emodels in NLP\u003c/a\u003e. This approach addresses the limitations of pre-trained language models, which, despite storing vast amounts of factual knowledge, often need help accessing and manipulating this information accurately for complex, knowledge-intensive tasks. RAG tackles this by using a \u0026quot;neural retriever\u0026quot; to fetch relevant information from a \u0026quot;\u003ca href=\"https://zilliz.com/learn/dense-vector-in-ai-maximize-data-potential-in-machine-learning\"\u003edense vector\u003c/a\u003e index\u0026quot; of data sources like Wikipedia (or your data), which the model then uses to generate more accurate and contextually appropriate responses.\u003c/p\u003e\n\u003ch2 id=\"Significance-of-RAG-in-NLP\" class=\"common-anchor-header\"\u003eSignificance of RAG in NLP\u003cbutton data-href=\"#Significance-of-RAG-in-NLP\" class=\"anchor-icon\" translate=\"no\"\u003e\n \u003csvg\n aria-hidden=\"true\"\n focusable=\"false\"\n height=\"20\"\n version=\"1.1\"\n viewBox=\"0 0 16 16\"\n width=\"16\"\n \u003e\n \u003cpath\n fill=\"#0092E4\"\n fill-rule=\"evenodd\"\n d=\"M4 9h1v1H4c-1.5 0-3-1.69-3-3.5S2.55 3 4 3h4c1.45 0 3 1.69 3 3.5 0 1.41-.91 2.72-2 3.25V8.59c.58-.45 1-1.27 1-2.09C10 5.22 8.98 4 8 4H4c-.98 0-2 1.22-2 2.5S3 9 4 9zm9-3h-1v1h1c1 0 2 1.22 2 2.5S13.98 12 13 12H9c-.98 0-2-1.22-2-2.5 0-.83.42-1.64 1-2.09V6.25c-1.09.53-2 1.84-2 3.25C6 11.31 7.55 13 9 13h4c1.45 0 3-1.69 3-3.5S14.5 6 13 6z\"\n \u003e\u003c/path\u003e\n \u003c/svg\u003e\n \u003c/button\u003e\u003c/h2\u003e\u003cp\u003eThe development of RAG has marked a substantial improvement over traditional language models, particularly in tasks that require deep knowledge semantic meaning and factual accuracy:\u003c/p\u003e\n\u003cul\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003eEnhanced Text Generation:\u003c/strong\u003e By incorporating external data during the generation process, RAG models produce not only diverse and specific text but also more factually accurate compared to traditional seq2seq models that rely only on their internal parameters.\u003c/p\u003e\u003c/li\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003eState-of-the-art Performance:\u003c/strong\u003e RAG was fine-tuned and evaluated on various NLP tasks in the original RAG paper, particularly excelling in open-domain question answering. It has set new benchmarks, outperforming traditional seq2seq and task-specific models that rely solely on extracting answers from texts.\u003c/p\u003e\u003c/li\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003eFlexibility Across Tasks:\u003c/strong\u003e Beyond question answering, RAG has shown promise in other complex tasks, like generating content for scenarios modeled after the game \u0026quot;Jeopardy,\u0026quot; where precise and factual language is crucial. This adaptability makes it a powerful tool across various domains of NLP.\u003c/p\u003e\u003c/li\u003e\n\u003c/ul\u003e\n\u003cp\u003eFor further details, the foundational concepts and \u003ca href=\"https://zilliz.com/blog/how-to-evaluate-retrieval-augmented-generation-rag-applications\"\u003eapplications of RAG\u003c/a\u003e are thoroughly discussed in the work by Lewis et al. (2020), available through their NeurIPS paper and other publications ( Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, \u003ca href=\"https://ar5iv.labs.arxiv.org/html/2005.11401)%E2%80%8B%E2%80%8B\"\u003ehttps://ar5iv.labs.arxiv.org/html/2005.11401)\u003c/a\u003e\u003c/p\u003e\n\u003ch2 id=\"Chunking\" class=\"common-anchor-header\"\u003eChunking\u003cbutton data-href=\"#Chunking\" class=\"anchor-icon\" translate=\"no\"\u003e\n \u003csvg\n aria-hidden=\"true\"\n focusable=\"false\"\n height=\"20\"\n version=\"1.1\"\n viewBox=\"0 0 16 16\"\n width=\"16\"\n \u003e\n \u003cpath\n fill=\"#0092E4\"\n fill-rule=\"evenodd\"\n d=\"M4 9h1v1H4c-1.5 0-3-1.69-3-3.5S2.55 3 4 3h4c1.45 0 3 1.69 3 3.5 0 1.41-.91 2.72-2 3.25V8.59c.58-.45 1-1.27 1-2.09C10 5.22 8.98 4 8 4H4c-.98 0-2 1.22-2 2.5S3 9 4 9zm9-3h-1v1h1c1 0 2 1.22 2 2.5S13.98 12 13 12H9c-.98 0-2-1.22-2-2.5 0-.83.42-1.64 1-2.09V6.25c-1.09.53-2 1.84-2 3.25C6 11.31 7.55 13 9 13h4c1.45 0 3-1.69 3-3.5S14.5 6 13 6z\"\n \u003e\u003c/path\u003e\n \u003c/svg\u003e\n \u003c/button\u003e\u003c/h2\u003e\u003cp\u003e\u0026quot;Chunking\u0026quot; (and sometimes called \u0026quot;llm chunking\u0026quot;)refers to dividing a large text corpus into smaller, manageable pieces or segments. Each recursive chunking part acts as a standalone unit of information that can be individually indexed and retrieved. For instance, in the development of RAG models, as Lewis et al. (2020) described, Wikipedia articles are split into disjoint 100-word chunks to create a total of around 21 million documents that serve as the retrieval database. This chunking technique is crucial for enhancing the efficiency and accuracy of the retrieval process, which in turn impacts the overall performance of RAG models in various aspects, such as:\u003c/p\u003e\n\u003cul\u003e\n\u003cli\u003e\u003cstrong\u003eImproved Retrieval Efficiency:\u003c/strong\u003e By organizing the text into smaller chunks, the retrieval component of the RAG model can more quickly and accurately identify relevant information. This is because smaller chunks reduce the computational load on the retrieval system, allowing for faster response times during the retrieval phase.\u003c/li\u003e\n\u003c/ul\u003e\n\u003cul\u003e\n\u003cli\u003e\u003cstrong\u003eEnhanced Accuracy and Relevance:\u003c/strong\u003e Chunking enables the RAG model to pinpoint the most relevant information more precisely. Since each chunk is a condensed representation of information, it is easier for the retrieval system to assess the relevance of each chunk to a given query, thus improving the likelihood of retrieving the most pertinent information.\u003c/li\u003e\n\u003c/ul\u003e\n\u003cul\u003e\n\u003cli\u003e\u003cstrong\u003eScalability and Manageability:\u003c/strong\u003e Handling massive datasets becomes more feasible with chunking. It allows the system to manage and update the database efficiently, as each chunk can be individually indexed and maintained. This is particularly important for RAG models, which rely on up-to-date information to generate accurate and relevant outputs.\u003c/li\u003e\n\u003c/ul\u003e\n\u003cul\u003e\n\u003cli\u003e\u003cstrong\u003eBalanced Information Distribution:\u003c/strong\u003e Chunking ensures that the information is evenly distributed across the dataset, which helps maintain a balanced retrieval process. This uniform distribution prevents the retrieval model from being biased towards longer documents that might otherwise dominate the retrieval results if the corpus were not chunked.\u003c/li\u003e\n\u003c/ul\u003e\n\u003ch2 id=\"Detailed-Exploration-of-Chunking-Strategies-in-RAG-Systems\" class=\"common-anchor-header\"\u003eDetailed Exploration of Chunking Strategies in RAG Systems\u003cbutton data-href=\"#Detailed-Exploration-of-Chunking-Strategies-in-RAG-Systems\" class=\"anchor-icon\" translate=\"no\"\u003e\n \u003csvg\n aria-hidden=\"true\"\n focusable=\"false\"\n height=\"20\"\n version=\"1.1\"\n viewBox=\"0 0 16 16\"\n width=\"16\"\n \u003e\n \u003cpath\n fill=\"#0092E4\"\n fill-rule=\"evenodd\"\n d=\"M4 9h1v1H4c-1.5 0-3-1.69-3-3.5S2.55 3 4 3h4c1.45 0 3 1.69 3 3.5 0 1.41-.91 2.72-2 3.25V8.59c.58-.45 1-1.27 1-2.09C10 5.22 8.98 4 8 4H4c-.98 0-2 1.22-2 2.5S3 9 4 9zm9-3h-1v1h1c1 0 2 1.22 2 2.5S13.98 12 13 12H9c-.98 0-2-1.22-2-2.5 0-.83.42-1.64 1-2.09V6.25c-1.09.53-2 1.84-2 3.25C6 11.31 7.55 13 9 13h4c1.45 0 3-1.69 3-3.5S14.5 6 13 6z\"\n \u003e\u003c/path\u003e\n \u003c/svg\u003e\n \u003c/button\u003e\u003c/h2\u003e\u003cp\u003eAdvanced RAG](https://zilliz.com/blog/advanced-rag-apps-with-llamaindex) techniques like the following chunking strategies are crucial for optimizing the efficiency of RAG systems in processing and understanding large texts. Let’s go deeper into three primary chunking strategies—fixed-size chunking, semantic chunking, and hybrid chunking—and how they can be applied effectively in RAG contexts.\u003c/p\u003e\n\u003col\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003eFixed-Size Chunking:\u003c/strong\u003e Fixed-size chunking involves breaking down text into uniformly sized pieces based on a predefined number of characters, words, or tokens. This method is straightforward, making it a popular choice for initial data processing phases where quick data traversal is needed.\u003c/p\u003e\n\u003col\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003eStrategy:\u003c/strong\u003e This technique involves dividing text into chunks of a predetermined size, such as every 100 words or every 500 characters.\u003c/p\u003e\u003c/li\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003eImplementation:\u003c/strong\u003e Implementing fixed-size chunking can be straightforward using programming libraries that handle string operations, such as Python's basic string methods or more complex libraries like NLTK or spaCy for more structured data. For example,\u003c/p\u003e\u003c/li\u003e\n\u003c/ol\u003e\u003c/li\u003e\n\u003c/ol\u003e\n\u003cpre\u003e\u003ccode\u003e\u003cspan class=\"hljs-keyword\"\u003edef\u003c/span\u003e \u003cspan class=\"hljs-title function_\"\u003efixed_size_chunking\u003c/span\u003e(\u003cspan class=\"hljs-params\"\u003etext, chunk_size=\u003cspan class=\"hljs-number\"\u003e100\u003c/span\u003e\u003c/span\u003e):\n \u003cspan class=\"hljs-keyword\"\u003ereturn\u003c/span\u003e [text[i:i+chunk_size] \u003cspan class=\"hljs-keyword\"\u003efor\u003c/span\u003e i \u003cspan class=\"hljs-keyword\"\u003ein\u003c/span\u003e \u003cspan class=\"hljs-built_in\"\u003erange\u003c/span\u003e(\u003cspan class=\"hljs-number\"\u003e0\u003c/span\u003e, \u003cspan class=\"hljs-built_in\"\u003elen\u003c/span\u003e(text), chunk_size)]\n\u003cbutton class=\"copy-code-btn\"\u003e\u003c/button\u003e\u003c/code\u003e\u003c/pre\u003e\n\u003col\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003eAdvantages:\u003c/strong\u003e\u003c/p\u003e\n\u003col\u003e\n\u003cli\u003e\u003cp\u003eSimplicity and predictability in implementation, which makes it easier to manage and index the chunks.\u003c/p\u003e\u003c/li\u003e\n\u003cli\u003e\u003cp\u003eHigh computational efficiency and ease of implementation.\u003c/p\u003e\u003c/li\u003e\n\u003c/ol\u003e\u003c/li\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003eDisadvantages:\u003c/strong\u003e\u003c/p\u003e\n\u003col\u003e\n\u003cli\u003e\u003cp\u003eIt may cut off important semantic boundaries, leading to retrieval of out-of-context information.\u003c/p\u003e\u003c/li\u003e\n\u003cli\u003e\u003cp\u003eNot flexible, as it does not adapt to the natural structure of the text.\u003c/p\u003e\u003c/li\u003e\n\u003c/ol\u003e\u003c/li\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003eWhen to Use:\u003c/strong\u003e This strategy is ideal for scenarios where speed is more crucial than depth of context, such as during the preliminary analysis of large datasets where detailed semantic understanding is less critical.\u003c/p\u003e\u003c/li\u003e\n\u003c/ol\u003e\n\u003col\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003eSemantic Chunking:\u003c/strong\u003e Chunking segments texts based on meaningful content units, respecting natural language boundaries such as sentences, paragraphs, or thematic breaks.\u003c/p\u003e\n\u003col\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003eStrategy:\u003c/strong\u003e Unlike fixed-size chunking, this method splits text based on natural breaks in content, such as paragraphs, sections, or topics.\u003c/p\u003e\u003c/li\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003eImplementation:\u003c/strong\u003e Tools like \u003cstrong\u003espaCy\u003c/strong\u003e or \u003cstrong\u003eNLTK\u003c/strong\u003e can identify natural breaks in the text, such as end-of-sentence punctuation, to segment texts semantically.\u003c/p\u003e\u003c/li\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003eAdvantages:\u003c/strong\u003e\u003c/p\u003e\n\u003col\u003e\n\u003cli\u003e\u003cp\u003eMaintains the integrity of the information within each chunk, ensuring that all content within a chunk is contextually related.\u003c/p\u003e\u003c/li\u003e\n\u003cli\u003e\u003cp\u003eEnhances the relevance and accuracy of the retrieved data, which directly impacts the quality of generated responses.\u003c/p\u003e\u003c/li\u003e\n\u003c/ol\u003e\u003c/li\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003eDisadvantages:\u003c/strong\u003e\u003c/p\u003e\n\u003col\u003e\n\u003cli\u003eMore complex to implement as it requires understanding of the text structure and content.\u003c/li\u003e\n\u003c/ol\u003e\u003c/li\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003eWhen to Use:\u003c/strong\u003e Semantic chunking is particularly beneficial in content-sensitive applications like document summarization or legal document analysis, where understanding the full context and nuances of the language is essential.\u003c/p\u003e\u003c/li\u003e\n\u003c/ol\u003e\u003c/li\u003e\n\u003c/ol\u003e\n\u003col\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003eHybrid Chunking:\u003c/strong\u003e Hybrid chunking combines multiple chunking methods to leverage the benefits of both fixed-size and semantic chunking, optimizing both speed and accuracy.\u003c/p\u003e\n\u003col\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003eStrategy:\u003c/strong\u003e Combines multiple chunking methods to leverage the advantages of each. For example, a system might use fixed-length chunking for initial data processing and switch to semantic chunking when more precise retrieval is necessary.\u003c/p\u003e\u003c/li\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003eImplementation:\u003c/strong\u003e An initial pass might use fixed-size chunking for quick indexing, followed by semantic chunking during the retrieval phase to ensure contextual integrity. Integrating tools like \u003cstrong\u003espaCy\u003c/strong\u003e for semantic analysis with custom scripts for fixed-size chunking can create a robust \u003ca href=\"https://zilliz.com/blog/experimenting-with-different-chunking-strategies-via-langchain\"\u003echunking strategy\u003c/a\u003e that adapts to various needs.\u003c/p\u003e\u003c/li\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003eAdvantages:\u003c/strong\u003e Balances speed and contextual integrity by adapting the chunking method based on the task requirements.\u003c/p\u003e\u003c/li\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003eDisadvantages:\u003c/strong\u003e Can be more resource-intensive to implement and maintain.\u003c/p\u003e\u003c/li\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003eWhen to Use:\u003c/strong\u003e\u003c/p\u003e\n\u003col\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003eEnterprise Systems:\u003c/strong\u003e In customer service chatbots, hybrid chunking can quickly retrieve customer query-related information while ensuring the responses are contextually appropriate and semantically rich.\u003c/p\u003e\u003c/li\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003eAcademic Research:\u003c/strong\u003e Hybrid chunking is used in research to handle diverse data types, from structured scientific articles to informal interviews, ensuring detailed analysis and relevant data retrieval.\n\n \u003cspan class=\"img-wrapper\"\u003e\n \u003cimg src=\"https://assets.zilliz.com/Here_s_an_example_of_Chunking_using_Chunk_Viz_473dc44447.png\" alt=\"Here’s an example of Chunking using ChunkViz.png\" class=\"doc-image\" id=\"here’s-an-example-of-chunking-using-chunkviz.png\" /\u003e\n \u003cspan\u003eHere’s an example of Chunking using ChunkViz.png\u003c/span\u003e\n \u003c/span\u003e\n\u003c/p\u003e\u003c/li\u003e\n\u003c/ol\u003e\u003c/li\u003e\n\u003c/ol\u003e\u003c/li\u003e\n\u003c/ol\u003e\n\u003cp\u003eHere’s an example of Chunking using ChunkViz (\u003ca href=\"https://chunkviz.up.railway.app/\"\u003ehttps://chunkviz.up.railway.app/\u003c/a\u003e)\u003c/p\u003e\n\u003cp\u003eIn the example given, \u003cstrong\u003eChunk size\u003c/strong\u003e refers to the quantity of text (measured in terms exactly the same size of characters, single sentence, words, or sentences) that makes up a single unit or \u0026quot;chunk\u0026quot; during text processing. The choice of chunk size is crucial because it determines how much information is handled at once during tasks such as text analysis, vectorization, or in systems like RAG.\u003c/p\u003e\n\u003cul\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003eSmaller Chunk Sizes:\u003c/strong\u003e These are typically used when focusing on fine-grained analysis or when the text's detailed aspects are crucial. For instance, smaller chunks might be used in sentiment analysis where understanding specific phrases or sentences is essential.\u003c/p\u003e\u003c/li\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003eLarger Chunk Sizes:\u003c/strong\u003e These are suitable for capturing broader context or when the interplay between different text parts is essential, such as document summarization or topic detection. Larger chunks help preserve the narrative flow or thematic elements of the text, which might need fixing with finer chunking.\u003c/p\u003e\u003c/li\u003e\n\u003c/ul\u003e\n\u003cp\u003eThe selection of chunk size often depends on the balance between computational efficiency of memory and the need for contextual accuracy. Smaller chunks of memory can be processed faster but might lack context, while bigger chunks provide more context but can be computationally heavier to process.\u003c/p\u003e\n\u003cp\u003e\u003cstrong\u003eChunk overlap\u003c/strong\u003e allows chunks to share some standard text with adjacent chunks. This technique ensures that no critical information is lost at the boundaries between chunks, especially in cases where the cut-off point between two more meaningful chunks might split important semantic or syntactic structures.\u003c/p\u003e\n\u003cul\u003e\n\u003cli\u003e\u003cstrong\u003eRole of Overlap:\u003c/strong\u003e Overlap helps smooth the transitions between chunks, ensuring continuity of context, which is particularly useful in tasks like language modeling or when preparing data for training neural networks. For instance, if a sentence is cut off at the end of one chunk, starting the next chunk with the end of that sentence can provide continuity and context.\u003c/li\u003e\n\u003c/ul\u003e\n\u003cp\u003eUsing chunk overlap can significantly enhance the quality of the analysis by reducing the risk of context loss and improving the coherence of \u003ca href=\"https://zilliz.com/glossary/semantic-search\"\u003esemantic search\u003c/a\u003e in the output in \u003ca href=\"https://zilliz.com/learn/top-5-nlp-applications\"\u003eNLP applications\u003c/a\u003e. However, it also increases the computational and cognitive load, since more text is processed multiple times, and this trade-off needs to be managed based on the specific requirements of the task.\u003c/p\u003e\n\u003cp\u003eIn RAG systems, the choice of chunking strategy can significantly impact the effectiveness of the retrieval process and, by extension, the quality of the generated outputs. Whether through fixed-size, semantic, or hybrid chunking, the goal called chunking remains to optimize how information is segmented, indexed, and retrieved to support efficient and accurate natural language generation. The strategic implementation of chunking can be the difference between a performant system and one that struggles with latency and relevance, highlighting its critical role in the architecture of advanced NLP solutions.\u003c/p\u003e\n\u003ch2 id=\"Chunking-and-Vectorization-in-Text-Retrieval\" class=\"common-anchor-header\"\u003e\u003cstrong\u003eChunking and Vectorization in Text Retrieval\u003c/strong\u003e\u003cbutton data-href=\"#Chunking-and-Vectorization-in-Text-Retrieval\" class=\"anchor-icon\" translate=\"no\"\u003e\n \u003csvg\n aria-hidden=\"true\"\n focusable=\"false\"\n height=\"20\"\n version=\"1.1\"\n viewBox=\"0 0 16 16\"\n width=\"16\"\n \u003e\n \u003cpath\n fill=\"#0092E4\"\n fill-rule=\"evenodd\"\n d=\"M4 9h1v1H4c-1.5 0-3-1.69-3-3.5S2.55 3 4 3h4c1.45 0 3 1.69 3 3.5 0 1.41-.91 2.72-2 3.25V8.59c.58-.45 1-1.27 1-2.09C10 5.22 8.98 4 8 4H4c-.98 0-2 1.22-2 2.5S3 9 4 9zm9-3h-1v1h1c1 0 2 1.22 2 2.5S13.98 12 13 12H9c-.98 0-2-1.22-2-2.5 0-.83.42-1.64 1-2.09V6.25c-1.09.53-2 1.84-2 3.25C6 11.31 7.55 13 9 13h4c1.45 0 3-1.69 3-3.5S14.5 6 13 6z\"\n \u003e\u003c/path\u003e\n \u003c/svg\u003e\n \u003c/button\u003e\u003c/h2\u003e\u003cp\u003eChunking significantly influences the effectiveness of vectorization in text retrieval systems. Proper chunking ensures that text vectors encapsulate the necessary semantic information, which enhances retrieval accuracy and efficiency. For instance, chunking strategies that align with the natural structure of the text, such as those that consider individual sentences or paragraphs, help maintain the integrity of the information when converted into vector form. This structured approach ensures that the vectors generated reflect actual content relevance, facilitating more precise retrieval in systems like RAG.\u003c/p\u003e\n\u003ch3 id=\"Tools-and-Technologies-for-Effective-Vectorization\" class=\"common-anchor-header\"\u003e\u003cstrong\u003eTools and Technologies for Effective Vectorization\u003c/strong\u003e\u003cbutton data-href=\"#Tools-and-Technologies-for-Effective-Vectorization\" class=\"anchor-icon\" translate=\"no\"\u003e\n \u003csvg\n aria-hidden=\"true\"\n focusable=\"false\"\n height=\"20\"\n version=\"1.1\"\n viewBox=\"0 0 16 16\"\n width=\"16\"\n \u003e\n \u003cpath\n fill=\"#0092E4\"\n fill-rule=\"evenodd\"\n d=\"M4 9h1v1H4c-1.5 0-3-1.69-3-3.5S2.55 3 4 3h4c1.45 0 3 1.69 3 3.5 0 1.41-.91 2.72-2 3.25V8.59c.58-.45 1-1.27 1-2.09C10 5.22 8.98 4 8 4H4c-.98 0-2 1.22-2 2.5S3 9 4 9zm9-3h-1v1h1c1 0 2 1.22 2 2.5S13.98 12 13 12H9c-.98 0-2-1.22-2-2.5 0-.83.42-1.64 1-2.09V6.25c-1.09.53-2 1.84-2 3.25C6 11.31 7.55 13 9 13h4c1.45 0 3-1.69 3-3.5S14.5 6 13 6z\"\n \u003e\u003c/path\u003e\n \u003c/svg\u003e\n \u003c/button\u003e\u003c/h3\u003e\u003cp\u003eEffective vectorization of text heavily relies on the tools and \u003ca href=\"https://zilliz.com/blog/choosing-the-right-embedding-model-for-your-data\"\u003eembedding models\u003c/a\u003e used. Popular models include \u003cstrong\u003eWord2Vec\u003c/strong\u003e and \u003cstrong\u003eGloVe\u003c/strong\u003e for word-level embeddings, while \u003ca href=\"https://zilliz.com/learn/Sentence-Transformers-for-Long-Form-Text\"\u003e\u003cstrong\u003eBERT\u003c/strong\u003e\u003c/a\u003e and \u003cstrong\u003eGPT\u003c/strong\u003e offer capabilities at sentence or paragraph levels, accommodating bigger chunks of text. These models are adept at capturing the nuanced semantic relationships within the text, making them highly suitable for sophisticated text retrieval systems. The choice of the embedding model should align with the granularity of the chunking strategy to optimize performance. For example, \u003ca href=\"https://zilliz.com/learn/transforming-text-the-rise-of-sentence-transformers-in-nlp\"\u003esentence transformers\u003c/a\u003e are particularly effective when used with the semantic context of chunking, as they are designed to handle and process sentence-level information efficiently.\u003c/p\u003e\n\u003ch3 id=\"Aligning-Chunking-Strategy-with-Vectorization-for-Optimal-Performance\" class=\"common-anchor-header\"\u003e\u003cstrong\u003eAligning Chunking Strategy with Vectorization for Optimal Performance\u003c/strong\u003e\u003cbutton data-href=\"#Aligning-Chunking-Strategy-with-Vectorization-for-Optimal-Performance\" class=\"anchor-icon\" translate=\"no\"\u003e\n \u003csvg\n aria-hidden=\"true\"\n focusable=\"false\"\n height=\"20\"\n version=\"1.1\"\n viewBox=\"0 0 16 16\"\n width=\"16\"\n \u003e\n \u003cpath\n fill=\"#0092E4\"\n fill-rule=\"evenodd\"\n d=\"M4 9h1v1H4c-1.5 0-3-1.69-3-3.5S2.55 3 4 3h4c1.45 0 3 1.69 3 3.5 0 1.41-.91 2.72-2 3.25V8.59c.58-.45 1-1.27 1-2.09C10 5.22 8.98 4 8 4H4c-.98 0-2 1.22-2 2.5S3 9 4 9zm9-3h-1v1h1c1 0 2 1.22 2 2.5S13.98 12 13 12H9c-.98 0-2-1.22-2-2.5 0-.83.42-1.64 1-2.09V6.25c-1.09.53-2 1.84-2 3.25C6 11.31 7.55 13 9 13h4c1.45 0 3-1.69 3-3.5S14.5 6 13 6z\"\n \u003e\u003c/path\u003e\n \u003c/svg\u003e\n \u003c/button\u003e\u003c/h3\u003e\u003cp\u003eAligning your chunking strategy with vectorization involves several key considerations:\u003c/p\u003e\n\u003cul\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003eChunk Size and Model Capacity:\u003c/strong\u003e It's crucial to match the chunk size with the capacity of the \u003ca href=\"https://zilliz.com/glossary/vector-embeddings\"\u003evectorization\u003c/a\u003e model. Optimized for shorter texts, models like BERT may require smaller, more concise chunks to operate effectively.\u003c/p\u003e\u003c/li\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003eConsistency and Overlap:\u003c/strong\u003e Ensuring consistency in chunk content and utilizing overlapping chunks can help maintain context between chunks, reducing the risk of losing critical information at the boundaries.\u003c/p\u003e\u003c/li\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003eIterative Refinement:\u003c/strong\u003e Continuously refining the chunking and vectorization approaches based on system performance feedback is essential. This might involve adjusting chunk sizes or the vectorization model based on the system's retrieval accuracy and response time.\u003c/p\u003e\u003c/li\u003e\n\u003c/ul\u003e\n\u003ch2 id=\"Implementing-Chunking-in-RAG-Pipelines\" class=\"common-anchor-header\"\u003e\u003cstrong\u003eImplementing Chunking in RAG Pipelines\u003c/strong\u003e\u003cbutton data-href=\"#Implementing-Chunking-in-RAG-Pipelines\" class=\"anchor-icon\" translate=\"no\"\u003e\n \u003csvg\n aria-hidden=\"true\"\n focusable=\"false\"\n height=\"20\"\n version=\"1.1\"\n viewBox=\"0 0 16 16\"\n width=\"16\"\n \u003e\n \u003cpath\n fill=\"#0092E4\"\n fill-rule=\"evenodd\"\n d=\"M4 9h1v1H4c-1.5 0-3-1.69-3-3.5S2.55 3 4 3h4c1.45 0 3 1.69 3 3.5 0 1.41-.91 2.72-2 3.25V8.59c.58-.45 1-1.27 1-2.09C10 5.22 8.98 4 8 4H4c-.98 0-2 1.22-2 2.5S3 9 4 9zm9-3h-1v1h1c1 0 2 1.22 2 2.5S13.98 12 13 12H9c-.98 0-2-1.22-2-2.5 0-.83.42-1.64 1-2.09V6.25c-1.09.53-2 1.84-2 3.25C6 11.31 7.55 13 9 13h4c1.45 0 3-1.69 3-3.5S14.5 6 13 6z\"\n \u003e\u003c/path\u003e\n \u003c/svg\u003e\n \u003c/button\u003e\u003c/h2\u003e\u003cp\u003eImplementing effective \u003ca href=\"https://zilliz.com/learn/guide-to-chunking-strategies-for-rag\"\u003echunking in RAG\u003c/a\u003e systems involves a nuanced understanding of how chunking interacts with other components, such as the retriever and generator. This interaction is pivotal for enhancing the efficiency and accuracy of chunking works the RAG system.\u003c/p\u003e\n\u003cul\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003eChunking and the Retriever:\u003c/strong\u003e The retriever's function is to identify and fetch the most relevant chunks of text based on the user query. Effective chunking strategies break down enormous datasets into manageable, coherent pieces that can be easily indexed and retrieved. For instance, chunking by document elements like titles or sections rather than mere token size can significantly improve the retriever's ability to pull contextually relevant information. This method ensures that each chunk encapsulates complete and standalone information, facilitating more accurate retrieval and reducing the retrieval of irrelevant information.\u003c/p\u003e\u003c/li\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003eChunking and the Generator:\u003c/strong\u003e The generator uses this information to construct responses once the relevant chunks are retrieved. The quality and granularity of chunking directly influence the generator's output. Well-defined chunks ensure the generator has all the necessary context, which helps produce coherent and contextually rich responses. If chunks are too granular or poorly defined, it may lead to responses that are out of context or lack continuity.\u003c/p\u003e\u003c/li\u003e\n\u003c/ul\u003e\n\u003ch3 id=\"Tools-and-Technologies-for-Building-and-Testing-Chunking-Strategies\" class=\"common-anchor-header\"\u003e\u003cstrong\u003eTools and Technologies for Building and Testing Chunking Strategies\u003c/strong\u003e\u003cbutton data-href=\"#Tools-and-Technologies-for-Building-and-Testing-Chunking-Strategies\" class=\"anchor-icon\" translate=\"no\"\u003e\n \u003csvg\n aria-hidden=\"true\"\n focusable=\"false\"\n height=\"20\"\n version=\"1.1\"\n viewBox=\"0 0 16 16\"\n width=\"16\"\n \u003e\n \u003cpath\n fill=\"#0092E4\"\n fill-rule=\"evenodd\"\n d=\"M4 9h1v1H4c-1.5 0-3-1.69-3-3.5S2.55 3 4 3h4c1.45 0 3 1.69 3 3.5 0 1.41-.91 2.72-2 3.25V8.59c.58-.45 1-1.27 1-2.09C10 5.22 8.98 4 8 4H4c-.98 0-2 1.22-2 2.5S3 9 4 9zm9-3h-1v1h1c1 0 2 1.22 2 2.5S13.98 12 13 12H9c-.98 0-2-1.22-2-2.5 0-.83.42-1.64 1-2.09V6.25c-1.09.53-2 1.84-2 3.25C6 11.31 7.55 13 9 13h4c1.45 0 3-1.69 3-3.5S14.5 6 13 6z\"\n \u003e\u003c/path\u003e\n \u003c/svg\u003e\n \u003c/button\u003e\u003c/h3\u003e\u003cp\u003eSeveral tools and platforms facilitate the development and testing of chunking strategies within RAG systems:\u003c/p\u003e\n\u003cul\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003eLangChain and \u003ca href=\"https://zilliz.com/partners/llamaindex\"\u003eLlamaIndex\u003c/a\u003e:\u003c/strong\u003e These tools provide various chunking strategies, including dynamic chunk sizing and overlapping, which are crucial for maintaining contextual continuity between chunks. They allow for the customization of chunk sizes and overlap based on the application's specific needs, which can be tailored to optimize both retrieval and generation processes in RAG systems.\u003c/p\u003e\u003c/li\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003ePreprocessing pipeline APIs by Unstructured:\u003c/strong\u003e These pipelines enhance RAG performance by employing sophisticated document understanding techniques, such as chunking by document element. This method is particularly effective for complex document types with varied structures, as it ensures that only relevant data is considered for retrieval and generation, enhancing both the accuracy and efficiency of the RAG system.\u003c/p\u003e\u003c/li\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003eZilliz Cloud\u003c/strong\u003e: Zilliz Cloud includes a capability called Pipelines that streamlines the conversion of \u003ca href=\"https://zilliz.com/glossary/unstructured-data\"\u003eunstructured data\u003c/a\u003e into vector embeddings, which are then stored in the Zilliz Cloud vector database for efficient indexing and retrieval. There are features that allow you to choose or customize the \u003ca href=\"https://docs.zilliz.com/docs/pipelines-ingest-search-delete-data\"\u003esplitter\u003c/a\u003e that is included. By default, Zilliz Cloud Pipelines uses \u0026quot;\\n\\n\u0026quot;, \u0026quot;\\n\u0026quot;, \u0026quot; \u0026quot;, \u0026quot;\u0026quot; as separators. You can also choose to split the document by sentences (use \u0026quot;.\u0026quot;, \u0026quot;\u0026quot; as separators ), paragraphs (use \u0026quot;\\n\\n\u0026quot;, \u0026quot;\u0026quot; as separators), lines (use \u0026quot;\\n\u0026quot;, \u0026quot;\u0026quot; as separators), or a list of customized strings.\u003c/p\u003e\u003c/li\u003e\n\u003c/ul\u003e\n\u003cp\u003eIncorporating these tools into the \u003ca href=\"https://zilliz.com/learn/how-to-enhance-the-performance-of-your-rag-pipeline\"\u003eRAG pipeline\u003c/a\u003e allows developers to experiment with different chunking strategies and directly observe their impact on system performance. This experimentation can significantly improve how information is retrieved and processed, ultimately enhancing the overall effectiveness of the RAG system.\u003c/p\u003e\n\u003ch2 id=\"Performance-Optimization-in-RAG-Systems-Through-Chunking-Strategies\" class=\"common-anchor-header\"\u003e\u003cstrong\u003ePerformance Optimization in RAG Systems Through Chunking Strategies\u003c/strong\u003e\u003cbutton data-href=\"#Performance-Optimization-in-RAG-Systems-Through-Chunking-Strategies\" class=\"anchor-icon\" translate=\"no\"\u003e\n \u003csvg\n aria-hidden=\"true\"\n focusable=\"false\"\n height=\"20\"\n version=\"1.1\"\n viewBox=\"0 0 16 16\"\n width=\"16\"\n \u003e\n \u003cpath\n fill=\"#0092E4\"\n fill-rule=\"evenodd\"\n d=\"M4 9h1v1H4c-1.5 0-3-1.69-3-3.5S2.55 3 4 3h4c1.45 0 3 1.69 3 3.5 0 1.41-.91 2.72-2 3.25V8.59c.58-.45 1-1.27 1-2.09C10 5.22 8.98 4 8 4H4c-.98 0-2 1.22-2 2.5S3 9 4 9zm9-3h-1v1h1c1 0 2 1.22 2 2.5S13.98 12 13 12H9c-.98 0-2-1.22-2-2.5 0-.83.42-1.64 1-2.09V6.25c-1.09.53-2 1.84-2 3.25C6 11.31 7.55 13 9 13h4c1.45 0 3-1.69 3-3.5S14.5 6 13 6z\"\n \u003e\u003c/path\u003e\n \u003c/svg\u003e\n \u003c/button\u003e\u003c/h2\u003e\u003cp\u003eOptimizing RAG systems involves carefully monitoring and evaluating how different chunking strategies impact performance. This optimization ensures that the system not only retrieves relevant information quickly but also generates coherent and contextually appropriate responses when processing information.\u003c/p\u003e\n\u003ch3 id=\"Monitoring-and-Evaluating-the-Impact-of-Different-Chunking-Strategies\" class=\"common-anchor-header\"\u003e\u003cstrong\u003eMonitoring and Evaluating the Impact of Different Chunking Strategies\u003c/strong\u003e\u003cbutton data-href=\"#Monitoring-and-Evaluating-the-Impact-of-Different-Chunking-Strategies\" class=\"anchor-icon\" translate=\"no\"\u003e\n \u003csvg\n aria-hidden=\"true\"\n focusable=\"false\"\n height=\"20\"\n version=\"1.1\"\n viewBox=\"0 0 16 16\"\n width=\"16\"\n \u003e\n \u003cpath\n fill=\"#0092E4\"\n fill-rule=\"evenodd\"\n d=\"M4 9h1v1H4c-1.5 0-3-1.69-3-3.5S2.55 3 4 3h4c1.45 0 3 1.69 3 3.5 0 1.41-.91 2.72-2 3.25V8.59c.58-.45 1-1.27 1-2.09C10 5.22 8.98 4 8 4H4c-.98 0-2 1.22-2 2.5S3 9 4 9zm9-3h-1v1h1c1 0 2 1.22 2 2.5S13.98 12 13 12H9c-.98 0-2-1.22-2-2.5 0-.83.42-1.64 1-2.09V6.25c-1.09.53-2 1.84-2 3.25C6 11.31 7.55 13 9 13h4c1.45 0 3-1.69 3-3.5S14.5 6 13 6z\"\n \u003e\u003c/path\u003e\n \u003c/svg\u003e\n \u003c/button\u003e\u003c/h3\u003e\u003col\u003e\n\u003cli\u003e\u003cstrong\u003eSetting Performance Benchmarks:\u003c/strong\u003e Before modifying chunking strategies, it's crucial to establish baseline performance metrics. This might include metrics like response time, \u003ca href=\"https://zilliz.com/learn/what-is-information-retrieval\"\u003einformation retrieval\u003c/a\u003e accuracy, and the generated text's coherence.\u003c/li\u003e\n\u003c/ol\u003e\n\u003col\u003e\n\u003cli\u003e\u003cstrong\u003eExperimentation:\u003c/strong\u003e Implement different chunking strategies—such as fixed-size, semantic, and dynamic chunking—and measure how each impacts performance. This experimental phase should be controlled and systematic to isolate the effects of chunking from other variables.\u003c/li\u003e\n\u003c/ol\u003e\n\u003col\u003e\n\u003cli\u003e\u003cstrong\u003eContinuous Monitoring:\u003c/strong\u003e Use logging and monitoring tools to track performance over time. This ongoing data collection is vital for understanding long-term trends and the stability of improvements under different operational conditions.\u003c/li\u003e\n\u003c/ol\u003e\n\u003ch3 id=\"Metrics-and-Tools-for-Assessing-Chunking-Effectiveness\" class=\"common-anchor-header\"\u003e\u003cstrong\u003eMetrics and Tools for Assessing Chunking Effectiveness\u003c/strong\u003e\u003cbutton data-href=\"#Metrics-and-Tools-for-Assessing-Chunking-Effectiveness\" class=\"anchor-icon\" translate=\"no\"\u003e\n \u003csvg\n aria-hidden=\"true\"\n focusable=\"false\"\n height=\"20\"\n version=\"1.1\"\n viewBox=\"0 0 16 16\"\n width=\"16\"\n \u003e\n \u003cpath\n fill=\"#0092E4\"\n fill-rule=\"evenodd\"\n d=\"M4 9h1v1H4c-1.5 0-3-1.69-3-3.5S2.55 3 4 3h4c1.45 0 3 1.69 3 3.5 0 1.41-.91 2.72-2 3.25V8.59c.58-.45 1-1.27 1-2.09C10 5.22 8.98 4 8 4H4c-.98 0-2 1.22-2 2.5S3 9 4 9zm9-3h-1v1h1c1 0 2 1.22 2 2.5S13.98 12 13 12H9c-.98 0-2-1.22-2-2.5 0-.83.42-1.64 1-2.09V6.25c-1.09.53-2 1.84-2 3.25C6 11.31 7.55 13 9 13h4c1.45 0 3-1.69 3-3.5S14.5 6 13 6z\"\n \u003e\u003c/path\u003e\n \u003c/svg\u003e\n \u003c/button\u003e\u003c/h3\u003e\u003cp\u003e\u003cstrong\u003eMetrics:\u003c/strong\u003e\u003c/p\u003e\n\u003cul\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003ePrecision and Recall:\u003c/strong\u003e These metrics are critical for evaluating the accuracy and completeness of the information retrieved by the RAG system.\u003c/p\u003e\u003c/li\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003eResponse Time:\u003c/strong\u003e Measures the time taken from receiving a query to providing an answer, indicating the efficiency of the retrieval process.\u003c/p\u003e\u003c/li\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003eConsistency and Coherence:\u003c/strong\u003e The logical flow and relevance of text generated based on the chunked inputs are crucial for assessing chunking effectiveness in generative tasks.\u003c/p\u003e\u003c/li\u003e\n\u003c/ul\u003e\n\u003cp\u003e\u003cstrong\u003eTools:\u003c/strong\u003e\u003c/p\u003e\n\u003cul\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003eAnalytics Dashboards:\u003c/strong\u003e Tools like \u003cstrong\u003eGrafana\u003c/strong\u003e or \u003cstrong\u003eKibana\u003c/strong\u003e can be integrated to visualize performance metrics in real-time.\u003c/p\u003e\u003c/li\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003eProfiling Software:\u003c/strong\u003e Profiling tools specific to machine learning workflows, such as \u003cstrong\u003eProfiler\u003c/strong\u003e or \u003cstrong\u003eTensorBoard\u003c/strong\u003e, can help identify bottlenecks at the chunking stage.\u003c/p\u003e\u003c/li\u003e\n\u003c/ul\u003e\n\u003ch3 id=\"Strategies-for-Tuning-and-Refining-Chunking-Parameters-Based-on-Performance-Data\" class=\"common-anchor-header\"\u003e\u003cstrong\u003eStrategies for Tuning and Refining Chunking Parameters Based on Performance Data\u003c/strong\u003e\u003cbutton data-href=\"#Strategies-for-Tuning-and-Refining-Chunking-Parameters-Based-on-Performance-Data\" class=\"anchor-icon\" translate=\"no\"\u003e\n \u003csvg\n aria-hidden=\"true\"\n focusable=\"false\"\n height=\"20\"\n version=\"1.1\"\n viewBox=\"0 0 16 16\"\n width=\"16\"\n \u003e\n \u003cpath\n fill=\"#0092E4\"\n fill-rule=\"evenodd\"\n d=\"M4 9h1v1H4c-1.5 0-3-1.69-3-3.5S2.55 3 4 3h4c1.45 0 3 1.69 3 3.5 0 1.41-.91 2.72-2 3.25V8.59c.58-.45 1-1.27 1-2.09C10 5.22 8.98 4 8 4H4c-.98 0-2 1.22-2 2.5S3 9 4 9zm9-3h-1v1h1c1 0 2 1.22 2 2.5S13.98 12 13 12H9c-.98 0-2-1.22-2-2.5 0-.83.42-1.64 1-2.09V6.25c-1.09.53-2 1.84-2 3.25C6 11.31 7.55 13 9 13h4c1.45 0 3-1.69 3-3.5S14.5 6 13 6z\"\n \u003e\u003c/path\u003e\n \u003c/svg\u003e\n \u003c/button\u003e\u003c/h3\u003e\u003col\u003e\n\u003cli\u003e\u003cstrong\u003eData-Driven Adjustments:\u003c/strong\u003e Use the collected performance data to decide which chunking parameters (e.g., size, overlap) to adjust. For example, if larger chunks are slowing down the system but increasing accuracy, a balance needs to be found that optimizes both aspects.\u003c/li\u003e\n\u003c/ol\u003e\n\u003col\u003e\n\u003cli\u003e\u003cstrong\u003eA/B Testing:\u003c/strong\u003e Conduct A/B testing using different chunking strategies to directly compare their impact on system performance. This approach allows for side-by-side comparisons and more confident decision-making.\u003c/li\u003e\n\u003c/ol\u003e\n\u003col\u003e\n\u003cli\u003e\u003cstrong\u003eFeedback Loops:\u003c/strong\u003e Implement a feedback system where the outputs of the RAG are evaluated either by users or through automated systems to provide continuous feedback on the quality of the generated content. This feedback can be used to fine-tune chunking parameters dynamically.\u003c/li\u003e\n\u003c/ol\u003e\n\u003col\u003e\n\u003cli\u003e\u003cstrong\u003eMachine Learning Optimization Algorithms:\u003c/strong\u003e Utilize machine learning techniques such as reinforcement learning or genetic algorithms to find optimal chunking configurations based on performance metrics automatically.\u003c/li\u003e\n\u003c/ol\u003e\n\u003cp\u003eBy carefully monitoring, evaluating, and continuously refining the chunking strategies in RAG systems, developers can significantly enhance their systems' efficiency and effectiveness.\u003c/p\u003e\n\u003ch2 id=\"Case-Studies-on-Successful-RAG-Implementations-with-Innovative-Chunking-Strategies\" class=\"common-anchor-header\"\u003e\u003cstrong\u003eCase Studies on Successful RAG Implementations with Innovative Chunking Strategies\u003c/strong\u003e\u003cbutton data-href=\"#Case-Studies-on-Successful-RAG-Implementations-with-Innovative-Chunking-Strategies\" class=\"anchor-icon\" translate=\"no\"\u003e\n \u003csvg\n aria-hidden=\"true\"\n focusable=\"false\"\n height=\"20\"\n version=\"1.1\"\n viewBox=\"0 0 16 16\"\n width=\"16\"\n \u003e\n \u003cpath\n fill=\"#0092E4\"\n fill-rule=\"evenodd\"\n d=\"M4 9h1v1H4c-1.5 0-3-1.69-3-3.5S2.55 3 4 3h4c1.45 0 3 1.69 3 3.5 0 1.41-.91 2.72-2 3.25V8.59c.58-.45 1-1.27 1-2.09C10 5.22 8.98 4 8 4H4c-.98 0-2 1.22-2 2.5S3 9 4 9zm9-3h-1v1h1c1 0 2 1.22 2 2.5S13.98 12 13 12H9c-.98 0-2-1.22-2-2.5 0-.83.42-1.64 1-2.09V6.25c-1.09.53-2 1.84-2 3.25C6 11.31 7.55 13 9 13h4c1.45 0 3-1.69 3-3.5S14.5 6 13 6z\"\n \u003e\u003c/path\u003e\n \u003c/svg\u003e\n \u003c/button\u003e\u003c/h2\u003e\u003cul\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003eCase Study 1 - Dynamic Windowed Summarization:\u003c/strong\u003e One example of a successful RAG implementation involved an additive preprocessing technique called windowed summarization. This approach enriched text chunks with summaries of adjacent chunks to provide a broader context. This method allowed the system to adjust the \u0026quot;window size\u0026quot; dynamically, exploring different scopes of context, which enhanced the understanding of each chunk. The enriched context improved the quality of responses by making them more relevant and contextually nuanced. This case highlighted the benefits of context-enriched chunking in a RAG setup, where the retrieval component could leverage broader contextual cues to enhance answer quality and relevance (Optimizing Retrieval-Augmented Generation with Advanced Chunking Techniques: \u003ca href=\"https://antematter.io/blogs/optimizing-rag-advanced-chunking-techniques-study\"\u003eA Comparative Study\u003c/a\u003e).\u003c/p\u003e\u003c/li\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003eCase Study 2 - Advanced Semantic Chunking:\u003c/strong\u003e Advanced Semantic Chunking: Another successful implementation of a successful RAG implementation involves advanced semantic chunking techniques to enhance retrieval performance. By dividing documents into semantically coherent chunks rather than merely based on size or token count, the system significantly improved its ability to retrieve relevant information. This strategy ensured each chunk maintained its contextual integrity, leading to more accurate and coherent generation outputs. Implementing such chunking techniques required a deep understanding of both the content structure and the specific demands of the retrieval and generation processes involved in the RAG system (\u003ca href=\"https://www.rungalileo.io/blog/mastering-rag-advanced-chunking-techniques-for-llm-applications\"\u003eMastering RAG: Advanced Chunking Techniques for LLM Applications\u003c/a\u003e).\u003c/p\u003e\u003c/li\u003e\n\u003c/ul\u003e\n\u003ch2 id=\"Conclusion-The-Strategic-Significance-of-Chunking-in-RAG-Systems\" class=\"common-anchor-header\"\u003e\u003cstrong\u003eConclusion: The Strategic Significance of Chunking in RAG Systems\u003c/strong\u003e\u003cbutton data-href=\"#Conclusion-The-Strategic-Significance-of-Chunking-in-RAG-Systems\" class=\"anchor-icon\" translate=\"no\"\u003e\n \u003csvg\n aria-hidden=\"true\"\n focusable=\"false\"\n height=\"20\"\n version=\"1.1\"\n viewBox=\"0 0 16 16\"\n width=\"16\"\n \u003e\n \u003cpath\n fill=\"#0092E4\"\n fill-rule=\"evenodd\"\n d=\"M4 9h1v1H4c-1.5 0-3-1.69-3-3.5S2.55 3 4 3h4c1.45 0 3 1.69 3 3.5 0 1.41-.91 2.72-2 3.25V8.59c.58-.45 1-1.27 1-2.09C10 5.22 8.98 4 8 4H4c-.98 0-2 1.22-2 2.5S3 9 4 9zm9-3h-1v1h1c1 0 2 1.22 2 2.5S13.98 12 13 12H9c-.98 0-2-1.22-2-2.5 0-.83.42-1.64 1-2.09V6.25c-1.09.53-2 1.84-2 3.25C6 11.31 7.55 13 9 13h4c1.45 0 3-1.69 3-3.5S14.5 6 13 6z\"\n \u003e\u003c/path\u003e\n \u003c/svg\u003e\n \u003c/button\u003e\u003c/h2\u003e\u003cp\u003eWe've explored various facets of chunking strategies within Retrieval-Augmented Generation (RAG) systems. From understanding the basics of the chunking process to diving into advanced techniques and real-world applications, with emphasis the role chunking plays in the performance of RAG systems.\u003c/p\u003e\n\u003ch2 id=\"Recap-of-Key-Points\" class=\"common-anchor-header\"\u003e\u003cstrong\u003eRecap of Key Points\u003c/strong\u003e\u003cbutton data-href=\"#Recap-of-Key-Points\" class=\"anchor-icon\" translate=\"no\"\u003e\n \u003csvg\n aria-hidden=\"true\"\n focusable=\"false\"\n height=\"20\"\n version=\"1.1\"\n viewBox=\"0 0 16 16\"\n width=\"16\"\n \u003e\n \u003cpath\n fill=\"#0092E4\"\n fill-rule=\"evenodd\"\n d=\"M4 9h1v1H4c-1.5 0-3-1.69-3-3.5S2.55 3 4 3h4c1.45 0 3 1.69 3 3.5 0 1.41-.91 2.72-2 3.25V8.59c.58-.45 1-1.27 1-2.09C10 5.22 8.98 4 8 4H4c-.98 0-2 1.22-2 2.5S3 9 4 9zm9-3h-1v1h1c1 0 2 1.22 2 2.5S13.98 12 13 12H9c-.98 0-2-1.22-2-2.5 0-.83.42-1.64 1-2.09V6.25c-1.09.53-2 1.84-2 3.25C6 11.31 7.55 13 9 13h4c1.45 0 3-1.69 3-3.5S14.5 6 13 6z\"\n \u003e\u003c/path\u003e\n \u003c/svg\u003e\n \u003c/button\u003e\u003c/h2\u003e\u003cul\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003eBasic Principles:\u003c/strong\u003e Chunking refers to breaking down large text datasets into manageable pieces that improve the efficiency of information retrieval and text generation processes.\u003c/p\u003e\u003c/li\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003eChunking Strategies:\u003c/strong\u003e Various chunking strategies like fixed-size, semantic, and dynamic chunking can be implemented, based on the use case, its advantages, scenarios of best use and disadvantages.\u003c/p\u003e\u003c/li\u003e\n\u003c/ul\u003e\n\u003cul\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003eImpact on RAG Systems:\u003c/strong\u003e The interaction between chunking and other RAG components such as the retriever and generator should be assessed, as different chunking approaches can influence the overall system performance.\u003c/p\u003e\u003c/li\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003eTools and Metrics:\u003c/strong\u003e The tools and metrics that can be used to monitor and evaluate the effectiveness of chunking strategies are critical for ongoing optimization efforts.\u003c/p\u003e\u003c/li\u003e\n\u003cli\u003e\u003cp\u003e\u003cstrong\u003eReal-World Case Studies:\u003c/strong\u003e Examples from successful implementations illustrated how innovative chunking strategies can lead to significant improvements in RAG systems.\u003c/p\u003e\u003c/li\u003e\n\u003c/ul\u003e\n\u003ch2 id=\"Final-Thoughts-on-Choosing-the-Right-Chunking-Strategy\" class=\"common-anchor-header\"\u003e\u003cstrong\u003eFinal Thoughts on Choosing the Right Chunking Strategy\u003c/strong\u003e\u003cbutton data-href=\"#Final-Thoughts-on-Choosing-the-Right-Chunking-Strategy\" class=\"anchor-icon\" translate=\"no\"\u003e\n \u003csvg\n aria-hidden=\"true\"\n focusable=\"false\"\n height=\"20\"\n version=\"1.1\"\n viewBox=\"0 0 16 16\"\n width=\"16\"\n \u003e\n \u003cpath\n fill=\"#0092E4\"\n fill-rule=\"evenodd\"\n d=\"M4 9h1v1H4c-1.5 0-3-1.69-3-3.5S2.55 3 4 3h4c1.45 0 3 1.69 3 3.5 0 1.41-.91 2.72-2 3.25V8.59c.58-.45 1-1.27 1-2.09C10 5.22 8.98 4 8 4H4c-.98 0-2 1.22-2 2.5S3 9 4 9zm9-3h-1v1h1c1 0 2 1.22 2 2.5S13.98 12 13 12H9c-.98 0-2-1.22-2-2.5 0-.83.42-1.64 1-2.09V6.25c-1.09.53-2 1.84-2 3.25C6 11.31 7.55 13 9 13h4c1.45 0 3-1.69 3-3.5S14.5 6 13 6z\"\n \u003e\u003c/path\u003e\n \u003c/svg\u003e\n \u003c/button\u003e\u003c/h2\u003e\u003cp\u003eChoosing the appropriate advanced RAG techniques is paramount in enhancing the functionality and efficiency of RAG systems. The right strategy utilize chunking ensures that the system not only retrieves the most relevant information but also generates coherent and contextually rich responses to relevant documents. The impact of well-implemented chunking strategies on RAG performance can influence the precision of information retrieval and the quality of content generation.\u003c/p\u003e\n\u003ch2 id=\"Further-Reading-and-Resources-on-RAG-and-Chunking\" class=\"common-anchor-header\"\u003e\u003cstrong\u003eFurther Reading and Resources on RAG and Chunking\u003c/strong\u003e\u003cbutton data-href=\"#Further-Reading-and-Resources-on-RAG-and-Chunking\" class=\"anchor-icon\" translate=\"no\"\u003e\n \u003csvg\n aria-hidden=\"true\"\n focusable=\"false\"\n height=\"20\"\n version=\"1.1\"\n viewBox=\"0 0 16 16\"\n width=\"16\"\n \u003e\n \u003cpath\n fill=\"#0092E4\"\n fill-rule=\"evenodd\"\n d=\"M4 9h1v1H4c-1.5 0-3-1.69-3-3.5S2.55 3 4 3h4c1.45 0 3 1.69 3 3.5 0 1.41-.91 2.72-2 3.25V8.59c.58-.45 1-1.27 1-2.09C10 5.22 8.98 4 8 4H4c-.98 0-2 1.22-2 2.5S3 9 4 9zm9-3h-1v1h1c1 0 2 1.22 2 2.5S13.98 12 13 12H9c-.98 0-2-1.22-2-2.5 0-.83.42-1.64 1-2.09V6.25c-1.09.53-2 1.84-2 3.25C6 11.31 7.55 13 9 13h4c1.45 0 3-1.69 3-3.5S14.5 6 13 6z\"\n \u003e\u003c/path\u003e\n \u003c/svg\u003e\n \u003c/button\u003e\u003c/h2\u003e\u003cul\u003e\n\u003cli\u003e\u003cp\u003eFor a foundational understanding, the original paper by Lewis et al. on RAG is essential. It offers in-depth explanations of the mechanisms and applications of RAG in knowledge-intensive NLP tasks.\u003c/p\u003e\u003c/li\u003e\n\u003cli\u003e\u003cp\u003e\u0026quot;Mastering RAG: Advanced Chunking Techniques for LLM Applications\u0026quot; on Galileo provides a deeper dive into various chunking strategies and their impact on RAG system performance, emphasizing the integration of \u003ca href=\"https://zilliz.com/glossary/large-language-models-(llms)\"\u003eLLMs\u003c/a\u003e for enhanced retrieval and generation processes.\u003c/p\u003e\u003c/li\u003e\n\u003cli\u003e\u003cp\u003eJoining AI and NLP communities such as those found on Stack Overflow, Reddit (r/MachineLearning), or Towards AI can provide ongoing support and discussion forums. These platforms allow practitioners to share insights, ask questions, and find solutions related to RAG and chunking methods\u003c/p\u003e\u003c/li\u003e\n\u003c/ul\u003e\n","abstract":"We explored various facets of chunking strategies within Retrieval-Augmented Generation (RAG) systems in this guide. ","url":"guide-to-chunking-strategies-for-rag","codeList":["def fixed_size_chunking(text, chunk_size=100):\n return [text[i:i+chunk_size] for i in range(0, len(text), chunk_size)]\n"],"image":{"id":3805,"name":"May 19 ——A Guide to Chunking Strategies for Retrieval Augmented Generation (RAG).png","alternativeText":"","caption":"","width":2400,"height":1256,"formats":{"large":{"ext":".png","url":"https://assets.zilliz.com/large_May_19_A_Guide_to_Chunking_Strategies_for_Retrieval_Augmented_Generation_RAG_1079ea179b.png","hash":"large_May_19_A_Guide_to_Chunking_Strategies_for_Retrieval_Augmented_Generation_RAG_1079ea179b","mime":"image/png","name":"large_May 19 ——A Guide to Chunking Strategies for Retrieval Augmented Generation (RAG).png","path":null,"size":383.33,"width":1000,"height":523},"small":{"ext":".png","url":"https://assets.zilliz.com/small_May_19_A_Guide_to_Chunking_Strategies_for_Retrieval_Augmented_Generation_RAG_1079ea179b.png","hash":"small_May_19_A_Guide_to_Chunking_Strategies_for_Retrieval_Augmented_Generation_RAG_1079ea179b","mime":"image/png","name":"small_May 19 ——A Guide to Chunking Strategies for Retrieval Augmented Generation (RAG).png","path":null,"size":95.67,"width":500,"height":262},"medium":{"ext":".png","url":"https://assets.zilliz.com/medium_May_19_A_Guide_to_Chunking_Strategies_for_Retrieval_Augmented_Generation_RAG_1079ea179b.png","hash":"medium_May_19_A_Guide_to_Chunking_Strategies_for_Retrieval_Augmented_Generation_RAG_1079ea179b","mime":"image/png","name":"medium_May 19 ——A Guide to Chunking Strategies for Retrieval Augmented Generation (RAG).png","path":null,"size":199.02,"width":750,"height":393},"thumbnail":{"ext":".png","url":"https://assets.zilliz.com/thumbnail_May_19_A_Guide_to_Chunking_Strategies_for_Retrieval_Augmented_Generation_RAG_1079ea179b.png","hash":"thumbnail_May_19_A_Guide_to_Chunking_Strategies_for_Retrieval_Augmented_Generation_RAG_1079ea179b","mime":"image/png","name":"thumbnail_May 19 ——A Guide to Chunking Strategies for Retrieval Augmented Generation (RAG).png","path":null,"size":32.53,"width":245,"height":128}},"hash":"May_19_A_Guide_to_Chunking_Strategies_for_Retrieval_Augmented_Generation_RAG_1079ea179b","ext":".png","mime":"image/png","size":1805.07,"url":"https://assets.zilliz.com/May_19_A_Guide_to_Chunking_Strategies_for_Retrieval_Augmented_Generation_RAG_1079ea179b.png","previewUrl":null,"provider":"s3","provider_metadata":null,"created_by":60,"updated_by":60,"created_at":"2024-06-21T07:32:59.039Z","updated_at":"2024-06-21T07:32:59.051Z"},"canonical_rel":"https://zilliz.com/learn/guide-to-chunking-strategies-for-rag","read_time":16,"blogId":"learn-192","meta_title":"A Guide to Chunking Strategies for Retrieval Augmented Generation (RAG)","meta_description":"We explored various facets of chunking strategies within Retrieval-Augmented Generation (RAG) systems in this guide. ","meta_keywords":null,"display_updated_time":"Mar 12, 2025"},"anchors":[{"label":"What is Retrieval Augmented Generation (RAG)?","href":"What-is-Retrieval-Augmented-Generation-RAG","type":2,"isActive":false},{"label":"Significance of RAG in NLP","href":"Significance-of-RAG-in-NLP","type":2,"isActive":false},{"label":"Chunking","href":"Chunking","type":2,"isActive":false},{"label":"Detailed Exploration of Chunking Strategies in RAG Systems","href":"Detailed-Exploration-of-Chunking-Strategies-in-RAG-Systems","type":2,"isActive":false},{"label":"**Chunking and Vectorization in Text Retrieval**","href":"Chunking-and-Vectorization-in-Text-Retrieval","type":2,"isActive":false},{"label":"**Implementing Chunking in RAG Pipelines**","href":"Implementing-Chunking-in-RAG-Pipelines","type":2,"isActive":false},{"label":"**Performance Optimization in RAG Systems Through Chunking Strategies**","href":"Performance-Optimization-in-RAG-Systems-Through-Chunking-Strategies","type":2,"isActive":false},{"label":"**Case Studies on Successful RAG Implementations with Innovative Chunking Strategies**","href":"Case-Studies-on-Successful-RAG-Implementations-with-Innovative-Chunking-Strategies","type":2,"isActive":false},{"label":"**Conclusion: The Strategic Significance of Chunking in RAG Systems**","href":"Conclusion-The-Strategic-Significance-of-Chunking-in-RAG-Systems","type":2,"isActive":false},{"label":"**Recap of Key Points**","href":"Recap-of-Key-Points","type":2,"isActive":false},{"label":"**Final Thoughts on Choosing the Right Chunking Strategy**","href":"Final-Thoughts-on-Choosing-the-Right-Chunking-Strategy","type":2,"isActive":false},{"label":"**Further Reading and Resources on RAG and Chunking**","href":"Further-Reading-and-Resources-on-RAG-and-Chunking","type":2,"isActive":false}],"seriesName":"Retrieval Augmented Generation (RAG) 101","seriesArticles":[{"id":75,"title":"Build AI Apps with Retrieval Augmented Generation (RAG)","sub_title":"Build AI Apps with Retrieval Augmented Generation (RAG)","featured":null,"abstract":"A comprehensive guide to Retrieval Augmented Generation (RAG), including its definition, workflow, benefits, use cases, and challenges. ","display_time":"2024-01-08","url":"Retrieval-Augmented-Generation","home_order":null,"published_at":"2024-01-08T03:09:33.960Z","created_by":60,"updated_by":60,"created_at":"2024-01-08T02:39:29.799Z","updated_at":"2025-03-24T08:48:34.145Z","show_in_learn":true,"order_in_learn":null,"category_order":null,"category_learn":null,"author":36,"canonical_rel":"https://zilliz.com/learn/Retrieval-Augmented-Generation","repost_to_medium":false,"repost_state":null,"meta_title":"What is RAG?","meta_description":"A comprehensive guide to Retrieval Augmented Generation (RAG), including its definition, workflow, benefits, use cases, and challenges. ","meta_keywords":null,"invisible":null,"locale":"en","repost_to_devto":null,"belong":"learn","read_time":13,"seriesName":"Retrieval Augmented Generation (RAG) 101"},{"id":94,"title":"Mastering LLM Challenges: An Exploration of Retrieval Augmented Generation","sub_title":"A four-part series RAG handbook","featured":null,"abstract":"This four-part series handbook looks into RAG, exploring its architecture, advantages, the challenges it can address, and why it stands as the preferred choice for elevating the performance of generative AI applications.","display_time":"2024-03-22","url":"RAG-handbook","home_order":null,"published_at":"2024-03-23T23:44:40.992Z","created_by":53,"updated_by":60,"created_at":"2024-03-23T22:44:35.239Z","updated_at":"2025-04-01T00:00:22.050Z","show_in_learn":true,"order_in_learn":null,"category_order":null,"category_learn":null,"author":107,"canonical_rel":"https://zilliz.com/learn/RAG-handbook","repost_to_medium":true,"repost_state":{"status":"success","mediumId":"27e06247886d","mediumUrl":"https://medium.com/@zilliz_learn/mastering-llm-challenges-an-exploration-of-retrieval-augmented-generation-27e06247886d"},"meta_title":"Mastering LLM Challenges: An Exploration of RAG","meta_description":"This RAG handbook explores its advantages, the challenges it can address, \u0026 why its the preferred choice for elevating the performance of gen AI apps.","meta_keywords":null,"invisible":null,"locale":"en","repost_to_devto":null,"belong":"learn","read_time":6,"seriesName":"Retrieval Augmented Generation (RAG) 101"},{"id":95,"title":"Key NLP technologies in Deep Learning","sub_title":null,"featured":null,"abstract":"An exploration of the evolution and fundamental principles underlying key Natural Language Processing (NLP) technologies within Deep Learning.","display_time":"2024-03-23","url":"nlp-technologies-in-deep-learning","home_order":null,"published_at":"2024-03-23T23:56:41.245Z","created_by":53,"updated_by":60,"created_at":"2024-03-23T23:52:38.787Z","updated_at":"2025-04-01T00:00:22.194Z","show_in_learn":true,"order_in_learn":null,"category_order":null,"category_learn":null,"author":107,"canonical_rel":"https://zilliz.com/learn/nlp-technologies-in-deep-learning","repost_to_medium":true,"repost_state":{"status":"success","mediumId":"94f33b7d4da7","mediumUrl":"https://medium.com/@zilliz_learn/key-nlp-technologies-in-deep-learning-94f33b7d4da7"},"meta_title":"Key NLP technologies in Deep Learning","meta_description":"An exploration of the evolution and fundamental principles underlying key Natural Language Processing (NLP) technologies within Deep Learning.","meta_keywords":null,"invisible":null,"locale":"en","repost_to_devto":null,"belong":"learn","read_time":11,"seriesName":"Retrieval Augmented Generation (RAG) 101"},{"id":97,"title":"How to Evaluate RAG Applications","sub_title":null,"featured":null,"abstract":"A comparative analysis of evaluating RAG applications, addressing the challenge of determining their relative effectiveness. It explores quantitative metrics for developers to enhance their RAG application performance.\n\n\n\n\n\n\n","display_time":"2024-03-23","url":"How-To-Evaluate-RAG-Applications","home_order":null,"published_at":"2024-03-24T02:41:17.176Z","created_by":53,"updated_by":125,"created_at":"2024-03-24T02:18:44.324Z","updated_at":"2025-04-07T03:26:19.339Z","show_in_learn":true,"order_in_learn":null,"category_order":null,"category_learn":null,"author":107,"canonical_rel":"https://zilliz.com/learn/How-To-Evaluate-RAG-Applications","repost_to_medium":true,"repost_state":{"status":"success","mediumId":"e2936c1275f9","mediumUrl":"https://medium.com/@zilliz_learn/how-to-evaluate-rag-applications-e2936c1275f9"},"meta_title":"How to Evaluate RAG Applications","meta_description":"Effective Evaluation strategies for your RAG Application","meta_keywords":null,"invisible":null,"locale":"en","repost_to_devto":null,"belong":"learn","read_time":13,"seriesName":"Retrieval Augmented Generation (RAG) 101"},{"id":121,"title":"Optimizing RAG with Rerankers: The Role and Trade-offs ","sub_title":null,"featured":true,"abstract":"Rerankers can enhance the accuracy and relevance of answers in RAG systems, but these benefits come with increased latency and computational costs.","display_time":"2024-04-02","url":"optimize-rag-with-rerankers-the-role-and-tradeoffs","home_order":null,"published_at":"2024-04-01T18:34:05.783Z","created_by":60,"updated_by":60,"created_at":"2024-04-01T17:07:44.767Z","updated_at":"2025-03-12T05:34:15.325Z","show_in_learn":true,"order_in_learn":null,"category_order":null,"category_learn":null,"author":101,"canonical_rel":"https://zilliz.com/learn/optimize-rag-with-rerankers-the-role-and-tradeoffs","repost_to_medium":true,"repost_state":{"status":"success","mediumId":"250bf4b3e09e","mediumUrl":"https://medium.com/@zilliz_learn/optimizing-rag-with-rerankers-the-role-and-trade-offs-250bf4b3e09e"},"meta_title":"Optimizing RAG with Rerankers: The Role and Trade-offs ","meta_description":"Rerankers can enhance the accuracy and relevance of answers in RAG systems, but these benefits come with increased latency and computational costs.","meta_keywords":null,"invisible":null,"locale":"en","repost_to_devto":null,"belong":"learn","read_time":13,"seriesName":"Retrieval Augmented Generation (RAG) 101"},{"id":125,"title":"Exploring the Frontier of Multimodal Retrieval-Augmented Generation (RAG)","sub_title":null,"featured":null,"abstract":"Multimodal RAG is an extended RAG framework incorporating multimodal data including various data types such as text, images, audio, videos etc. ","display_time":"2024-02-21","url":"multimodal-RAG","home_order":null,"published_at":"2024-04-01T19:03:53.071Z","created_by":60,"updated_by":60,"created_at":"2024-04-01T19:00:58.682Z","updated_at":"2025-05-01T00:00:23.261Z","show_in_learn":true,"order_in_learn":null,"category_order":null,"category_learn":null,"author":137,"canonical_rel":"https://zilliz.com/learn/multimodal-RAG","repost_to_medium":true,"repost_state":{"status":"success","mediumId":"feeb1b3ed7a2","mediumUrl":"https://medium.com/@zilliz_learn/exploring-the-frontier-of-multimodal-retrieval-augmented-generation-rag-feeb1b3ed7a2"},"meta_title":"Exploring the Frontier of Multimodal Retrieval-Augmented Generation (RAG)","meta_description":"Multimodal RAG is an extended RAG framework incorporating multimodal data including various data types such as text, images, audio, videos etc. ","meta_keywords":null,"invisible":null,"locale":"en","repost_to_devto":null,"belong":"learn","read_time":5,"seriesName":"Retrieval Augmented Generation (RAG) 101"},{"id":134,"title":"Enhancing ChatGPT with Milvus: Powering AI with Long-Term Memory","sub_title":null,"featured":null,"abstract":"By integrating GPTCache and Milvus with ChatGPT, businesses can create a more robust and efficient AI-powered support system. This approach leverages the advanced capabilities of generative AI and introduces a form of long-term memory, allowing the AI to recall and reuse information effectively.","display_time":"2024-04-08","url":"enhancing-chatgpt-with-milvus","home_order":null,"published_at":"2024-04-15T17:34:32.668Z","created_by":82,"updated_by":21,"created_at":"2024-04-04T17:45:13.388Z","updated_at":"2025-07-01T00:00:27.924Z","show_in_learn":true,"order_in_learn":null,"category_order":null,"category_learn":null,"author":135,"canonical_rel":"","repost_to_medium":true,"repost_state":{"status":"success","mediumId":"9d3810961c3b","mediumUrl":"https://medium.com/@zilliz_learn/enhancing-chatgpt-with-milvus-powering-ai-with-long-term-memory-9d3810961c3b"},"meta_title":"Enhancing ChatGPT with Milvus: Powering AI with Long-Term Memory","meta_description":"By integrating GPTCache and Milvus with ChatGPT, businesses can create a more robust and efficient AI-powered support system. This approach leverages the advanced capabilities of generative AI and introduces a form of long-term memory, allowing the AI to recall and reuse information effectively.","meta_keywords":null,"invisible":null,"locale":"en","repost_to_devto":null,"belong":"learn","read_time":5,"seriesName":"Retrieval Augmented Generation (RAG) 101"},{"id":165,"title":"How to Enhance the Performance of Your RAG Pipeline","sub_title":null,"featured":null,"abstract":"This article summarizes various popular approaches to enhancing the performance of your RAG applications. We also provided clear illustrations to help you quickly understand these concepts and techniques and expedite their implementation and optimization. \n","display_time":"2024-04-14","url":"how-to-enhance-the-performance-of-your-rag-pipeline","home_order":null,"published_at":"2024-04-15T17:27:35.563Z","created_by":82,"updated_by":60,"created_at":"2024-04-15T17:24:43.987Z","updated_at":"2025-05-01T00:00:24.644Z","show_in_learn":true,"order_in_learn":null,"category_order":null,"category_learn":null,"author":null,"canonical_rel":null,"repost_to_medium":false,"repost_state":null,"meta_title":"How to Enhance the Performance of Your RAG Pipeline","meta_description":"This article summarizes various popular approaches to enhancing the performance of your RAG applications. We also provided clear illustrations to help you quickly understand these concepts and techniques and expedite their implementation and optimization. \n","meta_keywords":null,"invisible":null,"locale":"en","repost_to_devto":null,"belong":"learn","read_time":8,"seriesName":"Retrieval Augmented Generation (RAG) 101"},{"id":134,"title":"Enhancing ChatGPT with Milvus: Powering AI with Long-Term Memory","sub_title":null,"featured":null,"abstract":"By integrating GPTCache and Milvus with ChatGPT, businesses can create a more robust and efficient AI-powered support system. This approach leverages the advanced capabilities of generative AI and introduces a form of long-term memory, allowing the AI to recall and reuse information effectively.","display_time":"2024-04-08","url":"enhancing-chatgpt-with-milvus","home_order":null,"published_at":"2024-04-15T17:34:32.668Z","created_by":82,"updated_by":21,"created_at":"2024-04-04T17:45:13.388Z","updated_at":"2025-07-01T00:00:27.924Z","show_in_learn":true,"order_in_learn":null,"category_order":null,"category_learn":null,"author":135,"canonical_rel":"","repost_to_medium":true,"repost_state":{"status":"success","mediumId":"9d3810961c3b","mediumUrl":"https://medium.com/@zilliz_learn/enhancing-chatgpt-with-milvus-powering-ai-with-long-term-memory-9d3810961c3b"},"meta_title":"Enhancing ChatGPT with Milvus: Powering AI with Long-Term Memory","meta_description":"By integrating GPTCache and Milvus with ChatGPT, businesses can create a more robust and efficient AI-powered support system. This approach leverages the advanced capabilities of generative AI and introduces a form of long-term memory, allowing the AI to recall and reuse information effectively.","meta_keywords":null,"invisible":null,"locale":"en","repost_to_devto":null,"belong":"learn","read_time":5,"seriesName":"Retrieval Augmented Generation (RAG) 101"},{"id":175,"title":"Pandas DataFrame: Chunking and Vectorizing with Milvus","sub_title":null,"featured":null,"abstract":"If we store all of the data, including the chunk text and the embedding, inside of Pandas DataFrame, we can easily integrate and import them into the Milvus vector database.","display_time":"2024-04-25","url":"pandas-dataframe-chunking-anf-vectorizing-with-milvus","home_order":null,"published_at":"2024-04-25T18:51:46.978Z","created_by":82,"updated_by":53,"created_at":"2024-04-25T18:51:20.100Z","updated_at":"2024-09-16T22:32:47.165Z","show_in_learn":true,"order_in_learn":null,"category_order":null,"category_learn":null,"author":null,"canonical_rel":"","repost_to_medium":true,"repost_state":{"status":"success","mediumId":"90e72b9baea5","mediumUrl":"https://medium.com/@zilliz_learn/pandas-dataframe-chunking-and-vectorizing-with-milvus-90e72b9baea5"},"meta_title":"Pandas DataFrame: Chunking and Vectorizing with Milvus","meta_description":"If we store all of the data, including the chunk text and the embedding, inside of Pandas DataFrame, we can easily integrate and import them into the Milvus vector database.","meta_keywords":null,"invisible":null,"locale":"en","repost_to_devto":null,"belong":"learn","read_time":16,"seriesName":"Retrieval Augmented Generation (RAG) 101"},{"id":177,"title":"How to build a Retrieval-Augmented Generation (RAG) system using Llama3, Ollama, DSPy, and Milvus","sub_title":null,"featured":null,"abstract":"In this article, we aim to guide readers through constructing an RAG system using four key technologies: Llama3, Ollama, DSPy, and Milvus. First, let’s understand what they are. ","display_time":"2024-04-22","url":"how-to-build-rag-system-using-llama3-ollama-dspy-milvus","home_order":null,"published_at":"2024-04-28T11:37:21.337Z","created_by":82,"updated_by":60,"created_at":"2024-04-26T22:08:37.591Z","updated_at":"2024-07-19T07:05:45.146Z","show_in_learn":true,"order_in_learn":null,"category_order":null,"category_learn":null,"author":null,"canonical_rel":"https://zilliz.com/learn/how-to-build-rag-system-using-llama3-ollama-dspy-milvus","repost_to_medium":true,"repost_state":{"status":"success","mediumId":"3ec1c4650e09","mediumUrl":"https://medium.com/@zilliz_learn/how-to-build-a-retrieval-augmented-generation-rag-system-using-llama3-ollama-dspy-and-milvus-3ec1c4650e09"},"meta_title":"Building RAG with Llama3, Ollama, DSPy, and Milvus","meta_description":"In this article, we aim to guide readers through constructing an RAG system using four key technologies: Llama3, Ollama, DSPy, and Milvus. First, let’s understand what they are. ","meta_keywords":null,"invisible":null,"locale":"en","repost_to_devto":null,"belong":"learn","read_time":5,"seriesName":"Retrieval Augmented Generation (RAG) 101"},{"id":192,"title":"A Guide to Chunking Strategies for Retrieval Augmented Generation (RAG)","sub_title":null,"featured":null,"abstract":"We explored various facets of chunking strategies within Retrieval-Augmented Generation (RAG) systems in this guide. ","display_time":"2024-05-15","url":"guide-to-chunking-strategies-for-rag","home_order":null,"published_at":"2024-05-15T07:13:43.841Z","created_by":82,"updated_by":60,"created_at":"2024-05-07T00:21:53.656Z","updated_at":"2025-03-12T05:33:50.590Z","show_in_learn":true,"order_in_learn":null,"category_order":null,"category_learn":null,"author":null,"canonical_rel":"https://zilliz.com/learn/guide-to-chunking-strategies-for-rag","repost_to_medium":true,"repost_state":{"status":"success","mediumId":"09c5a2b68ef2","mediumUrl":"https://medium.com/@zilliz_learn/a-guide-to-chunking-strategies-for-retrieval-augmented-generation-rag-09c5a2b68ef2"},"meta_title":"A Guide to Chunking Strategies for Retrieval Augmented Generation (RAG)","meta_description":"We explored various facets of chunking strategies within Retrieval-Augmented Generation (RAG) systems in this guide. ","meta_keywords":null,"invisible":null,"locale":"en","repost_to_devto":null,"belong":"learn","read_time":16,"seriesName":"Retrieval Augmented Generation (RAG) 101"},{"id":233,"title":"Improving Information Retrieval and RAG with Hypothetical Document Embeddings (HyDE)","sub_title":null,"featured":null,"abstract":"HyDE (Hypothetical Document Embeddings) is a retrieval method that uses \"fake\" documents to improve the answers of LLM and RAG. ","display_time":"2024-07-25","url":"improve-rag-and-information-retrieval-with-hyde-hypothetical-document-embeddings","home_order":null,"published_at":"2024-07-26T06:40:46.143Z","created_by":60,"updated_by":60,"created_at":"2024-07-26T06:34:25.358Z","updated_at":"2024-09-12T09:21:35.264Z","show_in_learn":true,"order_in_learn":null,"category_order":null,"category_learn":null,"author":null,"canonical_rel":"https://zilliz.com/learn/improve-rag-and-information-retrieval-with-hyde-hypothetical-document-embeddings","repost_to_medium":true,"repost_state":{"status":"success","mediumId":"db39021d7688","mediumUrl":"https://medium.com/@zilliz_learn/improving-information-retrieval-and-rag-with-hypothetical-document-embeddings-hyde-db39021d7688"},"meta_title":"Better RAG with HyDE - Hypothetical Document Embeddings","meta_description":"HyDE (Hypothetical Document Embeddings) is a retrieval method that uses \"fake\" documents to improve the answers of LLM and RAG. ","meta_keywords":"RAG, information retrieval, HyDE, vector databases, Vector Search, Hypothetical Document Embeddings","invisible":null,"locale":"en","repost_to_devto":null,"belong":"learn","read_time":9,"seriesName":"Retrieval Augmented Generation (RAG) 101"},{"id":237,"title":"Building RAG with Milvus Lite, Llama3, and LlamaIndex","sub_title":null,"featured":null,"abstract":"Retrieval Augmented Generation (RAG) is a method for mitigating LLM hallucinations. Learn how to build a chatbot RAG with Milvus, Llama3, and LlamaIndex. ","display_time":"2024-07-29","url":"build-rag-with-milvus-lite-llama3-and-llamaindex","home_order":null,"published_at":"2024-07-30T14:48:17.267Z","created_by":60,"updated_by":60,"created_at":"2024-07-30T14:42:05.149Z","updated_at":"2024-08-06T03:04:27.033Z","show_in_learn":true,"order_in_learn":null,"category_order":null,"category_learn":null,"author":null,"canonical_rel":"https://zilliz.com/learn/build-rag-with-milvus-lite-llama3-and-llamaindex","repost_to_medium":true,"repost_state":{"status":"success","mediumId":"88265cccf06c","mediumUrl":"https://medium.com/@zilliz_learn/building-rag-with-milvus-lite-llama3-and-llamaindex-88265cccf06c"},"meta_title":"How to Build Retrieval Augmented Generation (RAG) with Milvus Lite, Llama3 and LlamaIndex ","meta_description":"Retrieval Augmented Generation (RAG) is a method for mitigating LLM hallucinations. Learn how to build a chatbot RAG with Milvus, Llama3, and LlamaIndex. ","meta_keywords":"Milvus, Vector Database, RAG, Retrieval Augmented Generation","invisible":null,"locale":"en","repost_to_devto":null,"belong":"learn","read_time":13,"seriesName":"Retrieval Augmented Generation (RAG) 101"},{"id":283,"title":"Enhancing RAG with RA-DIT: A Fine-Tuning Approach to Minimize LLM Hallucinations","sub_title":null,"featured":null,"abstract":"RA-DIT, or Retrieval-Augmented Dual Instruction Tuning, is a method for fine-tuning both the LLM and the retriever in a RAG setup to enhance overall response quality.","display_time":"2024-12-23","url":"enhance-rag-with-radit-fine-tune-approach-to-minimize-llm-hallucinations","home_order":null,"published_at":"2025-01-04T15:30:05.674Z","created_by":60,"updated_by":125,"created_at":"2025-01-04T15:30:02.249Z","updated_at":"2025-03-26T10:46:51.948Z","show_in_learn":true,"order_in_learn":null,"category_order":null,"category_learn":null,"author":null,"canonical_rel":"https://zilliz.com/learn/enhance-rag-with-radit-fine-tune-approach-to-minimize-llm-hallucinations","repost_to_medium":true,"repost_state":{"medium":{"id":"7c6bfbd23538","url":"https://medium.com/@zilliz_learn/enhancing-rag-with-ra-dit-a-fine-tuning-approach-to-minimize-llm-hallucinations-7c6bfbd23538","status":"success"}},"meta_title":"Enhancing RAG with RA-DIT: Retrieval-Augmented Dual Instruction Tuning","meta_description":"RA-DIT, or Retrieval-Augmented Dual Instruction Tuning, is a method for fine-tuning both the LLM and the retriever in a RAG setup to enhance overall response quality.","meta_keywords":"Retrieval-Augmented Dual Instruction Tuning, RA-DIT, LLM hallucinations, RAG, retrieval augmented generation ","invisible":false,"locale":"en","repost_to_devto":null,"belong":"learn","read_time":9,"seriesName":"Retrieval Augmented Generation (RAG) 101"},{"id":486,"title":"Building RAG with Dify and Milvus","sub_title":null,"featured":null,"abstract":"Learn how to build Retrieval Augmented Generation (RAG) applications using Dify for orchestration and Milvus for vector storage in this step-by-step guide.","display_time":"2025-02-05","url":"building-rag-with-dify-and-milvus","home_order":null,"published_at":"2025-02-06T23:53:44.102Z","created_by":82,"updated_by":60,"created_at":"2025-02-06T23:46:29.976Z","updated_at":"2025-04-30T14:31:15.937Z","show_in_learn":true,"order_in_learn":null,"category_order":null,"category_learn":null,"author":null,"canonical_rel":"https://zilliz.com/learn/building-rag-with-dify-and-milvus","repost_to_medium":true,"repost_state":{"devto":{"id":2263384,"url":"https://dev.to/zilliz/building-rag-with-dify-and-milvus-9p3","status":"success"},"medium":{"id":"9f9b203c9cce","url":"https://medium.com/@zilliz_learn/building-rag-with-dify-and-milvus-9f9b203c9cce","status":"success"}},"meta_title":"How to Build RAG Applications with Dify and Milvus","meta_description":"Learn how to build Retrieval Augmented Generation (RAG) applications using Dify for orchestration and Milvus for vector storage in this step-by-step guide.","meta_keywords":"RAG applications, Dify, Milvus, vector database, LLM integration","invisible":false,"locale":"en","repost_to_devto":true,"belong":"learn","read_time":11,"seriesName":"Retrieval Augmented Generation (RAG) 101"},{"id":505,"title":"Top 10 RAG \u0026 LLM Evaluation Tools You Don't Want To Miss","sub_title":null,"featured":null,"abstract":"Discover the best RAG evaluation tools to improve AI app reliability, prevent hallucinations, and boost performance across different frameworks.\n","display_time":"2025-03-05","url":"top-ten-rag-and-llm-evaluation-tools-you-dont-want-to-miss","home_order":null,"published_at":"2025-03-26T00:10:23.093Z","created_by":82,"updated_by":125,"created_at":"2025-03-26T00:10:20.639Z","updated_at":"2025-04-07T03:41:27.773Z","show_in_learn":true,"order_in_learn":null,"category_order":null,"category_learn":null,"author":null,"canonical_rel":"https://zilliz.com/learn/top-ten-rag-and-llm-evaluation-tools-you-dont-want-to-miss","repost_to_medium":true,"repost_state":{"devto":{"status":"success"},"medium":{"status":"success","id":"a0bfabe9ae19","url":"https://medium.com/@zilliz_learn/top-10-rag-llm-evaluation-tools-you-dont-want-to-miss-a0bfabe9ae19"}},"meta_title":"Top 10 RAG \u0026 LLM Evaluation Tools for AI Success","meta_description":"Discover the best RAG evaluation tools to improve AI app reliability, prevent hallucinations, and boost performance across different frameworks.\n","meta_keywords":"RAG Evaluation, LLMs, Machine Learning, Generative AI, AI Performance","invisible":false,"locale":"en","repost_to_devto":true,"belong":"learn","read_time":9,"seriesName":"Retrieval Augmented Generation (RAG) 101"}],"canonicalUrl":null,"CONTENT_TYPE":"knowledge-article","recommendedArticles":[{"id":"learn-121","content":"Retrieval-augmented generation ([RAG](https://zilliz.com/learn/Retrieval-Augmented-Generation)) is a rising AI stack that enhances the capabilities of large language models ([LLMs](https://zilliz.com/glossary/large-language-models-\\(llms\\))) by supplying them with additional, up-to-date knowledge. A standard [RAG application](https://zilliz.com/blog/best-practice-in-implementing-rag-apps) consists of four key technology components:\n\n* [Embedding models](https://zilliz.com/blog/choosing-the-right-embedding-model-for-your-data) for converting external documents and user queries into [vector embeddings](https://zilliz.com/glossary/vector-embeddings),\n\n* A [vector database](https://zilliz.com/learn/what-is-vector-database) for storing these embeddings and retrieving the Top-K most relevant information,\n\n* [Prompts-as-code](https://zilliz.com/glossary/prompt-as-code-\\(prompt-engineering\\)) that combines both the user query and the retrieved context,\n\n* An LLM for generating answers.\n\nSome vector databases like Zilliz Cloud provide built-in embedding pipelines that automatically transform documents and user queries into embeddings, streamlining the RAG architecture.\n\nA basic RAG setup effectively addresses the issue of LLMs producing unreliable or [‘hallucinated’](https://zilliz.com/glossary/ai-hallucination) content by grounding the model’s responses in domain-specific or proprietary contexts. However, some enterprise users require higher context relevancy in their production use cases and seek a more sophisticated RAG setup. One increasingly popular solution is integrating a reranker into the RAG system. This is where '[rag pipelines](https://zilliz.com/learn/how-to-enhance-the-performance-of-your-rag-pipeline)' come into play, enhancing RAG systems through reranking techniques to ensure the most relevant information is delivered to large language models.\n\nA reranker is a crucial component in the [information retrieval](https://zilliz.com/learn/what-is-information-retrieval) (IR) ecosystem that evaluates and reorders search results or passages to enhance their relevance to a specific query. In RAG, this tool builds on the primary vector [Approximate Nearest Neighbor](https://zilliz.com/learn/approximate-nearest-neighbor-oh-yeah-ANNOY) ([ANN](https://zilliz.com/glossary/anns)) search, improving search quality by more effectively determining the [semantic](https://zilliz.com/glossary/semantic-search) relevance between documents and queries.\n\nRerankers fall into two main categories: **Score-based and Neural Network-based**. \n\n**Score-based rerankers** work by aggregating multiple candidate lists from various sources, applying weighted scoring or Reciprocal Rank Fusion (RRF) to unify and reorder these candidates into a single, prioritized list based on their score or relative position in the original list. This type of reranker is known for its efficiency and is widely used in traditional search systems due to its lightweight nature.\n\nOn the other hand, **Neural Network-based reranker**s, often called cross-encoder rerankers, leverage a neural network to analyze the relevance between a query and a document. They are specifically designed to compute a similarity score that reflects the semantic proximity between the two, allowing for a refined rearrangement of results from single or multiple sources. This method ensures more semantic relatedness, thus providing useful search results and enhancing the overall effectiveness of the retrieval system.\n\nIncorporating a reranker into your RAG applications can significantly improve the precision of the generated answers as the reranker narrows the context to a smaller, curated set of highly relevant documents. As the context is shorter, it is also easier for LLM to “attend” to everything in the context and avoid losing focus.\n\n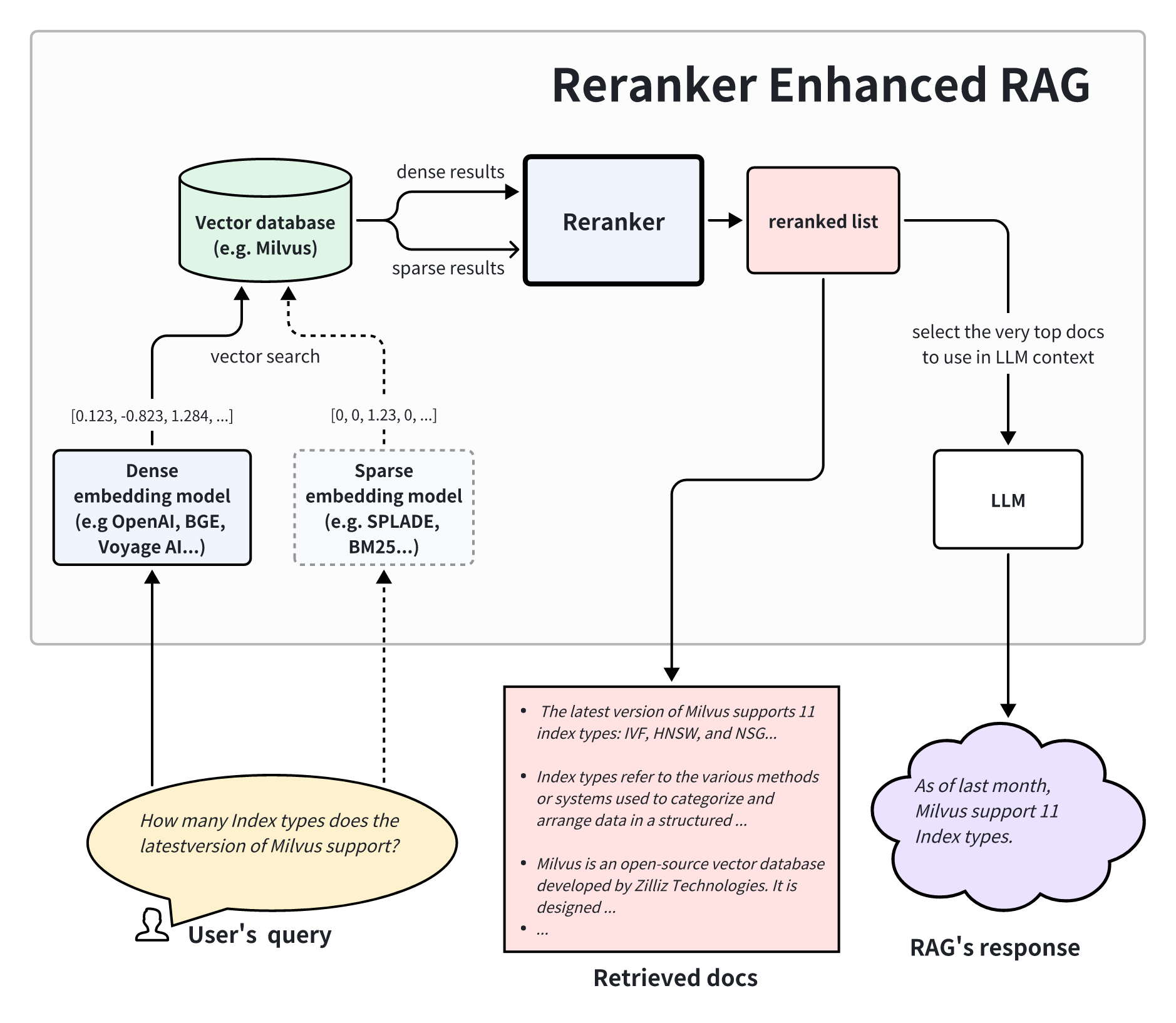\n\n\nThe architecture above shows that a reranker-enhanced RAG contains a two-stage retrieval system. In the first stage, a vector database retrieves a set of relevant documents from a larger dataset. Then, in the second stage, a reranker analyzes and prioritizes these documents based on their relevance to the query. Finally, the reranked results are sent to the LLM as a more relevant context for generating better-quality answers.\n\nNevertheless, integrating a reranker into the RAG framework comes with its challenges and expenses. Deciding whether to add a reranker requires thoroughly analyzing your business needs and balancing the improved retrieval quality against potential latency and computational cost increases.\n\nRerankers can enhance the relevance of retrieved information in a RAG system, but this approach comes at a price. \n\nIn a basic RAG system without a reranker, vector representations for a document are pre-processed and stored before the user conducts a query. As a result, the system only needs to perform a relatively inexpensive Approximate Nearest Neighbor (ANN) vector search to identify the Top-K documents based on metrics like [cosine similarity](https://zilliz.com/blog/similarity-metrics-for-vector-search). A vector search only takes [milliseconds](https://zilliz.com/vector-database-benchmark-tool?database=ZillizCloud%2CMilvus%2CPgVector%2CElasticCloud%2CPinecone%2CQdrantCloud%2CWeaviateCloud\\\u0026dataset=medium\\\u0026filter=none%2Clow%2Chigh) in a production-grade vector database like Zilliz Cloud.\n\nIn contrast, a reranker, particularly a cross-encoder, must process the query and each candidate document through a deep neural network. Depending on the model's size and hardware specifications, this process can take significantly longer — from hundreds of milliseconds to seconds. A reranker-enhanced RAG would take that much time before even generating the first token. \n\nWhile offline indexing in a basic RAG workflow incurs the computational cost of neural network processing once per document, reranking requires expending similar resources for every query against each potential document in the result set. This repetitive computational expense can become prohibitive in high-traffic IR settings like web and e-commerce search platforms.\n\nLet's do some simple math to understand how costly a reranker is.\n\nAccording to [statistics](https://zilliz.com/vector-database-benchmark-tool) from [VectorDBBench](https://zilliz.com/learn/open-source-vector-database-benchmarking-your-way), a vector database handling over 200 queries per second (QPS) incurs only a \\$100 monthly fee, which breaks down to \\$0.0000002 per query. In contrast, it can cost as much as \\$0.001 per query if using a reranker to reorder the top 100 results from the first-stage retrieved documents. That’s a 5,000x increase over the vector search cost alone. \n\nAlthough a vector database might not always operate at maximum query capacity, and the reranking could be limited to a smaller number of results (e.g., top 10), the expense of employing a cross-encoder reranker is still **orders of magnitude higher** than that of a vector-search-only retrieval approach. \n\nViewed from another angle, using a reranker equates to incurring the indexing cost during query time. The inference cost is tied to the input size (tokens) and the model size. Given that both embedding and reranker models typically range from hundreds of MB to several GB, let's assume they are comparable. With an average of 1,000 tokens per document and a negligible 10 tokens per query, reranking the top 10 documents alongside the queries would equate to 10x the computation cost of indexing a single document. This means serving 1 million queries against a corpus of 10 million documents would consume as much computational power as indexing the entire corpus, which is impractical in high-traffic use cases. \n\nWhile a reranker-enhanced RAG is more costly than a basic vector-search-based RAG, it is substantially more cost-effective than relying solely on LLMs to generate answers. Within a RAG framework, rerankers serve to sift through the preliminary results from vector search, discarding documents weakly relevant to the query. This process reduces time and costs by preventing LLMs from processing extraneous information.\n\n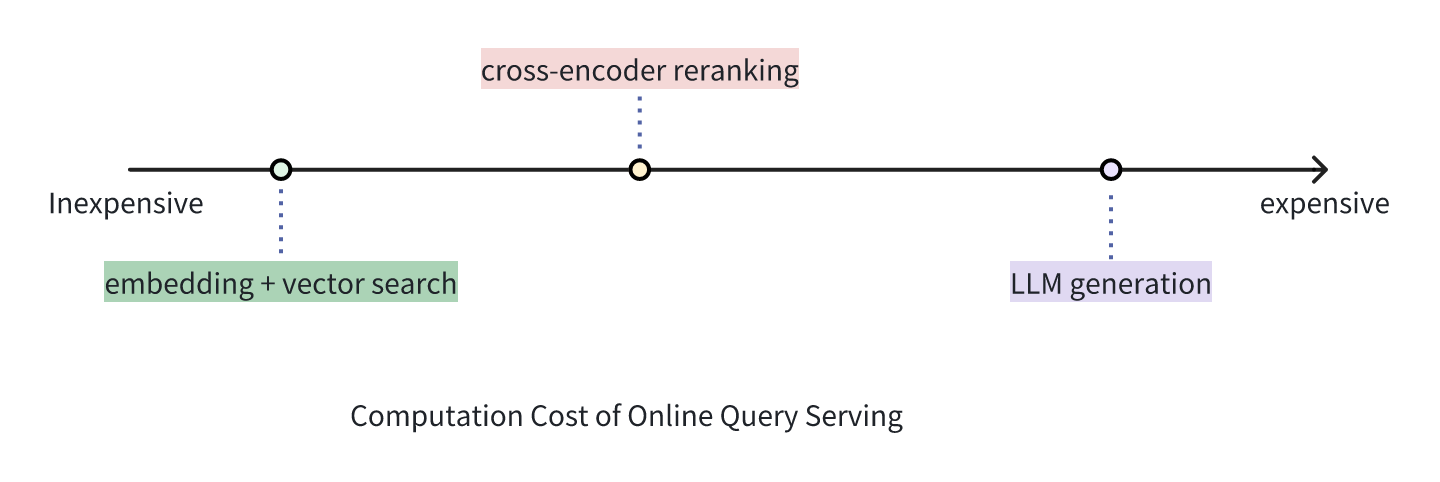\n\n\nTaking a real-world example: First-stage retrieval, such as vector search engines, quickly sift through millions of candidates to identify the top 20 most relevant documents. A reranker, though more costly, then recomputes the ordering and narrows the Top20 list down to 5. Ultimately, the most expensive large language models (LLMs) analyze these top 5 documents along with the query to craft a comprehensive and high-quality response, balancing latency and cost.\n\nThus, the reranker serves as a crucial intermediary between the efficient but approximate initial retrieval stage and the high-cost LLM inference phase.\n\nIncorporating a reranker into your Retrieval-Augmented Generation (RAG) setup is beneficial when high accuracy and relevance of answers are crucial, such as in specialized knowledge bases or customer service systems. In these settings, each query comes with high business value, and the enhanced precision in filtering information justifies the added cost and latency of reranking. The reranker refines the initial vector search results, providing a more relevant context for the Large Language Model (LLM) to generate accurate responses, thereby improving the overall user experience.\n\nHowever, in high-traffic use cases like web or e-commerce search engines, where rapid response and cost efficiency are paramount, there may be better options than using a cross-encoder reranker. The increased computational demand and slower response times can negatively affect user experience and operational costs. In such cases, a basic RAG approach, relying on efficient vector search alone or with a lightweight score-based reranker, is preferred to balance speed and expense while maintaining acceptable levels of accuracy and relevance.\n\nIf you decide to apply a reranker to your RAG application, you can easily [enable](https://docs.zilliz.com/docs/reranker#when-to-use-reranker) it within Zilliz Cloud Pipelines or use [reranker models](https://github.com/milvus-io/bootcamp/blob/master/bootcamp/model/) with Milvus.\n\nRerankers refine search results to improve the accuracy and relevance of answers in Retrieval-Augmented Generation (RAG) systems, proving valuable in scenarios where cost and latency can be flexible and precision is critical. However, their advantages are accompanied by trade-offs, including increased latency and computational costs, making them less suitable for high-traffic applications. Ultimately, the decision to integrate a reranker should be based on the specific needs of the RAG system, weighing the demand for high-quality responses against performance and cost constraints.\n\nIn my next blog post, I will delve into the intricacies of [hybrid search](https://zilliz.com/blog/hybrid-search-with-milvus) architecture, exploring various technologies, including [sparse embedding](https://zilliz.com/learn/sparse-and-dense-embeddings), [knowledge graphs](https://zilliz.com/learn/what-is-knowledge-graph), rule-based retrieval, and innovative academic concepts awaiting production deployments, like ColBERT and CEPE. Additionally, I will employ a qualitative analysis to assess the improvements in result quality and the impact on latency when implementing rerankers. A comparative review of prevalent reranker models in the market, such as [Cohere](https://zilliz.com/product/integrations/cohere)[BGE](https://huggingface.co/BAAI/bge-reranker-base#model-list), and [Voyage AI](https://zilliz.com/product/integrations/voyage-ai), will also be featured, providing insights into their performance and efficacy.\n\n## Introduction to Reranking in Retrieval-Augmented Generation (RAG)\n\n## The Role of Rerankers in RAG Systems\n\nRerankers play a vital role in RAG systems by enhancing the relevance and quality of generated responses. Selecting an appropriate reranking model is crucial for ensuring accuracy and efficiency in these systems. A reranker is a model that outputs a similarity score for a query and document pair, allowing for the reordering of documents by relevance to a query. Rerankers are used in two-stage retrieval systems to improve the accuracy and relevance of search results. By analyzing the document’s meaning specific to the user query, rerankers can provide more accurate and contextually relevant results than traditional retrieval methods.\n\n## The Importance of Relevant Documents in Reranking\n\nRelevant documents play a crucial role in the reranking process, as they directly impact the quality of the generated response. The goal of reranking is to reorder the retrieved documents based on their relevance to the user’s query, ensuring that the most pertinent information is presented to the Large Language Model (LLM) for generation. Relevant documents are those that contain the most accurate and contextually relevant information, which is essential for producing high-quality responses.\n\nThe importance of relevant documents in reranking can be seen in the following ways:\n\n* **Improved response quality**: By prioritizing relevant documents, reranking ensures that the LLM works with the most accurate and contextually relevant information, leading to improved response quality.\n\n* **Increased user satisfaction**: Relevant documents help to deliver more accurate and contextually relevant results, which boosts user satisfaction and engagement metrics.\n\n* **Enhanced [RAG pipeline](https://zilliz.com/event/rag-pipelines-with-real-time-data) performance**: Relevant documents are essential for optimizing RAG pipelines, as they enable the LLM to work with the most pertinent information, leading to improved performance.\n\n## Types of Rerankers\n\nReranking models are essential for enhancing search and retrieval processes, offering advantages over traditional retrieval methods by performing deep semantic matching and fine-grained relevance judgments. There are several types of rerankers, each with its strengths and weaknesses. Cross-Encoder rerankers process the query and document together through a [transformer architecture](https://zilliz.com/learn/decoding-transformer-models-a-study-of-their-architecture-and-underlying-principles), allowing for powerful cross-attention between query and document terms. Bi-Encoder rerankers use [BERT](https://zilliz.com/learn/what-is-bert) to encode the document, but with different approaches. Multi-Vector models represent documents as sets of contextualized [token embeddings](https://zilliz.com/learn/explore-colbert-token-level-embedding-and-ranking-model-for-similarity-search) rather than single vectors. LLM-Based rerankers leverage pre-trained language models to perform reranking tasks through [few-shot learning](https://zilliz.com/ai-faq/what-is-fewshot-learning) or fine-tuning. API-Based solutions offer reranking as a service through [API](https://zilliz.com/glossary/api) endpoints.\n\n## Choosing a Reranker: Considerations and Trade-offs\n\nWhen selecting a reranker, consider factors such as the type of data, the size of the corpus, and the computational resources available. Consider the trade-off between accuracy and efficiency when selecting a reranker. Cross-Encoders are highly accurate but computationally expensive, while Bi-Encoders are more efficient but may sacrifice some accuracy. Multi-Vector models offer a balance between accuracy and efficiency. LLM-Based rerankers are flexible but may require significant computational resources. API-Based solutions are easy to use but may come with significant costs.\n\n## Implementing a Reranker in an Existing Application\n\nImplementing a reranker in an existing application involves integrating the reranker with the existing pipeline. The reranker ranks the documents after the documents are retrieved by the document retriever and returns it back to the function call. The reranker can be integrated with the RAG pipeline to improve the quality of the generated response. Consider using techniques such as hyperparameter tuning and model selection to optimize your reranking setup. Additionally, consider using techniques such as document splitting or using a different reranker to handle long or multiple documents.\n\n## Performance of Rerankers\n\nThe performance of rerankers is critical in determining the quality of the generated response. Rerankers can significantly enhance the performance of RAG systems by ensuring that the most relevant documents are presented to the LLM for generation. The performance of rerankers can be evaluated using various metrics, including:\n\n* **Precision**: The proportion of relevant documents retrieved by the reranker.\n\n* **Recall**: The proportion of relevant documents that are retrieved by the reranker out of all relevant documents in the database.\n\n* **F1-score**: The harmonic mean of precision and recall, providing a balanced measure of the reranker’s performance.\n\n## Practical Implementation Strategies for Reranker-Enhanced RAG Systems\n\nWhen implementing reranker-enhanced RAG systems in production environments, assigning relevance scores to evaluate and reorder documents can significantly improve performance while managing computational costs.\n\n### Caching Mechanisms for Retrieved Documents Reranker Results\n\nOne effective approach to mitigate the computational burden of rerankers is implementing a robust caching system. By storing reranking results for common queries, organizations can dramatically reduce computational costs and latency for frequently asked questions. Caching strategies should consider time-based expiration policies to ensure information freshness. Organizations should also implement LRU (Least Recently Used) eviction policies to optimize memory usage and develop partial matching techniques to leverage cached results for similar queries. In high-volume applications, even a modest cache hit rate of 30-40% can translate to substantial cost savings while maintaining high-quality responses.\n\n### Adaptive Reranking Thresholds\n\nNot all queries require the same level of reranking precision. Implementing adaptive thresholds can optimize resource allocation. Use confidence scores from first-stage retrieval to determine when reranking is necessary. Apply more intensive reranking only when vector search results show low confidence or high ambiguity. Adjust the number of documents passed to the reranker based on query complexity and initial retrieval quality. This tiered approach ensures computational resources are allocated efficiently, with simple queries bypassing expensive reranking while complex queries receive the full benefit of deeper semantic analysis.\n\n### Optimizing Reranker Model Size\n\nThe size of reranker models significantly impacts both quality and performance. Consider distilled models that maintain most of the accuracy while reducing parameter count. Quantized models that use lower numerical precision without significant quality degradation are also worth exploring. Domain-specific fine-tuning can improve relevance for specialized knowledge areas. Many organizations find that medium-sized distilled models (100-300M parameters) offer an optimal balance between performance and quality for most enterprise applications.\n\n### Hybrid Reranking Architectures\n\nCombining multiple reranking approaches can yield superior results. Use vector similarity search for initial retrieval of candidate documents before applying score-based rerankers for initial filtering followed by more sophisticated cross-encoders. Implement ensemble methods that combine scores from multiple reranker types. Apply different reranking strategies based on document types or query categories. These hybrid approaches can deliver quality improvements while managing computational costs through strategic deployment of expensive components.\n\n## Handling Long Documents\n\nHandling long documents is a common challenge in reranking, as many rerankers have input length limitations. To address this challenge, several techniques can be employed, including:\n\n* **Document splitting**: Splitting long documents into smaller chunks, allowing the reranker to process each chunk separately.\n\n* **Using a different reranker**: Selecting a reranker that is specifically designed to handle long documents, such as a multi-vector model or an LLM-based reranker.\n\n## Offline Evaluation and Online A/B Testing\n\nEvaluating the performance of a reranking implementation is crucial to ensure that it is effective in improving the quality of the generated response. Offline evaluation and online A/B testing are two common methods used to evaluate the performance of a reranking implementation.\n\n* **Offline evaluation**: Evaluating the performance of the reranking implementation using standard [information retrieval metrics](https://zilliz.com/learn/information-retrieval-metrics) on labeled test sets.\n\n* **Online A/B testing**: Evaluating the impact of the reranking implementation on the end-to-end RAG system, comparing the performance of the system with and without the reranking implementation.\n\n## Error Analysis and Addressing Potential Biases\n\nError analysis and addressing potential biases are essential steps in ensuring that the reranking implementation is effective and fair. Error analysis involves identifying cases where the reranking implementation fails to surface relevant documents, while addressing potential biases involves identifying and mitigating biases in the reranking implementation.\n\n* **Error analysis**: Analyzing log data and error tracking to identify areas for improvement in the reranking implementation.\n\n* **Addressing potential biases**: Identifying and mitigating biases in the reranking implementation, such as biases in the training data or biases in the reranking algorithm.\n\n## Future Directions in RAG Reranking Technology\n\nThe field of reranking for RAG systems continues to evolve rapidly. Several promising developments are likely to shape the landscape in the coming years:\n\n### Context-Aware Reranking for User Queries\n\nNext-generation rerankers will move beyond simple query-document relevance to incorporate broader contextual understanding, ensuring that the retrieved information aligns closely with the user's query. Conversation history awareness will help maintain coherence across multi-turn interactions. User preference modeling will enable personalization of reranking based on individual information needs. Task-specific optimization will adapt reranking behavior based on the intended use case. These advances will enable more natural and helpful AI responses that account for the full interaction context rather than treating each query in isolation.\n\n### Multimodal Reranking Capabilities\n\nAs RAG systems expand to include multimodal content, rerankers will evolve to handle diverse data types. Cross-modal relevance assessment between text queries and image/video content will become increasingly important. Joint understanding of text, tables, and graphical elements within documents will enhance comprehension. Semantic alignment across modalities will enable more comprehensive information retrieval. Organizations working with rich media content will particularly benefit from these capabilities, enabling more comprehensive knowledge access across their information assets.\n\n\n\n\n","title":"Optimizing RAG with Rerankers: The Role and Trade-offs ","sub_title":null,"featured":true,"abstract":"Rerankers can enhance the accuracy and relevance of answers in RAG systems, but these benefits come with increased latency and computational costs.","display_time":"Apr 02, 2024","url":"optimize-rag-with-rerankers-the-role-and-tradeoffs","home_order":null,"published_at":"2024-04-01T18:34:05.783Z","created_by":{"id":60,"firstname":"Di","lastname":"Feng","username":null,"email":"fendy.feng@zilliz.com","password":"$2a$10$3n0EPwpsTTiNpylnqJ4MReO3yAuO3glfers.zS0Wo4pmwHzaFMbnm","resetPasswordToken":null,"registrationToken":null,"isActive":true,"blocked":null,"preferedLanguage":null},"updated_by":{"id":60,"firstname":"Di","lastname":"Feng","username":null,"email":"fendy.feng@zilliz.com","password":"$2a$10$3n0EPwpsTTiNpylnqJ4MReO3yAuO3glfers.zS0Wo4pmwHzaFMbnm","resetPasswordToken":null,"registrationToken":null,"isActive":true,"blocked":null,"preferedLanguage":null},"created_at":"2024-04-01T17:07:44.767Z","updated_at":"2025-03-12T05:34:15.325Z","show_in_learn":true,"order_in_learn":null,"category_order":null,"category_learn":null,"author":{"id":101,"name":"Jiang Chen","author_tags":"Head of Ecosystem and Developer Relations","published_at":"2023-10-16T07:05:20.176Z","created_by":18,"updated_by":82,"created_at":"2023-10-16T07:05:18.702Z","updated_at":"2024-09-10T17:33:55.053Z","home_page":"LinkedIn","home_page_link":"https://www.linkedin.com/in/jiang-0616/","self_intro":"Jiang is currently Head of Ecosystem and Developer Relations at Zilliz. He has years of experience in data infrastructures and cloud security. Before joining Zilliz, he had previously served as a tech lead and product manager at Google, where he led the development of web-scale semantic understanding and search indexing that powers innovative search products such as short video search. He has extensive industry experience handling massive unstructured data and multimedia content retrieval. He has also worked on cloud authorization systems and research on data privacy technologies. Jiang holds a Master's degree in Computer Science from the University of Michigan.","repost_to_medium":null,"repost_state":null,"meta_description":null,"locale":"en","avatar":{"id":2018,"name":"jiang chen.jpeg","alternativeText":"","caption":"","width":2658,"height":2658,"formats":{"large":{"ext":".jpeg","url":"https://assets.zilliz.com/large_jiang_chen_15b00222e2.jpeg","hash":"large_jiang_chen_15b00222e2","mime":"image/jpeg","name":"large_jiang chen.jpeg","path":null,"size":153.34,"width":1000,"height":1000},"small":{"ext":".jpeg","url":"https://assets.zilliz.com/small_jiang_chen_15b00222e2.jpeg","hash":"small_jiang_chen_15b00222e2","mime":"image/jpeg","name":"small_jiang chen.jpeg","path":null,"size":49.5,"width":500,"height":500},"medium":{"ext":".jpeg","url":"https://assets.zilliz.com/medium_jiang_chen_15b00222e2.jpeg","hash":"medium_jiang_chen_15b00222e2","mime":"image/jpeg","name":"medium_jiang chen.jpeg","path":null,"size":95.49,"width":750,"height":750},"thumbnail":{"ext":".jpeg","url":"https://assets.zilliz.com/thumbnail_jiang_chen_15b00222e2.jpeg","hash":"thumbnail_jiang_chen_15b00222e2","mime":"image/jpeg","name":"thumbnail_jiang chen.jpeg","path":null,"size":7.82,"width":156,"height":156}},"hash":"jiang_chen_15b00222e2","ext":".jpeg","mime":"image/jpeg","size":862.49,"url":"https://assets.zilliz.com/jiang_chen_15b00222e2.jpeg","previewUrl":null,"provider":"s3","provider_metadata":null,"created_by":60,"updated_by":60,"created_at":"2023-10-16T07:04:06.938Z","updated_at":"2023-10-16T07:04:06.951Z"}},"canonical_rel":"https://zilliz.com/learn/optimize-rag-with-rerankers-the-role-and-tradeoffs","repost_to_medium":true,"repost_state":{"status":"success","mediumId":"250bf4b3e09e","mediumUrl":"https://medium.com/@zilliz_learn/optimizing-rag-with-rerankers-the-role-and-trade-offs-250bf4b3e09e"},"meta_title":"Optimizing RAG with Rerankers: The Role and Trade-offs ","meta_description":"Rerankers can enhance the accuracy and relevance of answers in RAG systems, but these benefits come with increased latency and computational costs.","meta_keywords":null,"invisible":false,"locale":"en","repost_to_devto":null,"image":{"id":3001,"name":"Optimizing RAG with Rerankers The Role and Trade-offs .png","alternativeText":"","caption":"","width":2400,"height":1256,"formats":{"large":{"ext":".png","url":"https://assets.zilliz.com/large_Optimizing_RAG_with_Rerankers_The_Role_and_Trade_offs_2a9a90f6af.png","hash":"large_Optimizing_RAG_with_Rerankers_The_Role_and_Trade_offs_2a9a90f6af","mime":"image/png","name":"large_Optimizing RAG with Rerankers The Role and Trade-offs .png","path":null,"size":499.04,"width":1000,"height":523},"small":{"ext":".png","url":"https://assets.zilliz.com/small_Optimizing_RAG_with_Rerankers_The_Role_and_Trade_offs_2a9a90f6af.png","hash":"small_Optimizing_RAG_with_Rerankers_The_Role_and_Trade_offs_2a9a90f6af","mime":"image/png","name":"small_Optimizing RAG with Rerankers The Role and Trade-offs .png","path":null,"size":137.82,"width":500,"height":262},"medium":{"ext":".png","url":"https://assets.zilliz.com/medium_Optimizing_RAG_with_Rerankers_The_Role_and_Trade_offs_2a9a90f6af.png","hash":"medium_Optimizing_RAG_with_Rerankers_The_Role_and_Trade_offs_2a9a90f6af","mime":"image/png","name":"medium_Optimizing RAG with Rerankers The Role and Trade-offs .png","path":null,"size":280.49,"width":750,"height":393},"thumbnail":{"ext":".png","url":"https://assets.zilliz.com/thumbnail_Optimizing_RAG_with_Rerankers_The_Role_and_Trade_offs_2a9a90f6af.png","hash":"thumbnail_Optimizing_RAG_with_Rerankers_The_Role_and_Trade_offs_2a9a90f6af","mime":"image/png","name":"thumbnail_Optimizing RAG with Rerankers The Role and Trade-offs .png","path":null,"size":48.54,"width":245,"height":128}},"hash":"Optimizing_RAG_with_Rerankers_The_Role_and_Trade_offs_2a9a90f6af","ext":".png","mime":"image/png","size":2377.64,"url":"https://assets.zilliz.com/Optimizing_RAG_with_Rerankers_The_Role_and_Trade_offs_2a9a90f6af.png","previewUrl":null,"provider":"s3","provider_metadata":null,"created_by":60,"updated_by":60,"created_at":"2024-04-01T17:07:28.273Z","updated_at":"2024-04-01T17:07:28.283Z"},"tags":[{"id":5,"name":"Engineering","published_at":"2021-01-21T02:28:39.896Z","created_by":18,"updated_by":18,"created_at":"2021-01-21T02:28:37.242Z","updated_at":"2022-11-15T19:16:38.988Z","locale":"en"}],"authors":[{"id":101,"name":"Jiang Chen","author_tags":"Head of Ecosystem and Developer Relations","published_at":"2023-10-16T07:05:20.176Z","created_by":18,"updated_by":82,"created_at":"2023-10-16T07:05:18.702Z","updated_at":"2024-09-10T17:33:55.053Z","home_page":"LinkedIn","home_page_link":"https://www.linkedin.com/in/jiang-0616/","self_intro":"Jiang is currently Head of Ecosystem and Developer Relations at Zilliz. He has years of experience in data infrastructures and cloud security. Before joining Zilliz, he had previously served as a tech lead and product manager at Google, where he led the development of web-scale semantic understanding and search indexing that powers innovative search products such as short video search. He has extensive industry experience handling massive unstructured data and multimedia content retrieval. He has also worked on cloud authorization systems and research on data privacy technologies. Jiang holds a Master's degree in Computer Science from the University of Michigan.","repost_to_medium":null,"repost_state":null,"meta_description":null,"locale":"en","avatar":{"id":2018,"name":"jiang chen.jpeg","alternativeText":"","caption":"","width":2658,"height":2658,"formats":{"large":{"ext":".jpeg","url":"https://assets.zilliz.com/large_jiang_chen_15b00222e2.jpeg","hash":"large_jiang_chen_15b00222e2","mime":"image/jpeg","name":"large_jiang chen.jpeg","path":null,"size":153.34,"width":1000,"height":1000},"small":{"ext":".jpeg","url":"https://assets.zilliz.com/small_jiang_chen_15b00222e2.jpeg","hash":"small_jiang_chen_15b00222e2","mime":"image/jpeg","name":"small_jiang chen.jpeg","path":null,"size":49.5,"width":500,"height":500},"medium":{"ext":".jpeg","url":"https://assets.zilliz.com/medium_jiang_chen_15b00222e2.jpeg","hash":"medium_jiang_chen_15b00222e2","mime":"image/jpeg","name":"medium_jiang chen.jpeg","path":null,"size":95.49,"width":750,"height":750},"thumbnail":{"ext":".jpeg","url":"https://assets.zilliz.com/thumbnail_jiang_chen_15b00222e2.jpeg","hash":"thumbnail_jiang_chen_15b00222e2","mime":"image/jpeg","name":"thumbnail_jiang chen.jpeg","path":null,"size":7.82,"width":156,"height":156}},"hash":"jiang_chen_15b00222e2","ext":".jpeg","mime":"image/jpeg","size":862.49,"url":"https://assets.zilliz.com/jiang_chen_15b00222e2.jpeg","previewUrl":null,"provider":"s3","provider_metadata":null,"created_by":60,"updated_by":60,"created_at":"2023-10-16T07:04:06.938Z","updated_at":"2023-10-16T07:04:06.951Z"}}],"localizations":[{"id":359,"locale":"ja-JP","published_at":"2024-04-01T18:34:05.783Z"}],"read_time":13,"display_updated_time":"Mar 12, 2025","backgroundImage":"https://assets.zilliz.com/large_Optimizing_RAG_with_Rerankers_The_Role_and_Trade_offs_2a9a90f6af.png","belong":"learn","authorNames":["Jiang Chen"]},{"id":"learn-134","content":"Imagine managing an online support service where users frequently report and ask questions about issues with your product. To ensure round-the-clock assistance, you've built your support service using a RAG framework with Milvus and the Open AI large language model ([LLM](https://zilliz.com/glossary/large-language-models-\\(llms\\))) to handle inquiries. As the system operates, you notice many user difficulties are similar. This realization sparks an idea—what if you could leverage past responses to address new queries swiftly? Not only would this approach decrease the number of tokens you consume per API call to the LLM, thus lowering costs, but it would also significantly enhance response times, improving user experience with your support service.\n\nThat is where GPTCache comes in. [GPTCache](https://zilliz.com/what-is-gptcache) is an open-source library designed by the engineers at [Zilliz](https://github.com/zilliztech/GPTCache) to create a [semantic cache](https://zilliz.com/glossary/semantic-cache) for LLM queries. This blog will explore how integrating GPTCache with [ChatGPT ](https://openai.com/blog/chatgpt)and [Milvus](https://milvus.io/) can transform your LLM use case by utilizing cached responses to improve efficiency. We will see how implementing a system that recalls previous interactions provides a form of long-term memory to the LLM, enabling it to handle interactions more effectively and remember relevant information without the need for repeated LLM API calls. This capability enhances user experience and reduces the load on backend servers, improving the capabilities of generative AI models.\n\n\n## Overview of ChatGPT Plugins\n\nSpeaking of generative AI model capabilities, [ChatGPT plugins](https://openai.com/blog/chatgpt-plugins) are extensions designed to augment the base capabilities of the ChatGPT model and are tailored to specific needs or functionalities. These plugins allow for integration with external services, enhance performance, or introduce new features not inherently present in the primary model. For example, a plugin could be developed to interface with a customer relationship management (CRM) system, providing the AI with access to customer data that can enhance personalized interactions, as illustrated in Figure 1.\n\n\n\n\n## Let see the difference GPTCache brings\n\nThere has been an explosion of GPT-based apps. This has come with challenges such as increased service cost, as the [OSS Chat](https://osschat.io/) app builders will tell you, motivating the building of a [caching mechanism for GPT](https://zilliz.com/blog/Caching-LLM-Queries-for-performance-improvements). GPTCache allows users to customize the cache according to their needs, including options for embedding functions, similarity evaluation functions, storage location, and eviction policy, as we illustrated in Figure 2 and demonstrated on [the colab notebook](https://colab.research.google.com/drive/1ezwvCPgo5uprVCVeO1U02gztJh74iu5M#scrollTo=j5UswHpYgmYT).\n\n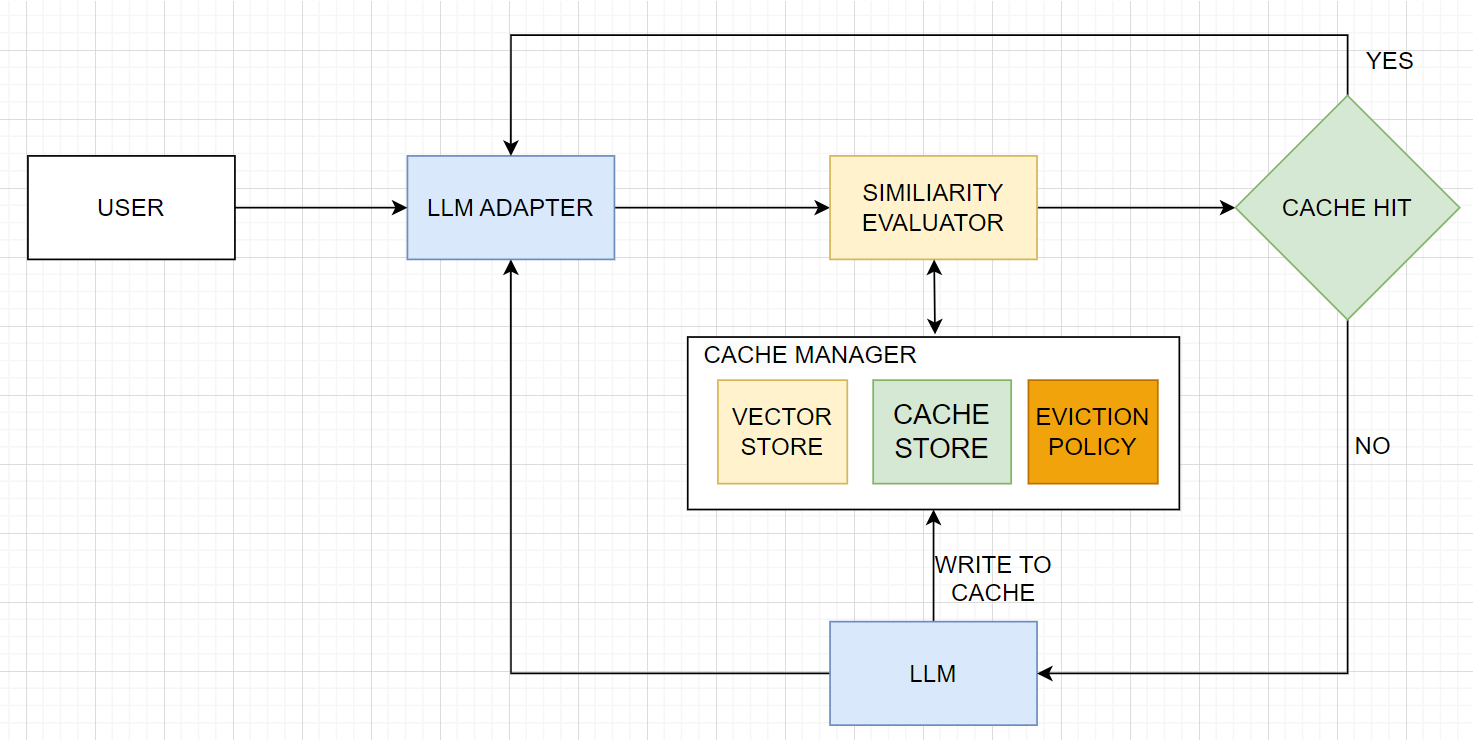\n\n\nWhen a user submits a query, the first step is to generate an embedding to enable similarity searching. GPTCache supports several methods for embedding contexts, including OpenAI, Cohere, Huggingface, ONNX, and Sentence Transformers, as well as two LLM adapters: OpenAI and Langchain. These tools convert text and potentially image or audio queries into [dense vectors](https://zilliz.com/learn/dense-vector-in-ai-maximize-data-potential-in-machine-learning). The LLM adapter allows the selection of a specific model to handle the task. \n\nGPTCache utilizes vector storage to manage and retrieve the K most similar requests based on embeddings derived from user inputs. It supports vector search libraries like FAISS and vector databases like Milvus for efficient search capabilities. For caching these responses from the LLM, GPTCache can integrate with various database options, including SQLite, MySQL, and PostgreSQL. [Milvus stands out](https://milvus.io/docs/overview.md#Why-Milvus) as a pivotal backbone for AI memory systems, particularly its ability to handle high-performance [fast vector searches](https://milvus.io/docs/multi-vector-search.md#:~:text=Since%20Milvus%202.4%2C%20we%20introduced,to%2010\\)%20into%20one%20collection.) across massive datasets, making it highly scalable and reliable. This is especially crucial for generative AI models like ChatGPT, where maintaining a responsive and dynamic memory system enhances overall performance and user interaction quality. Additionally, Milvus fosters a developer-friendly community with multi-language support, contributing to its accessibility and adaptability for various programming environments. \n\nOnce GPTCache is in place, a crucial step is to establish a method for determining if an input query matches cached answers. This is where the similarity evaluation process comes into play. The evaluation function, using user-defined parameters, compares the user's request data with the cached data to assess match suitability. If a similarity is found, indicating a cache hit, a cached response is delivered to the user. If not, the model generates a new response which is then saved in the cache store. To manage cache efficiently, GPTCache implements [eviction policies](https://www.geeksforgeeks.org/cache-eviction-policies-system-design/) like Least Recently Used (LRU) or First-In-First-Out (FIFO) to discard older or less frequently accessed data. \n\nAs you notice on the [colab notebook](https://colab.research.google.com/drive/1ezwvCPgo5uprVCVeO1U02gztJh74iu5M#scrollTo=j5UswHpYgmYT), before GPTCache, every user query is processed individually by ChatGPT, leading to higher latency, which also translates to increased operational costs due to the repetitive processing of similar questions. However, after GPTCache, when a query is received, GPTCache first checks if a similar question has been asked before. If a match is found in the cache, the stored response is used, drastically reducing response time and computational load.\n\n\n## Challenges and opportunities \n\nAccording to a paper published by [Zilliz](https://aclanthology.org/2023.nlposs-1.24.pdf), titled “GPTCache: An Open-Source Semantic Cache for LLM Applications Enabling Faster Answers and Cost Savings”, the authors argue that the effectiveness of GPTCache heavily relies on the choice of embedding model, which is critical because accurate vector retrieval depends on the quality of these embeddings. If the embeddings don't effectively capture the input text's features, they might return irrelevant cached data, affecting cache hit rates which don't typically exceed 90%. Further challenges include the limitations of current embedding models, which are optimized for search but not necessarily for caching, and the need for rigorous similarity evaluations to filter incorrect hits without drastically reducing overall cache effectiveness.\n\n \n\nTo improve cache accuracy, large models are being distilled into smaller models specialized for textual similarity, addressing issues with distinguishing between positive and negative cache hits. Additionally, large token counts in inputs pose challenges, as they may exceed the LLM's processing limits, leading to potential data loss in caching scenarios. Summary models are used to manage long texts, though this can destabilize the cache. Alternative methods such as using traditional databases for caching with textual preprocessing to standardize inputs are being explored, potentially allowing for simpler string matching or numeric range techniques to achieve cache hits.\n\n\n## Conclusion\n\nBy integrating GPTCache and Milvus with ChatGPT, businesses can create a more robust and efficient AI-powered support system. This approach leverages the advanced capabilities of generative AI and introduces a form of long-term memory, allowing the AI to recall and reuse information effectively. Such innovations underscore the transformative potential of AI in operational settings, promising substantial improvements in service quality and operational efficiency. To remain up to date with the recent advances in AI, check out more content on [Zilliz Learn](https://zilliz.com/learn) for free and the resources below.\n\n\n## Resources\n\n- [Guest Post: Enhancing ChatGPT's Efficiency – The Power of LangChain and Milvus\\*](https://thesequence.substack.com/p/guest-post-enhancing-chatgpts-efficiency)\n\n- [WebPage QA — GPTCache](https://gptcache.readthedocs.io/en/latest/bootcamp/llama_index/webpage_qa.html)\n\n- [ChatGPT+ Vector database + prompt-as-code - The CVP Stack - Zilliz blog](https://zilliz.com/blog/ChatGPT-VectorDB-Prompt-as-code)\n\n- \u003chttps://zilliz.com/blog/langchain-ultimate-guide-getting-started\u003e\n\n- [lc\\_milvus\\_test.ipynb](https://colab.research.google.com/drive/1KiPHx1wxfYylc3fqMP1hVsUB4yYtzQGn?usp=sharing#scrollTo=A8kI4j0M7H6p)\n\n- [QA Generation — GPTCache](https://gptcache.readthedocs.io/en/latest/bootcamp/langchain/qa_generation.html)\n\n- [Caching LLM Queries for performance \u0026 cost improvements - Zilliz blog](https://zilliz.com/blog/Caching-LLM-Queries-for-performance-improvements)\n\n- [SQLite Example — GPTCache](https://gptcache.readthedocs.io/en/latest/bootcamp/langchain/sqlite.html)\n\n- [Dense Vectors in AI: Maximizing Data Potential in Machine Learning](https://zilliz.com/learn/dense-vector-in-ai-maximize-data-potential-in-machine-learning)\n\n- [Multi-Vector Search Milvus documentation](https://milvus.io/docs/multi-vector-search.md#:~:text=Since%20Milvus%202.4%2C%20we%20introduced,to%2010)\n\n- [ChatGPT plugins](https://openai.com/blog/chatgpt-plugins)\n\n- [Large Language Models (LLMs)](https://zilliz.com/glossary/large-language-models-\\(llms\\))\n\n- [GitHub - zilliztech/GPTCache: Semantic cache for LLMs. Fully integrated with LangChain and llama\\_index.](https://github.com/zilliztech/GPTCache)\n \n","title":"Enhancing ChatGPT with Milvus: Powering AI with Long-Term Memory","sub_title":null,"featured":null,"abstract":"By integrating GPTCache and Milvus with ChatGPT, businesses can create a more robust and efficient AI-powered support system. This approach leverages the advanced capabilities of generative AI and introduces a form of long-term memory, allowing the AI to recall and reuse information effectively.","display_time":"Apr 08, 2024","url":"enhancing-chatgpt-with-milvus","home_order":null,"published_at":"2024-04-15T17:34:32.668Z","created_by":{"id":82,"firstname":"Sachi","lastname":"Tolani","username":null,"email":"sachi.tolani@zilliz.com","password":"$2a$10$04PodXUlJDBSdHetkhEuFe1CMUDkQGl6xxOTfiFNbyKcyvyP4HC6S","resetPasswordToken":null,"registrationToken":null,"isActive":true,"blocked":null,"preferedLanguage":null},"updated_by":{"id":21,"firstname":"jialian","lastname":"ji","username":null,"email":"jialian.ji@zilliz.com","password":"$2a$10$F38f0ylHlFDCloC6RraVluoDaJTbivl64UVbfFCav6ADbRqgZq8DC","resetPasswordToken":null,"registrationToken":null,"isActive":true,"blocked":null,"preferedLanguage":null},"created_at":"2024-04-04T17:45:13.388Z","updated_at":"2025-07-01T00:00:27.924Z","show_in_learn":true,"order_in_learn":null,"category_order":null,"category_learn":null,"author":{"id":135,"name":"Antony G.","author_tags":"Freelance Technical Writer","published_at":"2024-03-31T20:39:48.027Z","created_by":18,"updated_by":18,"created_at":"2024-03-31T20:39:30.202Z","updated_at":"2024-07-03T07:52:52.095Z","home_page":null,"home_page_link":null,"self_intro":null,"repost_to_medium":null,"repost_state":null,"meta_description":"Antony G., Freelance Technical Writer","locale":"en","avatar":{"id":3006,"name":"Male-Author.jpeg","alternativeText":"","caption":"","width":1024,"height":1024,"formats":{"large":{"ext":".jpeg","url":"https://assets.zilliz.com/large_Male_Author_526de0f08d.jpeg","hash":"large_Male_Author_526de0f08d","mime":"image/jpeg","name":"large_Male-Author.jpeg","path":null,"size":92.42,"width":1000,"height":1000},"small":{"ext":".jpeg","url":"https://assets.zilliz.com/small_Male_Author_526de0f08d.jpeg","hash":"small_Male_Author_526de0f08d","mime":"image/jpeg","name":"small_Male-Author.jpeg","path":null,"size":35.2,"width":500,"height":500},"medium":{"ext":".jpeg","url":"https://assets.zilliz.com/medium_Male_Author_526de0f08d.jpeg","hash":"medium_Male_Author_526de0f08d","mime":"image/jpeg","name":"medium_Male-Author.jpeg","path":null,"size":61.68,"width":750,"height":750},"thumbnail":{"ext":".jpeg","url":"https://assets.zilliz.com/thumbnail_Male_Author_526de0f08d.jpeg","hash":"thumbnail_Male_Author_526de0f08d","mime":"image/jpeg","name":"thumbnail_Male-Author.jpeg","path":null,"size":6.72,"width":156,"height":156}},"hash":"Male_Author_526de0f08d","ext":".jpeg","mime":"image/jpeg","size":94.23,"url":"https://assets.zilliz.com/Male_Author_526de0f08d.jpeg","previewUrl":null,"provider":"s3","provider_metadata":null,"created_by":55,"updated_by":55,"created_at":"2024-04-01T18:17:10.227Z","updated_at":"2024-04-01T18:17:21.142Z"}},"canonical_rel":"","repost_to_medium":true,"repost_state":{"status":"success","mediumId":"9d3810961c3b","mediumUrl":"https://medium.com/@zilliz_learn/enhancing-chatgpt-with-milvus-powering-ai-with-long-term-memory-9d3810961c3b"},"meta_title":"Enhancing ChatGPT with Milvus: Powering AI with Long-Term Memory","meta_description":"By integrating GPTCache and Milvus with ChatGPT, businesses can create a more robust and efficient AI-powered support system. This approach leverages the advanced capabilities of generative AI and introduces a form of long-term memory, allowing the AI to recall and reuse information effectively.","meta_keywords":null,"invisible":false,"locale":"en","repost_to_devto":null,"image":{"id":3025,"name":"Enhancing ChatGPT with Milvus.png","alternativeText":"","caption":"","width":2400,"height":1256,"formats":{"large":{"ext":".png","url":"https://assets.zilliz.com/large_Enhancing_Chat_GPT_with_Milvus_099d0488f7.png","hash":"large_Enhancing_Chat_GPT_with_Milvus_099d0488f7","mime":"image/png","name":"large_Enhancing ChatGPT with Milvus.png","path":null,"size":494.2,"width":1000,"height":523},"small":{"ext":".png","url":"https://assets.zilliz.com/small_Enhancing_Chat_GPT_with_Milvus_099d0488f7.png","hash":"small_Enhancing_Chat_GPT_with_Milvus_099d0488f7","mime":"image/png","name":"small_Enhancing ChatGPT with Milvus.png","path":null,"size":133.09,"width":500,"height":262},"medium":{"ext":".png","url":"https://assets.zilliz.com/medium_Enhancing_Chat_GPT_with_Milvus_099d0488f7.png","hash":"medium_Enhancing_Chat_GPT_with_Milvus_099d0488f7","mime":"image/png","name":"medium_Enhancing ChatGPT with Milvus.png","path":null,"size":274.01,"width":750,"height":393},"thumbnail":{"ext":".png","url":"https://assets.zilliz.com/thumbnail_Enhancing_Chat_GPT_with_Milvus_099d0488f7.png","hash":"thumbnail_Enhancing_Chat_GPT_with_Milvus_099d0488f7","mime":"image/png","name":"thumbnail_Enhancing ChatGPT with Milvus.png","path":null,"size":44.74,"width":245,"height":128}},"hash":"Enhancing_Chat_GPT_with_Milvus_099d0488f7","ext":".png","mime":"image/png","size":2371.83,"url":"https://assets.zilliz.com/Enhancing_Chat_GPT_with_Milvus_099d0488f7.png","previewUrl":null,"provider":"s3","provider_metadata":null,"created_by":82,"updated_by":82,"created_at":"2024-04-04T17:43:32.809Z","updated_at":"2024-04-04T17:43:32.824Z"},"tags":[{"id":5,"name":"Engineering","published_at":"2021-01-21T02:28:39.896Z","created_by":18,"updated_by":18,"created_at":"2021-01-21T02:28:37.242Z","updated_at":"2022-11-15T19:16:38.988Z","locale":"en"}],"authors":[{"id":135,"name":"Antony G.","author_tags":"Freelance Technical Writer","published_at":"2024-03-31T20:39:48.027Z","created_by":18,"updated_by":18,"created_at":"2024-03-31T20:39:30.202Z","updated_at":"2024-07-03T07:52:52.095Z","home_page":null,"home_page_link":null,"self_intro":null,"repost_to_medium":null,"repost_state":null,"meta_description":"Antony G., Freelance Technical Writer","locale":"en","avatar":{"id":3006,"name":"Male-Author.jpeg","alternativeText":"","caption":"","width":1024,"height":1024,"formats":{"large":{"ext":".jpeg","url":"https://assets.zilliz.com/large_Male_Author_526de0f08d.jpeg","hash":"large_Male_Author_526de0f08d","mime":"image/jpeg","name":"large_Male-Author.jpeg","path":null,"size":92.42,"width":1000,"height":1000},"small":{"ext":".jpeg","url":"https://assets.zilliz.com/small_Male_Author_526de0f08d.jpeg","hash":"small_Male_Author_526de0f08d","mime":"image/jpeg","name":"small_Male-Author.jpeg","path":null,"size":35.2,"width":500,"height":500},"medium":{"ext":".jpeg","url":"https://assets.zilliz.com/medium_Male_Author_526de0f08d.jpeg","hash":"medium_Male_Author_526de0f08d","mime":"image/jpeg","name":"medium_Male-Author.jpeg","path":null,"size":61.68,"width":750,"height":750},"thumbnail":{"ext":".jpeg","url":"https://assets.zilliz.com/thumbnail_Male_Author_526de0f08d.jpeg","hash":"thumbnail_Male_Author_526de0f08d","mime":"image/jpeg","name":"thumbnail_Male-Author.jpeg","path":null,"size":6.72,"width":156,"height":156}},"hash":"Male_Author_526de0f08d","ext":".jpeg","mime":"image/jpeg","size":94.23,"url":"https://assets.zilliz.com/Male_Author_526de0f08d.jpeg","previewUrl":null,"provider":"s3","provider_metadata":null,"created_by":55,"updated_by":55,"created_at":"2024-04-01T18:17:10.227Z","updated_at":"2024-04-01T18:17:21.142Z"}}],"localizations":[{"id":422,"locale":"ja-JP","published_at":"2024-04-15T17:34:32.668Z"}],"read_time":5,"display_updated_time":"Jul 01, 2025","backgroundImage":"https://assets.zilliz.com/large_Enhancing_Chat_GPT_with_Milvus_099d0488f7.png","belong":"learn","authorNames":["Antony G."]},{"id":"learn-505","content":"Retrieval Augmented Generation (RAG) empowers Large Language Models (LLMs) to provide domain-specific and contextually accurate answers by leveraging additional information to generate responses. Due to the benefits offered by RAG, more and more companies are incorporating it to build their AI applications. However, only a few can bring these applications to reality, as the biggest hurdle they face is successfully evaluating them. We’ve all seen it before, such as lawyers submitting false information generated by AI, which highlights the potential dangers of AI and suggests that, in certain situations, its risks may outweigh its benefits.\n\nPerforming RAG evaluation is, therefore, crucial to prevent hallucinations, irrelevant and biased responses, and generate trustworthy answers. As a result, to streamline debugging and improve reliability and performance for real-world LLM applications, using RAG evaluation tools is super important. In this blog, we will explore the top 10 RAG evaluation tools that you don’t want to miss looking at to make your next RAG project robust. \n\nLet’s get started. \n\n\n\u003ciframe style=\"border-radius:12px\" src=\"https://open.spotify.com/embed/episode/48lwnRwOMuXWCJY6ZePXwM?utm_source=generator\" width=\"100%\" height=\"152\" frameBorder=\"0\" allowfullscreen=\"\" allow=\"autoplay; clipboard-write; encrypted-media; fullscreen; picture-in-picture\" loading=\"lazy\"\u003e\u003c/iframe\u003e\n\n\n## Popular RAG \u0026 LLM Evaluation Tools \n\n### RAGAS \n\n[RAGAS](https://docs.ragas.io/en/stable/) is an easy-to-use yet comprehensive RAG evaluation tool offering capabilities such as integrations with frameworks like [LlamaIndex](https://zilliz.com/product/integrations/Llamaindex) and Arize Phoenix, synthesizing your custom test datasets for evaluation, and access to several metrics for quality assurance. \n\n\n#### Key Capabilities\n\n- Offers metrics such as context precision, context recall, faithfulness, response relevancy, and noise sensitivity. \n\n- Provides integrations with tracing tools such as LangSmith and [Arize Phoenix](https://zilliz.com/product/integrations/arize-phoneix) for observability and debugging. \n\n- Access to feedback from production data to discover patterns and assist in continual improvement. \n\n- Provides in-house evaluation samples and datasets for your specific use cases. \n\nYou can learn more about Raga from this blog on [RAG Evaluation Using Ragas](https://zilliz.com/blog/rag-evaluation-using-ragas).\n\n\n### DeepEval \n\n[DeepEval](https://docs.confident-ai.com/docs/getting-started) is an open-source LLM evaluation framework offering tests for LLM outputs similar to unit tests for traditional software. Confident AI, the cloud platform of [DeepEval](https://zilliz.com/product/integrations/deepeval), allows teams to perform regression testing, red teaming, and monitoring of LLM applications on the cloud.\n\n\n#### Key Capabilities \n\n- Offers metrics such as G-Eval, common RAG metrics, and conversational metrics such as knowledge retention, conversation completeness, and role adherence. \n\n- Allows easy code integrations for benchmarking on popular LLM benchmarks like MMLU, DROP, and many others. \n\n- Provides 40+ vulnerability testing attacks to check the resilience of LLMs against prompt injection attacks. \n\n- Supports integrations with LlamaIndex to perform unit testing of RAG applications in CI/CD and HuggingFace to conduct real-time evaluations during finetuning. \n\n\n### TruLens\n\n[TruLens](https://www.trulens.org/) is a proprietary tool for enterprises to evaluate RAG. With features such as feedback functions, easy iterations, and the ability to get started simply with a few lines of code, TruLens can work with any LLM-based application. \n\n\n#### Key Capabilities\n\n- Offers integrations with LangChain, LlamaIndex, and Nvidia NeMo guardrails. \n\n- Helps with model versioning to keep track of which LLM apps are performing best based on a variety of evaluation metrics. \n\n- It is developer-friendly as the library can be installed from PyPI and it requires only a few lines of code to set up. \n\n- Provides feedback functions to programmatically evaluate inputs, outputs, or intermediate results to check for metrics such as groundedness, context, and safety. \n\n- Ability to conduct multiple iterations to observe where apps have weaknesses and decide iterations on prompts, hyperparams, etc. \n\nCheck out this [blog](https://zilliz.com/blog/evaluations-for-retrieval-augmented-generation-trulens-milvus) to learn more about TruLens\n\n\n### LangSmith \n\n[LangSmith](https://www.langchain.com/langsmith) is an all-in-one lifecycle platform for debugging, collaborating on, testing, monitoring, and bringing your LLM application from prototype to production. Its evaluations such as offline evaluation, continuous evaluation, and AI judge evaluation ensure error testing for all stages of the product. \n\n\n#### Key Capabilities \n\n- Allows easy sharing of observability chain traces with anybody through a link. \n\n- LangSmith hub to craft, keep versions and comment on prompts. \n\n- Enables custom dataset collection for evaluation using production data or other existing sources. \n\n- Ability to integrate human review along with auto evals to test on reference LangSmith datasets during offline evaluation. \n\n- Offers continuous evaluation, regression testing, gold standard evaluation, and ability to create custom tests for comprehensive evaluation. \n\n\n### LangFuse \n\n[LangFuse](https://langfuse.com/) is an open-source LLM engineering platform that can be run locally or self-hosted. It provides traces, evals, prompt management, and metrics to debug and improve LLM applications. Its extensive integrations make it easy to work with any LLM app or model. \n\n\n#### Key Capabilities\n\n- Provides best-in-class Python SDKs and native integrations for popular libraries or frameworks such as OpenAI, LlamaIndex, Amazon Bedrock, and DeepSeek.\n\n- Helps compare latency, cost, and evaluation metrics across different versions of prompts. \n\n- Streamlines evaluation with an analytics dashboard, user feedback, LLM as a judge, and human annotators in the loop. Also, offers integration with external evaluation pipelines. \n\n- It is production-optimized and supports multi-modal data as well. \n\n- Offers enterprise security as Langfuse cloud is SOC 2 Type II and GDPR compliant. \n\n\n### LlamaIndex \n\n[LlamaIndex](https://docs.llamaindex.ai/en/stable/optimizing/evaluation/evaluation/) is an end-to-end tooling framework for building agentic workflows, developing and deploying full-stack apps, and LLM evaluation. It presents two kinds of evaluation modules - one for retrieval quality and the other for response quality. \n\n\n#### Key Capabilities \n\n- Offers LLM evaluation modules to check for correctness, semantic similarity, faithfulness, context relevancy, and guideline adherence. \n\n- Enables creating custom question-context pairs as a test set to validate the relevancy of responses. \n\n- Provides ranking metrics such as MRR, hit rate, and precision to evaluate retrieval quality. \n\n- Integrates well with community evaluation tools such as Up Train, DeepEval, RAGAS, and RAGChecker. \n\n- Offers batch evaluation to compute multiple evaluations in a batch-wise manner. \n\n\n### Arize Phoenix \n\n[Arize Phoenix](https://docs.arize.com/phoenix/evaluation/llm-evals) allows seamless evaluation, experimentation, and optimization of AI applications to work in real-time. It is an open source tool for AI observability and evaluation which supports pre-tested and custom evaluation templates. \n\n\n#### Key Capabilities \n\n- Works with all LLM tools and apps as it is agnostic of vendor, framework, and language. \n\n- Offers interactive prompt playground and streamlined evaluations and annotations.\n\n- Provides dataset clustering and visualization features to uncover semantically similar questions, document chunks, and responses helping isolate poor performance. \n\n- Phoenix evals run super fast to maximize the throughput of the API key hence it is suitable for real-time evaluations. \n\n\n### Traceloop \n\n[Traceloop](https://www.traceloop.com/) is an open-source LLM evaluation framework as part of OpenLLMetry focussing on tracing origins and flow of information throughout the retrieval and generation processes. \n\n\n#### Key Capabilities \n\n- Monitors output quality by backtesting changes and sends real-time alerts about unexpected patterns in the responses. \n\n- Assists with debugging prompts and agents by suggesting possible performance improvements.\n\n- Automatically roll out changes gradually to help with debugging. \n\n- Either you can work with OpenLLMetry SDK or use Traceloop Hub as a smart proxy for your LLM calls. \n\n\n### Galileo \n\n[Galileo](https://www.galileo.ai/) is a proprietary tool for the evaluation, real-time monitoring, and rapid debugging of AI applications at enterprise scale. It is ideal for businesses seeking scalable AI tools, auto-adaptive metrics, extensive integrations, and deployment flexibility. \n\n\n#### Key Capabilities \n\n- Provides research-backed metrics that automatically improve based on usage and feedback over time. \n\n- Handles production grade throughput which can scale to millions of rows. \n\n- Supports offline testing and experimentation with model and prompt playground and A/B testing. \n\n- Offers storing, versioning, tracking, and visualization of prompts.\n\n- Protects AI applications from unwanted behaviors in real time using techniques such as saved rulesets, prompt injection prevention, and harmful response prevention. \n\n\n### OpenAI Evals \n\n[OpenAI Evals](https://platform.openai.com/docs/guides/evals) is an open-source framework designed to assess and benchmark the performance of LLMs. By using predefined and custom evaluation sets, OpenAI Evals helps teams identify weaknesses and improve them for better performance. \n\n\n#### Key Capabilities \n\n- Allows generating a test dataset for evaluation either from existing sources, real production usage or by importing stored chat completions. \n\n- Provides testing criteria for LLM responses such as factuality, sentiment check, criteria match, text quality, or designing your custom prompt.\n\n- Also, supports private evals that can represent common LLM patterns in your workflow without exposing any of that data to the public. \n\n- Can use any OpenAI model for building workflows and evaluating them. \n\n- Offers finetuning and model distillation capabilities for further improving models. \n\n\n## How to Choose the Right Evaluation Tool for You? \n\n| | | | | |\n| :--------------------------------------------------------------: | :-----------: | :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: | :-----------------------------------------------------------------------------------------: | :----------------------------------------------------: |\n| Use Case | Framework | Key Capabilities | Key Metrics | Open Source / Commercial |\n| Easy to use and comprehensive RAG evaluation tool | RAGAS | Integrates with LlamaIndex, Arize Phoenix, and LangSmith for observability and debugging. Provides in-house evaluation datasets. | Context Precision, Context Recall, Faithfulness, Response Relevancy, Noise Sensitivity | Open Source |\n| Red teaming and unit tests for LLMs | DeepEval | Provides 40+ vulnerability tests for prompt injection resilience. Enables benchmarking on datasets like MMLU and DROP. | G-Eval, Common RAG Metrics, Knowledge Retention, Conversation Completeness, Role Adherence | Open Source (DeepEval), Commercial (Confident AI) |\n| Developer-friendly RAG evaluation with iterative testing | TruLens | Supports model versioning for performance tracking. Provides feedback functions for evaluating groundedness, context, and safety. | Groundedness, Context, Safety | Commercial |\n| All-in-one LLM lifecycle platform | LangSmith | Provides observability with easy sharing of chain traces. Supports offline, continuous, and AI judge evaluations. | Regression Testing, Gold Standard Evaluation, Custom Test Metrics | Commercial |\n| Self-hosted LLM engineering platform with extensive integrations | LangFuse | Provides Python SDKs and integrations with OpenAI, LlamaIndex, Amazon Bedrock, DeepSeek, and many others. Supports multi-modal data and external evaluation pipelines along with security compliance. | Latency, Cost Analysis, LLM-as-a-Judge, Human Evaluation | Open Source (Self-Hosted), Commercial (LangFuse Cloud) |\n| End-to-end framework for LLM evaluation and workflow development | LlamaIndex | Integrates with community tools like UpTrain, DeepEval, RAGAS, and RAGChecker. Supports batch evaluation for multiple evaluations. | Correctness, Semantic Similarity, Faithfulness, Context Relevancy, MRR, Hit Rate, Precision | Open Source |\n| Real-time LLM evaluation and observability | Arize Phoenix | Works with all LLM tools and apps, agnostic to vendor, framework, and language. Provides dataset clustering and visualization to identify poor performance. | Relevance, Hallucinations, Question-answering accuracy, Toxicity | Open Source |\n| LLM debugging and monitoring with real-time alerts | Traceloop | Monitors output quality by backtesting changes and sending real-time alerts on unexpected patterns. Integrates with OpenLLMetry SDK or uses Traceloop Hub as a smart proxy for LLM calls. | Latency, Throughput, Error rate, Token usage, Hallucination, Regression | Open Source |\n| Enterprise-scale AI evaluation real-time monitoring | Galileo | Provides auto-adaptive research-backed metrics that improve with usage and feedback. Scales to handle production-grade throughput with millions of rows. | Toxicity, PII, Context adherence, Correctness, Custom metrics | Commercial |\n| LLM performance benchmarking and improvement | OpenAI Evals | Generates test datasets from existing sources, real production usage, or stored chat completions. Includes finetuning and model distillation for model improvements. | Factuality, Sentiment, Text quality, Custom tests | Open Source |\n\n\n## Real-World Tips for Choosing the Right Evaluation Tool \n\n- **Understand Business Needs** - Define the primary goals - whether it's improving model accuracy, reducing costs, enhancing user experience, or scaling operations. Choose a tool that directly supports these objectives.\n\n- **Customization for Specific Use Cases** - Look for tools that allow customization to your domain or product requirements (e.g., integrating domain-specific metrics, using proprietary data, or working with your current LLM frameworks).\n\n- **Scalability** - If your business aims to scale, choose a tool that handles large data volumes, provides fast evaluations, and integrates with cloud infrastructure for efficient scaling.\n\n- **Cost-Effectiveness** - Ensure the tool aligns with your budget. Some tools may have a high upfront cost but can save long-term operational costs by optimizing the evaluation process.\n\n- **Ease of Integration** - Pick tools that integrate seamlessly with your existing workflows, whether in CI/CD pipelines or production environments, without requiring a major overhaul.\n\n- **Real-Time Insights** - If real-time monitoring and quick feedback are crucial to your business, choose tools that support fast, on-the-fly evaluations to enable rapid iteration.\n","title":"Top 10 RAG \u0026 LLM Evaluation Tools You Don't Want To Miss","sub_title":null,"featured":null,"abstract":"Discover the best RAG evaluation tools to improve AI app reliability, prevent hallucinations, and boost performance across different frameworks.\n","display_time":"Mar 05, 2025","url":"top-ten-rag-and-llm-evaluation-tools-you-dont-want-to-miss","home_order":null,"published_at":"2025-03-26T00:10:23.093Z","created_by":{"id":82,"firstname":"Sachi","lastname":"Tolani","username":null,"email":"sachi.tolani@zilliz.com","password":"$2a$10$04PodXUlJDBSdHetkhEuFe1CMUDkQGl6xxOTfiFNbyKcyvyP4HC6S","resetPasswordToken":null,"registrationToken":null,"isActive":true,"blocked":null,"preferedLanguage":null},"updated_by":{"id":125,"firstname":"Fields","lastname":"Zhang","username":null,"email":"fields.zhang@zilliz.com","password":"$2a$10$7a9uDs/Uvueu62ewpcFPG.DG0nBtxjiYO34WN67Wj7hWQVwQVQiJa","resetPasswordToken":null,"registrationToken":null,"isActive":true,"blocked":null,"preferedLanguage":null},"created_at":"2025-03-26T00:10:20.639Z","updated_at":"2025-04-07T03:41:27.773Z","show_in_learn":true,"order_in_learn":null,"category_order":null,"category_learn":null,"author":null,"canonical_rel":"https://zilliz.com/learn/top-ten-rag-and-llm-evaluation-tools-you-dont-want-to-miss","repost_to_medium":true,"repost_state":{"devto":{"status":"success"},"medium":{"status":"success","id":"a0bfabe9ae19","url":"https://medium.com/@zilliz_learn/top-10-rag-llm-evaluation-tools-you-dont-want-to-miss-a0bfabe9ae19"}},"meta_title":"Top 10 RAG \u0026 LLM Evaluation Tools for AI Success","meta_description":"Discover the best RAG evaluation tools to improve AI app reliability, prevent hallucinations, and boost performance across different frameworks.\n","meta_keywords":"RAG Evaluation, LLMs, Machine Learning, Generative AI, AI Performance","invisible":false,"locale":"en","repost_to_devto":true,"image":{"id":6299,"name":"Top 10 RAG \u0026 LLM Evaluation Tools You Don't Want to Miss.png","alternativeText":"","caption":"","width":1201,"height":628,"formats":{"large":{"ext":".png","url":"https://assets.zilliz.com/large_Top_10_RAG_and_LLM_Evaluation_Tools_You_Don_t_Want_to_Miss_cb3936dbfe.png","hash":"large_Top_10_RAG_and_LLM_Evaluation_Tools_You_Don_t_Want_to_Miss_cb3936dbfe","mime":"image/png","name":"large_Top 10 RAG \u0026 LLM Evaluation Tools You Don't Want to Miss.png","path":null,"size":724.68,"width":1000,"height":523},"small":{"ext":".png","url":"https://assets.zilliz.com/small_Top_10_RAG_and_LLM_Evaluation_Tools_You_Don_t_Want_to_Miss_cb3936dbfe.png","hash":"small_Top_10_RAG_and_LLM_Evaluation_Tools_You_Don_t_Want_to_Miss_cb3936dbfe","mime":"image/png","name":"small_Top 10 RAG \u0026 LLM Evaluation Tools You Don't Want to Miss.png","path":null,"size":153.12,"width":500,"height":261},"medium":{"ext":".png","url":"https://assets.zilliz.com/medium_Top_10_RAG_and_LLM_Evaluation_Tools_You_Don_t_Want_to_Miss_cb3936dbfe.png","hash":"medium_Top_10_RAG_and_LLM_Evaluation_Tools_You_Don_t_Want_to_Miss_cb3936dbfe","mime":"image/png","name":"medium_Top 10 RAG \u0026 LLM Evaluation Tools You Don't Want to Miss.png","path":null,"size":376.49,"width":750,"height":392},"thumbnail":{"ext":".png","url":"https://assets.zilliz.com/thumbnail_Top_10_RAG_and_LLM_Evaluation_Tools_You_Don_t_Want_to_Miss_cb3936dbfe.png","hash":"thumbnail_Top_10_RAG_and_LLM_Evaluation_Tools_You_Don_t_Want_to_Miss_cb3936dbfe","mime":"image/png","name":"thumbnail_Top 10 RAG \u0026 LLM Evaluation Tools You Don't Want to Miss.png","path":null,"size":43.94,"width":245,"height":128}},"hash":"Top_10_RAG_and_LLM_Evaluation_Tools_You_Don_t_Want_to_Miss_cb3936dbfe","ext":".png","mime":"image/png","size":685.73,"url":"https://assets.zilliz.com/Top_10_RAG_and_LLM_Evaluation_Tools_You_Don_t_Want_to_Miss_cb3936dbfe.png","previewUrl":null,"provider":"s3","provider_metadata":null,"created_by":82,"updated_by":82,"created_at":"2025-03-26T00:07:45.254Z","updated_at":"2025-03-26T00:07:45.276Z"},"tags":[{"id":72,"name":"Community","published_at":"2024-07-10T06:22:15.647Z","created_by":18,"updated_by":18,"created_at":"2024-07-10T06:22:04.204Z","updated_at":"2024-07-10T06:22:15.658Z","locale":"en"}],"authors":[{"id":170,"name":"Yesha Shastri","author_tags":"Freelance Technical Writer in AI/ML","published_at":"2024-07-29T08:44:59.761Z","created_by":18,"updated_by":18,"created_at":"2024-07-29T08:44:38.291Z","updated_at":"2024-07-29T08:44:59.820Z","home_page":"LinkedIn","home_page_link":"https://www.linkedin.com/in/yeshashastri/","self_intro":"Yesha Shastri, Freelance Technical Writer in AI/ML","repost_to_medium":null,"repost_state":null,"meta_description":"Yesha Shastri, Freelance Technical Writer","locale":"en","avatar":{"id":2996,"name":"DALL·E 2024-04-01 09.34.43 - Create a colorful yet elegant avatar for a girl writer, presenting a faceless headshot silhouette with feminine features like long, styled hair. The b.webp","alternativeText":"","caption":"","width":1024,"height":1024,"formats":{"large":{"ext":".webp","url":"https://assets.zilliz.com/large_DALL_E_2024_04_01_09_34_43_Create_a_colorful_yet_elegant_avatar_for_a_girl_writer_presenting_a_faceless_headshot_silhouette_with_feminine_features_like_long_styled_hair_The_b_3ade83fffc.webp","hash":"large_DALL_E_2024_04_01_09_34_43_Create_a_colorful_yet_elegant_avatar_for_a_girl_writer_presenting_a_faceless_headshot_silhouette_with_feminine_features_like_long_styled_hair_The_b_3ade83fffc","mime":"image/webp","name":"large_DALL·E 2024-04-01 09.34.43 - Create a colorful yet elegant avatar for a girl writer, presenting a faceless headshot silhouette with feminine features like long, styled hair. The b.webp","path":null,"size":34.53,"width":1000,"height":1000},"small":{"ext":".webp","url":"https://assets.zilliz.com/small_DALL_E_2024_04_01_09_34_43_Create_a_colorful_yet_elegant_avatar_for_a_girl_writer_presenting_a_faceless_headshot_silhouette_with_feminine_features_like_long_styled_hair_The_b_3ade83fffc.webp","hash":"small_DALL_E_2024_04_01_09_34_43_Create_a_colorful_yet_elegant_avatar_for_a_girl_writer_presenting_a_faceless_headshot_silhouette_with_feminine_features_like_long_styled_hair_The_b_3ade83fffc","mime":"image/webp","name":"small_DALL·E 2024-04-01 09.34.43 - Create a colorful yet elegant avatar for a girl writer, presenting a faceless headshot silhouette with feminine features like long, styled hair. The b.webp","path":null,"size":15.34,"width":500,"height":500},"medium":{"ext":".webp","url":"https://assets.zilliz.com/medium_DALL_E_2024_04_01_09_34_43_Create_a_colorful_yet_elegant_avatar_for_a_girl_writer_presenting_a_faceless_headshot_silhouette_with_feminine_features_like_long_styled_hair_The_b_3ade83fffc.webp","hash":"medium_DALL_E_2024_04_01_09_34_43_Create_a_colorful_yet_elegant_avatar_for_a_girl_writer_presenting_a_faceless_headshot_silhouette_with_feminine_features_like_long_styled_hair_The_b_3ade83fffc","mime":"image/webp","name":"medium_DALL·E 2024-04-01 09.34.43 - Create a colorful yet elegant avatar for a girl writer, presenting a faceless headshot silhouette with feminine features like long, styled hair. The b.webp","path":null,"size":24.91,"width":750,"height":750},"thumbnail":{"ext":".webp","url":"https://assets.zilliz.com/thumbnail_DALL_E_2024_04_01_09_34_43_Create_a_colorful_yet_elegant_avatar_for_a_girl_writer_presenting_a_faceless_headshot_silhouette_with_feminine_features_like_long_styled_hair_The_b_3ade83fffc.webp","hash":"thumbnail_DALL_E_2024_04_01_09_34_43_Create_a_colorful_yet_elegant_avatar_for_a_girl_writer_presenting_a_faceless_headshot_silhouette_with_feminine_features_like_long_styled_hair_The_b_3ade83fffc","mime":"image/webp","name":"thumbnail_DALL·E 2024-04-01 09.34.43 - Create a colorful yet elegant avatar for a girl writer, presenting a faceless headshot silhouette with feminine features like long, styled hair. The b.webp","path":null,"size":3.53,"width":156,"height":156}},"hash":"DALL_E_2024_04_01_09_34_43_Create_a_colorful_yet_elegant_avatar_for_a_girl_writer_presenting_a_faceless_headshot_silhouette_with_feminine_features_like_long_styled_hair_The_b_3ade83fffc","ext":".webp","mime":"image/webp","size":36.96,"url":"https://assets.zilliz.com/DALL_E_2024_04_01_09_34_43_Create_a_colorful_yet_elegant_avatar_for_a_girl_writer_presenting_a_faceless_headshot_silhouette_with_feminine_features_like_long_styled_hair_The_b_3ade83fffc.webp","previewUrl":null,"provider":"s3","provider_metadata":null,"created_by":60,"updated_by":60,"created_at":"2024-04-01T01:35:02.588Z","updated_at":"2024-04-01T01:35:02.617Z"}}],"localizations":[],"read_time":9,"display_updated_time":"Apr 07, 2025","backgroundImage":"https://assets.zilliz.com/large_Top_10_RAG_and_LLM_Evaluation_Tools_You_Don_t_Want_to_Miss_cb3936dbfe.png","belong":"learn","authorNames":["Yesha Shastri"]}]},"__N_SSG":true},"page":"/learn/[id]","query":{"id":"guide-to-chunking-strategies-for-rag"},"buildId":"jZQUVXSOCcaFSI1MpPnBS","isFallback":false,"gsp":true,"scriptLoader":[]}</script></body></html>